在数据中找到信号
此示例显示了如何使用findsignal在你的数据中找到一个时变信号。它包括如何使用距离度量找到精确和紧密匹配的信号,如何补偿缓慢变化的偏移量,以及使用动态时间扭曲允许采样变化的例子。
找到完全匹配
当你想找到的时候数值精确匹配信号,您可以使用strfind.来进行匹配。
例如,如果我们有一个数据向量:
数据= [1 4 3 2 55 2 3 11 5 2 55 2 3 1 6 4 2 55 2 3 1 6 4 2];
我们希望找到信号的位置:
信号= [55 2 3 1];
我们可以用strfind.只要信号和数据在数值上是精确的,找出信号在数据中存在的起始指数。
iStart = strfind(数据、信号)
istart =.1×3.5 11日18
找到最接近的匹配信号
strfind.适用于数值精确匹配。然而,当信号中可能存在量化噪声或其他伪影导致的错误时,这种方法就失败了。
例如,如果您有Sinusoid:
DATA = SIN(2 * PI *(0:25)/ 16);
并且您想找到信号的位置:
信号= COS(2 * PI *(0:10)/ 16);
strfind.无法在从第五个样本开始的数据中找到正弦信号:
iStart = strfind(数据、信号)
iStart = []
strfind.由于舍入误差,并不是所有的值在数值上都相等,因此无法在数据中找到信号。要看到这一点,从匹配区域的信号减去数据。
数据(5:15)信号
ans =1×1110.-15年×0 0 0 0.0555 0.0555 0 0.2220 0 0.2220 0
在1e-15的数量级上存在数字差异。
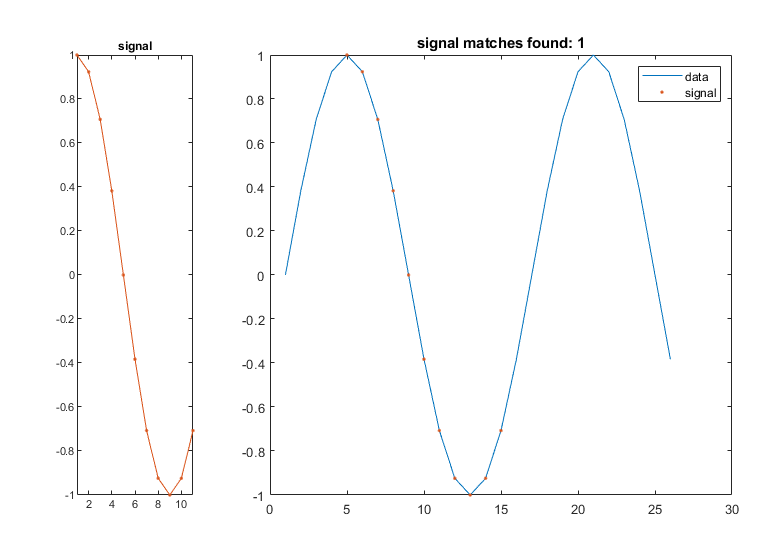
要解决这个问题,可以使用findsignal,默认情况下,默认横跨数据扫描信号,并计算在每个位置本地的信号和数据之间的平方差的和,查找最低和。
要生成显示最佳匹配位置的信号和数据图,可以调用findsignal如下:
findsignal(数据,信号)
在阈值下找到最接近的匹配
默认findsignal始终返回与数据的最接近的匹配。要返回多个匹配项,您可以指定最大和平方差的绑定。
数据= SIN(2 * PI *(0:100)/ 16);信号= COS(2 * PI *(0:10)/ 16);findsignal(数据,信号,'maxdistance',1E-14)
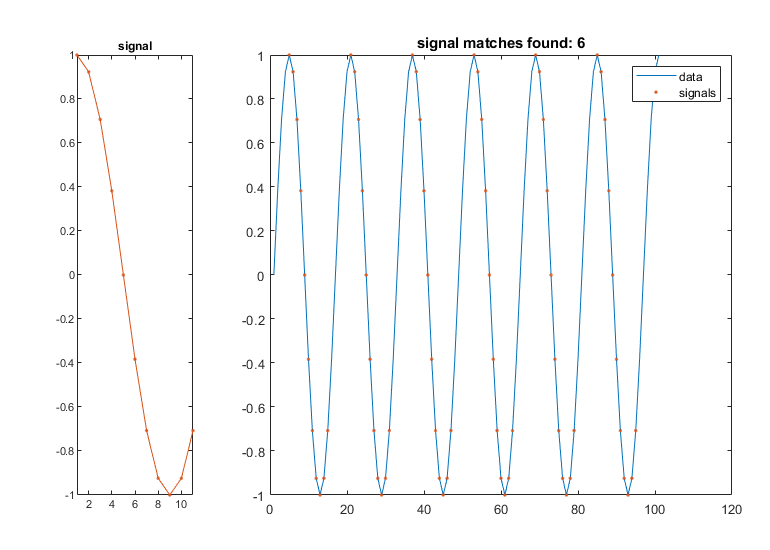
findsignal返回次数的排序顺序匹配
[iStart, iStop, distance] = findsignal(数据,信号,距离)'maxdistance'1 e-14);fprintf('iStart iStop总距离的平方\n')
它等于总距离的平方
fprintf('%4i%5i%.7g \ n', (iStart;iStop;距离)
53 63 0 69 79 0 85 95 0 5 15 1.776357e-15 21 31 1.776357e-15 37 47 1.776357e-15
变偏置复杂信号轨迹的搜索
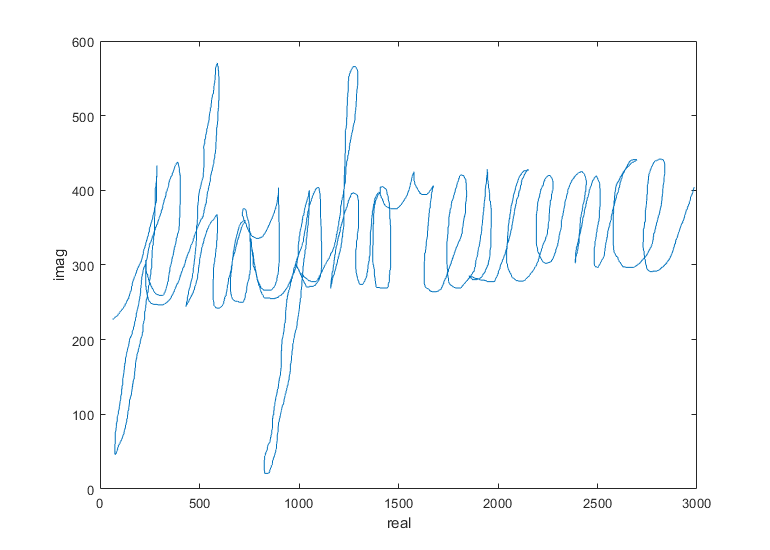
下一个例子展示了如何使用findsignal找到追踪已知轨迹的信号。文件“cursiveex.mat”包含笔尖的X和Y位置的记录,因为它在一张纸上追踪“磷光”一词。x,y数据分别被编码为复杂信号的实数和虚部。
加载CursiveEx.情节(数据)包含(“真实”的) ylabel (图像放大的)
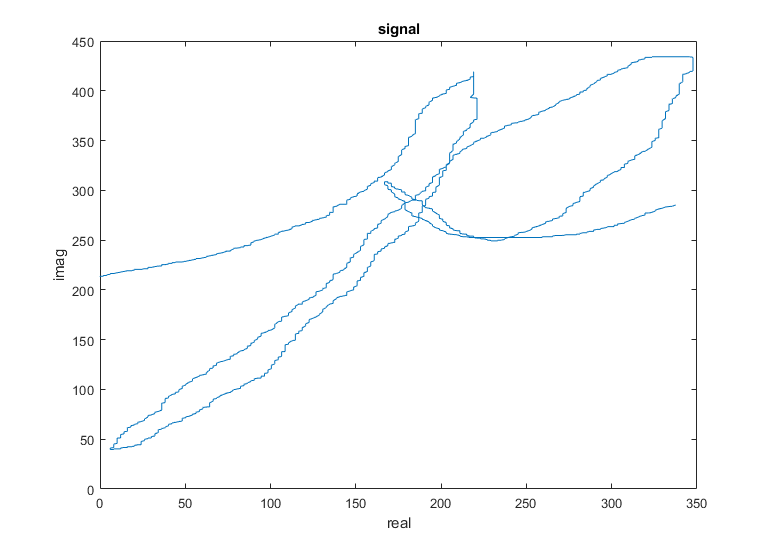
与模板信号相同的作者将字母“p”追踪。
情节(信号)标题(“信号”)包含(“真实”的) ylabel (图像放大的)
您可以很容易地找到数据中的第一个“p”findsignal。这是因为信号值在数据开始时排列得相当好。
findsignal(数据,信号)
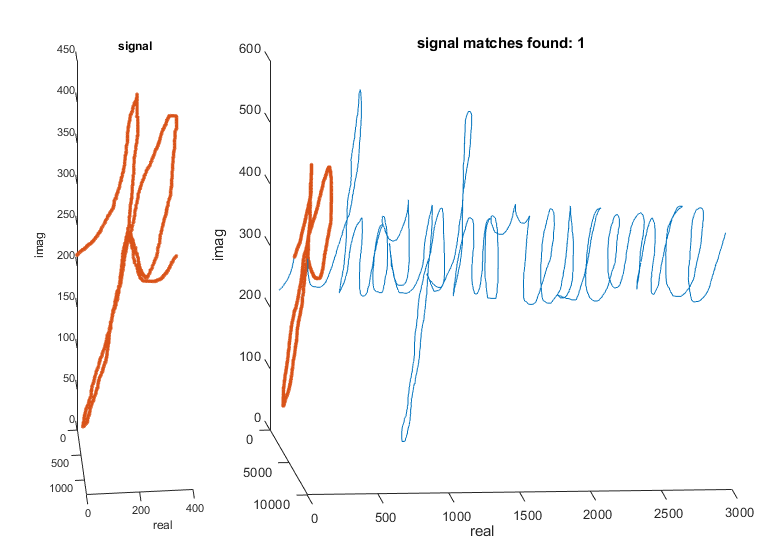
然而,第二个“P”有两个特征,使其难以实现findsignal识别:它从第一个字母有一个显著但恒定的偏移,字母的部分被绘制在不同的速度比模板信号。
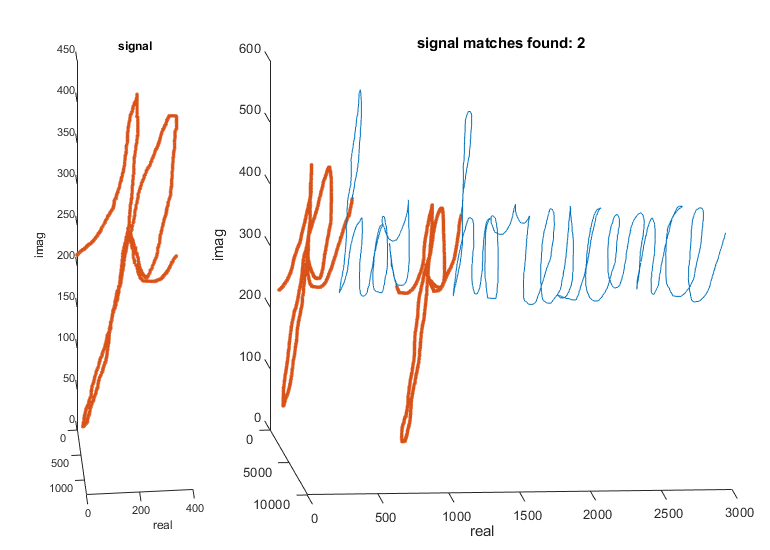
如果您有兴趣匹配信件的整体形状,可以从信号和数据元素中减去窗口的本地均值。这允许您减轻恒定偏移的效果。
为了减轻绘制字母的不同速度的影响,您可以使用动态时间翘曲,这将将信号或数据拉伸到常用时基数,因为它执行搜索:
findsignal(数据,信号,'timealignment'那“dtw”那......“归一化”那'中央'那......“NormalizationLength”600,......'maxnumsegments', 2)
寻找延长时间的电力信号
下一个例子展示了如何使用findsignal找出口语单词在短语中的位置。
以下文件包含短语的音频录制:“加速工程和科学步伐”以及同一扬声器的“工程”的单独音频录制。
加载口号soundsc(短语、fs) soundsc (hotword fs)
相同的发言者常见的是,在句子或短语中改变个别口语单词的发音。在此示例中的扬声器用两种不同的方式发音为“工程”:扬声器大约需要0.5秒钟才能发出短语中的单词,强调第二个音节(“en-gin-eer-ing”);同样的扬声器暂停0.75秒才能孤立发音,强调第三个音节(“en-gin-eer-ing”)。
为了弥补这些局部和体积的这些局部变化,可以使用频谱图,以报告跨越时光的频谱功率分布。
首先,使用一个具有相当粗糙的频率分辨率的谱图。这样做是为了故意模糊声道的窄波段声门脉冲,只留下口腔和鼻腔的宽频共振不受干扰。这可以让你锁定一个单词的发音元音。辅音(尤其是爆破音和擦音)很难用声谱图来识别。下面的代码计算一个声谱图
Nwindow = 64;Nstride = 8;β= 64;Noverlap = Nwindow - Nstride;[~,~,~,PxxPhrase] = spectrogram(phrase, kaiser(Nwindow,Beta), novlap);[~,~,~,PxxHotWord] =谱图(hotword, kaiser(Nwindow,Beta), novlap);
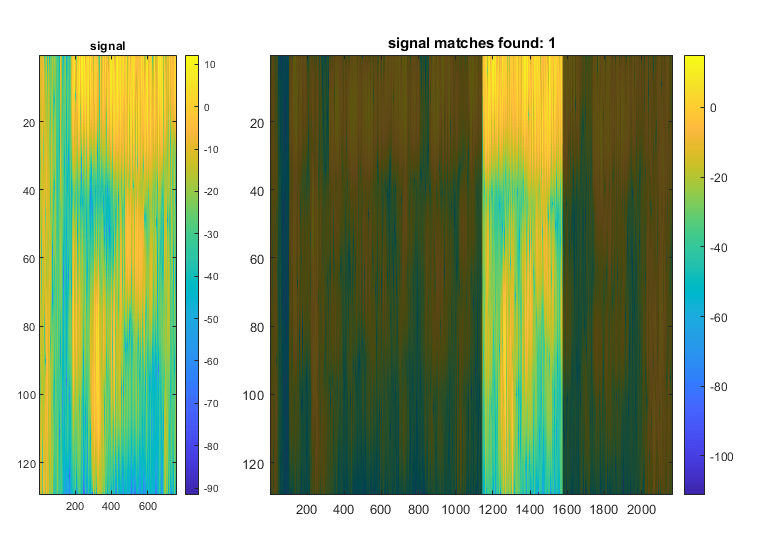
现在您有短语和搜索单词的频谱图,您可以使用动态时间扭曲以解释字长的本地变体。同样,您可以通过使用与对称kullback-leibler距离结合使用功率归一化来计算电源的变化。
[Istart,Istop] = findsignal(pxxphrase,pxxhot字,......“归一化”那'力量'那'timealignment'那“dtw”那“指标”那“symmkl”)
istart = 1144.
istop = 1575
绘制并播放已识别的单词。
findsignal (PxxPhrase PxxHotWord,“归一化”那'力量'那......'timealignment'那“dtw”那“指标”那“symmkl”)
soundsc(短语(Nstride * istart-Nwindow / 2: Nstride * istop + Nwindow / 2), fs)
也可以看看
你也可以从以下列表中选择一个网站:
