迭代方法用于创建标记信号集与减少人类的努力
这个例子中提出了一种基于迭代的深度学习工作流程减少人类标签标签信号的努力。
标签信号数据是一项繁琐和昂贵的任务,需要投入大量人力物力。想办法减少这种努力可以显著加快发展的深度学习信号处理问题的解决方案。万博 尤文图斯
考虑兴趣的任务标记区域的信号数据集。第一种方法包括标签的数据。这种方法需要大量的时间和精力。另一种方法,探索了在这个例子中,将标签迭代过程。在每个迭代中,信号的一个子集选择无标号数据集和发送到pretrained深层网络自动标记。一个人贴标签机检查生成的标签和纠正错误的标签。验证标记信号被添加到一个训练数据集进行再培训的深度网络扩展训练数据。
在每个迭代中,人类贴标签机仍然访问和检查所有标签的信号的网络。然而,从标签信号的任务从头纠正不准确的标签由一个可靠的网络。后一个任务需要大大减少人工标注工作。在每一个新的迭代,网络与越来越多的数据训练,使网络的预测和标签的性能改善。因此,在每次迭代中,越来越少的人工干预是需要正确的标签。
数据
这个例子认为ECG信号的标签区域使用QT数据库中的数据公开[1][2]。大约15分钟的数据由共有105名患者的心电图记录。获得每个记录,审查员把两个电极放在不同的位置在一个病人的胸部,导致双通道信号。数据库提供了信号区域标签由一个自动生成专家系统(3]。标签对应的位置P波、T波,心电图QRS波群地区测量。这个例子遵循的过程波形分割使用深度学习培训双向长短期记忆(BiLSTM)网络,可以分类ECG信号样本属于感兴趣的三个地区之一。
下载的数据GitHub库。这个示例假设您已经把文件放在你的临时目录,由MATLAB®的指定的位置tempdir命令。解压缩数据文件和加载数据。
解压缩(fullfile (tempdir,“QT_Database-master.zip”),tempdir)负载(fullfile (tempdir“QT_Database-master”,“QTData.mat”))
使用displayWaveformLabelshelper函数绘制的第一个1000个样本ECG信号的第一个病人,与专家系统覆盖区域标记的不同的颜色。数据集包含一个额外的标签,“N / A”,这是用来识别信号样本,不属于任何感兴趣的三个区域。
patientID = 1;signalVals = getSignal (QTData patientID);labelVals = getLabelValues (QTData patientID,“WaveformLabels_Chan1”);1:1000 displayWaveformLabels (signalVals (1), labelVals.Value (1:1000))

使用resizeSignalshelper函数将心电信号和标签向量为框架,他们每个人5000样品长。函数然后打乱帧,将它们划分为包含70%的数据的训练数据集和测试数据集包含30%的数据。
rng默认的[testFrames, testLabels ecgFrames、ecgLabels testInfo, ecgInfo] = resizeSignals (QTData, 0.3);
ecgFrames包含6543帧和testFrames包含2768帧。的变量ecgInfo存储患者ID、通道ID和样本指数每一帧的训练数据集。testInfo存储测试数据集的相同的信息。
时频域变换心电图帧。使用featureExtractionhelper函数来计算ECG信号的傅里叶synchrosqueezed变换帧在感兴趣的频率范围内,0.5,40赫兹,和规范产生的转换通过减去均值和除以标准差。
Fs = QTData.SampleRate;testFrames = featureExtraction (testFrames, Fs);ecgFrames = featureExtraction (ecgFrames, Fs);
这个例子表明,可以减少人类努力参与信号标签通过迭代训练网络。在每一次迭代:
网络标签标记数据帧使用先前标记帧的一个子集。
一个人贴标签机手工纠正任何标签错误。
修正后的标签添加到先前标记为帧。
扩展的标记集信号用于训练网络为下一次迭代。
进行定量比较,模拟两个场景:
对于基线场景中,一个人从头开始标签整个数据集,训练网络充分利用标记
ecgFrames集。对于第二个场景,假装
ecgFrames数据标记和标签使用迭代方法。
使用完全预测性能标签心电图数据集
建立一个BiLSTM网络和训练它完整的标签ecgFrames将得到一个prediction-performance上界。正如上面提到的,这种方法需要强力标签的数据集,因此人类最大的标签。列车网络标签ecgFrames设置和计算测试数据集上的预测精度。
网络体系结构
使用深度学习创建一个BiLSTM网络层。
指定一个
sequenceInputLayer的大小随着特征数量的FSST的信号,即频域样本总数在这个例子中(40)。指定一个
bilstmLayer200年隐藏节点和设置OutputMode来序列因为每个信号样本的标签。指定一个
fullyConnectedLayer相应的输出尺寸4四类,P波、QRS波群,T波,N / A。添加一个
softmaxLayer和一个classificationLayer输出估计标签。
%与完整的模拟训练无标号数据集层= […sequenceInputLayer(大小(ecgFrames {1}, 1)) bilstmLayer(200年“OutputMode”,“序列”)fullyConnectedLayer (4) softmaxLayer classificationLayer];
使用traningOptions指定优化解算器和hyperparameters训练网络。下面的例子使用了亚当优化和mini-batch大小为50。列车网络使用一个CPU或GPU。使用GPU需要并行计算工具箱™。看到支持gpu,明白了万博1manbetxGPU的万博1manbetx支持版本(并行计算工具箱)。其他参数的信息,请参阅trainingOptions(深度学习工具箱)。这个示例使用GPU培训使用'ExecutionEnvironment的名称-值对。
选择= trainingOptions (“亚当”,…“MaxEpochs”10…“MiniBatchSize”,50岁,…“ExecutionEnvironment”,“图形”,…“InitialLearnRate”,0.01,…“LearnRateDropPeriod”6…“LearnRateSchedule”,“分段”,…“GradientThreshold”,1…“洗牌”,“every-epoch”,…“阴谋”,“训练进步”,…“详细”,0);
列车的网络完全标记ecgFrames数据集。
baselineNet = trainNetwork (ecgFrames、ecgLabels层,选择);

分类测试框架使用训练有素的网络和计算平均预测精度。基线预测精度约为95%。
predictLabelsAll =分类(baselineNet testFrames,“MiniBatchSize”,50);accuracyAll =意味着(cellfun (@ (x, y) (x = = y), predictLabelsAll, testLabels));流(的基线预测精度是2.1 f % % %。\ n”,accuracyAll * 100);
基线预测精度为94.2%。
循环迭代标签与人类
降低标签的努力,尝试迭代方法:假装ecgFrames数据集最初手动标记和数据标记。在现实中,提供的示例使用地面实况标签数据集。
火车一个初始网络
通过选择25帧的开始ecgFrames手动设置和标签。火车BiLSTM网络的初始标记集作为初始迭代过程的步骤。
numInitFrames = 25;currentTrainingSet = ecgFrames (1: numInitFrames, 1);currentTrainingLabels = ecgLabels (1: numInitFrames);
设置培训选择有更多的时代和一个较小的mini-batch大小因为只有25帧在最初的训练数据集。
选择= trainingOptions (“亚当”,…“MaxEpochs”,20岁,…“MiniBatchSize”5,…“ExecutionEnvironment”,“图形”,…“InitialLearnRate”,0.01,…“LearnRateDropPeriod”6…“LearnRateSchedule”,“分段”,…“GradientThreshold”,1…“洗牌”,“every-epoch”,…“阴谋”,“没有”,…“详细”,0);
火车BiLSTM网络初始训练数据集和预测标签使用相同的测试数据集用于建立性能基线。网络的预测精度小于80%。
initNet = trainNetwork (currentTrainingSet、currentTrainingLabels层,选择);initPrediction =分类(initNet testFrames,“MiniBatchSize”,50);initAccuracy =意味着(cellfun (@ (x, y) (x = = y), initPrediction, testLabels));流(预测精度是f % % % 2.1。\ n”,initAccuracy * 100);
预测精度为78.3%。
标签
在下一步,选择200的新数据帧ecgFrames集,并将它们提供给pretrained网络,initNet,标签自动信号。
迭代= 1;%的帧数在每个迭代标签numFrames = 200;%选择下一组帧标签indexNext = numInitFrames + 1: numInitFrames + numFrames;currentPrediction =分类(initNet ecgFrames (indexNext),“MiniBatchSize”,50);
评估网络生成的标记结果,比较它们在地上的真理。使用所选的第三200 -样本数据帧为例:情节首次750个样本覆盖真实的标签和标签的预测网络。
idx = 3;信息= ecgInfo {indexNext (idx)};信号= QTData.Source {info.patientID} (info.channelID info.indexID);groundTruthLabels = ecgLabels {indexNext (idx)};predictedLabels = currentPrediction {idx};次要情节(2,1,1)displayWaveformLabels(信号,groundTruthLabels) xlim([750])标题(“地面实况”次要情节(2,1,2)displayWaveformLabels(信号,predictedLabels) xlim([750])标题(网络”的标签)

网络标签帧做了一个好工作。因此,一个人检查的结果网络可以正确预测的标签。
然而,在某些情况下,网络的标签性能并不旺盛。考虑结果的第六选择200 -样本数据帧。
idx = 6;信息= ecgInfo {indexNext (idx)};信号= QTData.Source {info.patientID} (info.channelID info.indexID);groundTruthLabels = ecgLabels {indexNext (idx)};predictedLabels = currentPrediction {idx};图次要情节(2,1,1)displayWaveformLabels(信号,groundTruthLabels) xlim([750])标题(“地面实况”次要情节(2,1,2)displayWaveformLabels(信号,predictedLabels) xlim([750])标题(网络”的标签)

网络的性能在这个信号不是那么好。检查结果,人类贴标签机必须做出几个修正预测标签。
量化修正为200数据帧,计算网络的标签错误率和样品每帧的平均数量,必须纠正人类贴标签机。
numSamplesPerFrame = 5000;networkLabelingErrorRate(迭代)= 1,就意味着(cellfun (@ (x, y) (x = = y), currentPrediction, ecgLabels (indexNext)));averageNumOfCorrectionsPerFrame(迭代)= networkLabelingErrorRate(迭代)* numSamplesPerFrame;流(修正每帧的平均数量是% 2.1 f。\ n 'averageNumOfCorrectionsPerFrame(迭代));
修正每帧的平均数是1077.4。
第一次迭代,平均约有1000个样本每帧必须纠正的人。
在第一次迭代结束后,人类将检查200帧和修改任何标签使用不正确的值。在网络的帮助下,人类的贴标签机,数据帧的正确标签的迭代。
在下一次迭代,可以添加到200新标签的帧currentTrainingSet将培训网络和重复标签迭代。这个图表说明了工作流在第一次迭代后的每一次迭代中:

重复迭代标签
通过添加新修正的扩展训练集标签帧,选择另一个200数据帧标记,重复标签迭代,直到性能令人满意。
%,包括最初的训练集和200年新标签的数据帧麦克斯特= 15;indexTraining = 1: numInitFrames + numFrames;networkAccuracy = 0 (1、15);networkAccuracy(迭代)= initAccuracy;选择= trainingOptions (“亚当”,…“MaxEpochs”,20岁,…“MiniBatchSize”,50岁,…“ExecutionEnvironment”,“图形”,…“InitialLearnRate”,0.01,…“LearnRateDropPeriod”6…“LearnRateSchedule”,“分段”,…“GradientThreshold”,1…“洗牌”,“every-epoch”,…“阴谋”,“没有”,…“详细”,0);为迭代= 2:麦克斯特%扩展训练数据集currentTrainingSet = ecgFrames (indexTraining, 1);%真实模仿人类调整分配标签%扩展训练集currentTrainingLabels = ecgLabels (indexTraining);%与扩展训练集训练网络currentNet = trainNetwork (currentTrainingSet、currentTrainingLabels层,选择);%预测标签的测试数据集和计算的准确性%比较基线性能currentTestSetPrediction =分类(currentNet testFrames,“MiniBatchSize”,50);networkAccuracy(迭代)=意味着(cellfun (@ (x, y) (x = = y), currentTestSetPrediction, testLabels));%得到另一个人类贴标签机numFrames数据帧indexNext = indexTraining(结束)+ 1:indexTraining(结束)+ numFrames;%衡量人类的平均数量在这个迭代修正每帧currentPrediction =分类(currentNet ecgFrames (indexNext),“MiniBatchSize”,50);networkLabelingErrorRate(迭代)= 1,就意味着(cellfun (@ (x, y) (x = = y), currentPrediction, ecgLabels (indexNext)));averageNumOfCorrectionsPerFrame(迭代)= networkLabelingErrorRate(迭代)* numSamplesPerFrame;indexTraining = 1: indexNext(结束);结束
标签的性能
经过15标签迭代,有2825个数据帧currentTrainingSet,相应的大约一半的6543数据帧中包含完整的ecgDataset集。网络的预测精度训练2825帧只有1%低于基线精度。
accuDiff = accuracyAll-networkAccuracy(结束);流(的精度差别是f % % % 2.1。\ n”,accuDiff * 100);
精度的区别是0.8%。
情节的网络预测精度测试数据集对训练数据集的大小在每个迭代。显示的准确性得到的上界完全标记数据集。随着越来越多的数据帧进行验证,网络的预测精度得到改善。
图examinedDataSize = 25:200:2825;情节(examinedDataSize networkAccuracy,“* - - - - - -”)举行在%预测精度上界情节(examinedDataSize (15) * accuracyAll,“r——”网格)在包含(训练集规模的)标题(的精度测试数据集的)xlim(25[2825])传说(“标签网络”,“上界”,“位置”,“东南”)

在每次迭代结束时,人类修正每帧的平均数量增加作为训练数据集的大小减少。随着越来越多的数据帧进行验证和用于训练网络,减少人类的努力是需要正确的标签,选中的帧。在最后的迭代中,平均每帧300个样本,需要人工修正。
图绘制(examinedDataSize averageNumOfCorrectionsPerFrame,“* - - - - - -”网格)在包含(训练集规模的)标题(“人类修正每帧的平均数量”)xlim([2825] 25日)
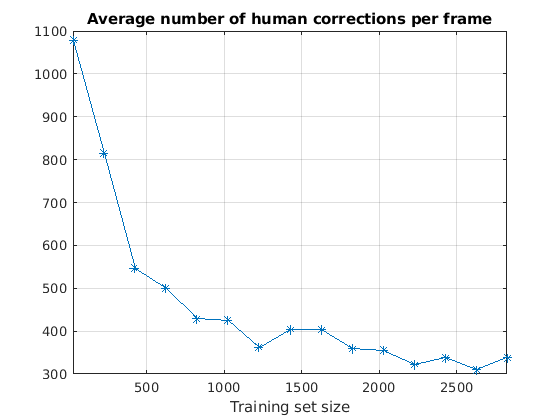
所有15个标签迭代,平均约500信号样本每帧需要人类的修正。
流(修正每帧的平均数量是% 2.1 f。\ n '意思是(averageNumOfCorrectionsPerFrame));
修正每帧的平均数是465.7。
结论
这个例子表明,标签只有一半的心电图数据集允许深度网络达到预测精度与通过网络训练时完全相同标签的数据集。提出了迭代标签工作流,人类贴标签机需要看只有一半的数据集和正确的500年平均每帧信号样本。另一方面,强力标签需要查看每一帧的数据集和标签样本。
引用
[1]不氩L。,Luis A. N. Amaral, Leon Glass, Jeffery M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. "PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals." Circulation. Vol. 101, Number 23, 2000, pp. e215–e220. [Circulation Electronic Pages; http://circ.ahajournals.org/content/101/23/e215.full].
[2]拉古纳,巴勃罗,罗杰·g·马克,必要l . Goldberger和乔治·b·穆迪。“数据库评估算法测量心电图QT间隔和其他波形的。”Computers in Cardiology. Vol.24, 1997, pp. 673–676.
[3]拉古纳,巴勃罗,Raimon简,Pere Caminal。“自动波边界的检测多引入线的心电图信号:与CSE数据库验证。”Computers and Biomedical Research. Vol. 27, Number 1, 1994, pp. 45–60.
