使用分类学习应用程序训练朴素贝叶斯分类器
这个例子展示了如何使用Classification Learner应用程序创建和比较不同的朴素贝叶斯分类器,并将训练过的模型导出到工作空间,以对新数据进行预测。
朴素贝叶斯分类器利用贝叶斯定理,并假设每个类中的预测器彼此独立。然而,即使独立性假设不成立,分类器似乎也能很好地工作。你可以在分类学习器中对两个或多个类使用朴素贝叶斯。该应用程序允许您单独或同时训练高斯朴素贝叶斯模型或内核朴素贝叶斯模型。
该表列出了分类学习器中可用的朴素贝叶斯模型,以及每个模型用于拟合预测因子的概率分布。
| 模型 | 数值预测 | 分类预测 |
|---|---|---|
| 高斯朴素贝叶斯 | 高斯分布(或正态分布) | 多元多项分布 |
| 核朴素贝叶斯 | 内核分配 您可以指定内核类型和支持。万博1manbetx分类学习器自动确定核宽度使用底层 fitcnb函数。 |
多元多项分布 |
本例使用Fisher的虹膜数据集,其中包含三个物种标本的花的测量值(花瓣长度、花瓣宽度、萼片长度和萼片宽度)。训练朴素贝叶斯分类器来预测基于预测器测量的物种。
在MATLAB中®命令窗口,加载Fisher虹膜数据集,并使用数据集中的变量创建测量预测器(或特征)表。
渔场=可读表(“fisheriris.csv”);单击应用程序选项卡,然后单击右侧的箭头应用程序部分打开应用程序库。在机器学习和深度学习组中,单击分类学习者.
在分类学习者选项卡,在文件部分中,选择从工作区中创建会话>.

在“从工作区新建会话”对话框中,选择表
fishertable从数据集变量列出(如有必要)。如对话框所示,应用程序根据数据类型选择响应变量和预测变量。花瓣和萼片的长度和宽度是预测因子,而物种是你想要分类的响应。对于本例,不要更改选择。
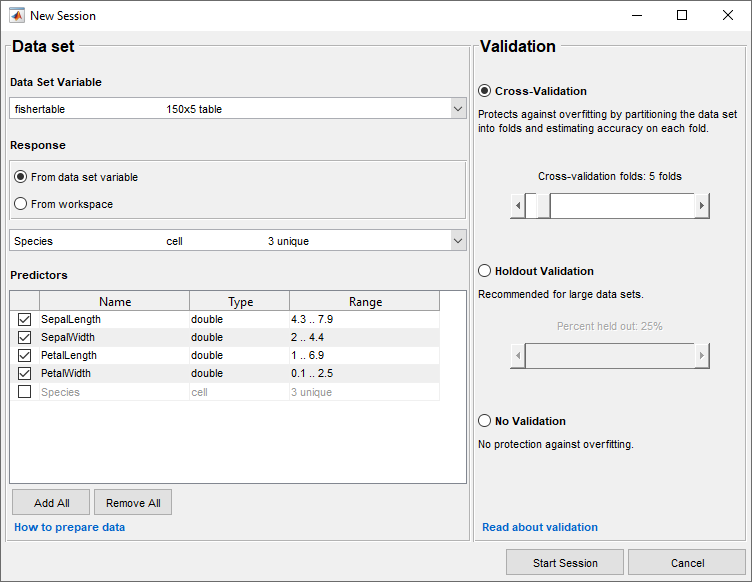
若要接受默认验证方案并继续,请单击开始会议.默认的验证选项是交叉验证,以防止过拟合。
分类学习器创建数据的散点图。
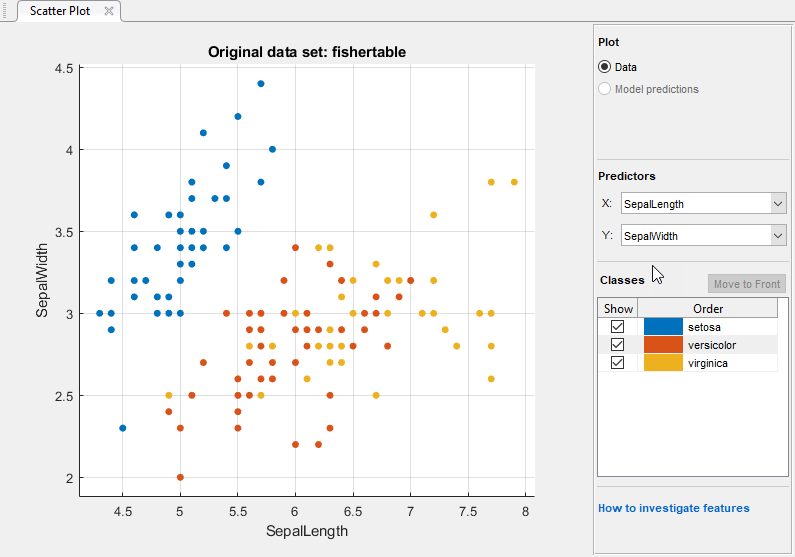
使用散点图来研究哪些变量对预测响应有用。上选择不同的选项X而且Y列表下预测使物种分布和测量可视化。观察哪些变量将物种的颜色区分得最清楚。
的
setosa物种(蓝色点)很容易从其他两个物种中分离出来。的多色的而且virginica物种在所有预测测量和重叠中都更接近,特别是当你绘制萼片长度和宽度时。setosa比其他两个物种更容易预测。创建一个朴素贝叶斯模型。在分类学习者选项卡,在模型类型部分,单击箭头打开图库。在朴素贝叶斯分类器组中,单击高斯朴素贝叶斯.注意,分类学习器禁用先进的按钮。模型类型部分,因为这种类型的模型没有高级设置。

在培训部分中,点击火车.
该应用程序创建一个高斯朴素贝叶斯模型,并绘制结果。
应用程序显示高斯朴素贝叶斯模型中的模型窗格。中检查模型验证分数准确性(验证)盒子。分数表明该模型表现良好。
为高斯朴素贝叶斯默认情况下,该应用程序使用高斯分布对数值预测器的分布建模,并使用多元多项分布(MVMN)对类别预测器的分布建模。
请注意
验证在结果中引入了一些随机性。您的模型验证结果可能与本示例中显示的结果不同。
检查散点图。X表示错误分类的点。蓝色的点(
setosa物种)都是正确的分类,但其他两个物种有错误的分类点。下情节,在数据而且模型的预测选项。观察错误(X)点的颜色。或者,要只查看不正确的点,请清除正确的复选框。训练一个核朴素贝叶斯模型进行比较。在分类学习者选项卡,在模型类型部分中,点击核朴素贝叶斯.注意,分类学习器启用先进的按钮,因为这种类型的模型有高级设置。

程序中显示了一个内核朴素贝叶斯模型草案模型窗格。
在模型类型部分中,点击先进的在“高级朴素贝叶斯选项”对话框中更改设置。选择
三角形从内核类型列表,并选择积极的从万博1manbetx列表。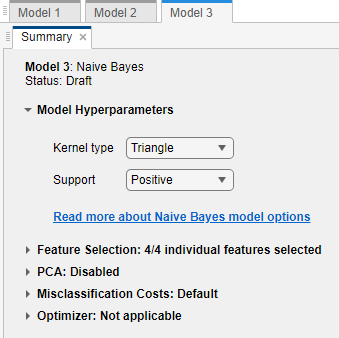
请注意
“高级朴素贝叶斯选项”对话框中的设置仅适用于连续数据。指向内核类型显示工具提示“为连续变量指定内核平滑函数”,并指向万博1manbetx显示工具提示“指定连续变量的内核平滑密度支持”。万博1manbetx
在培训部分中,点击火车训练新模型。
的模型窗格现在包含了新的内核朴素贝叶斯模型。其模型验证得分优于高斯朴素贝叶斯模型。该应用程序突出显示准确性(验证)通过在一个框中勾勒出最佳模型的分数。
在模型窗格中,单击每个模型以查看和比较结果。
同时训练高斯朴素贝叶斯模型和核朴素贝叶斯模型。在分类学习者选项卡,在模型类型部分中,点击全朴素贝叶斯.分类学习器禁用先进的按钮。在培训部分中,点击火车.

该应用程序训练每种朴素贝叶斯模型类型之一,并突出显示准确性(验证)最佳模型或模型得分。
在模型窗格中,单击模型以查看结果。检查训练模型的散点图,并尝试绘制不同的预测因子。错误分类的点以X表示。
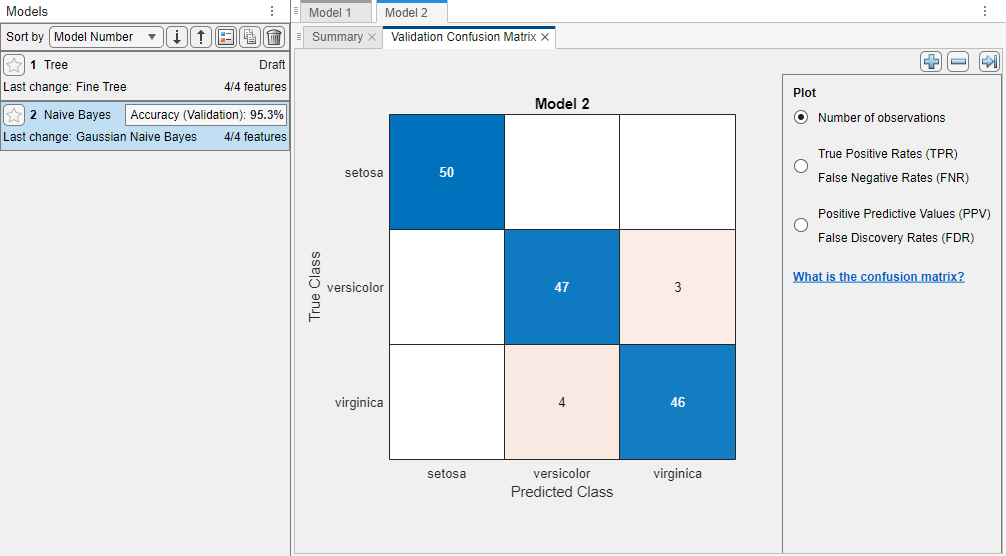
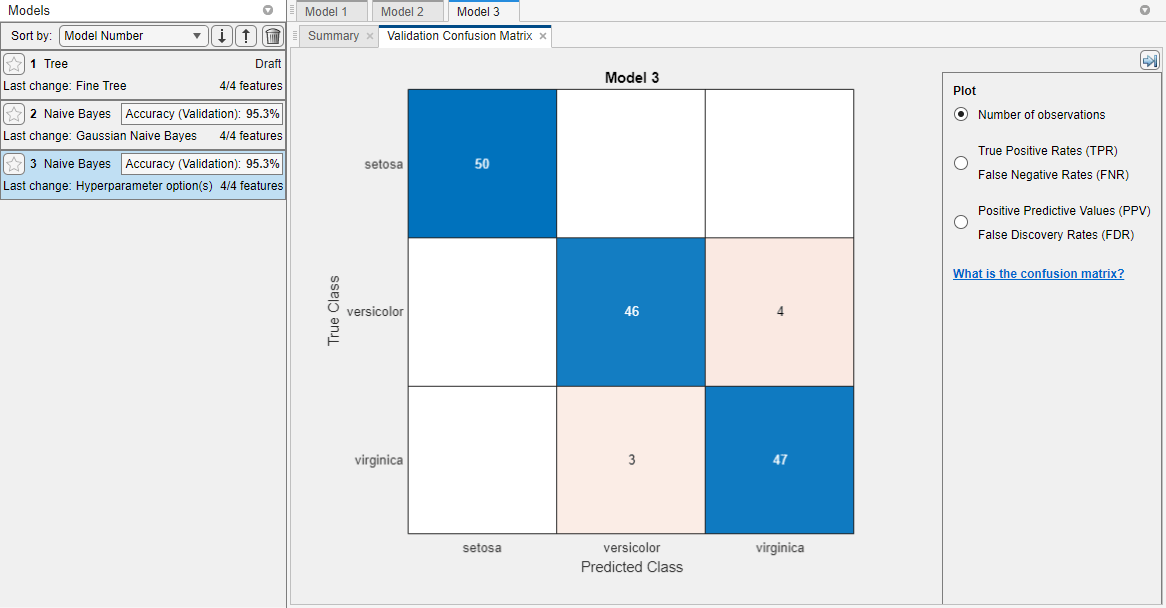
为了检查每个班级预测的准确性,在分类学习者选项卡,在情节部分中,点击混淆矩阵并选择验证数据.该应用程序显示了真实班级和预测班级结果的矩阵。

请注意
验证在结果中引入了一些随机性。您的混淆矩阵结果可能与本例中显示的结果不同。
在模型窗格中,单击其他模型并比较它们的结果。
在模型窗格中,单击最高的模型准确性(验证)得分。要改进模型,请尝试修改其特征。例如,看看是否可以通过去除低预测能力的特征来改进模型。
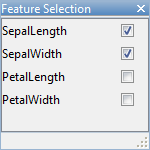
在分类学习者选项卡,在特性部分中,点击特征选择.
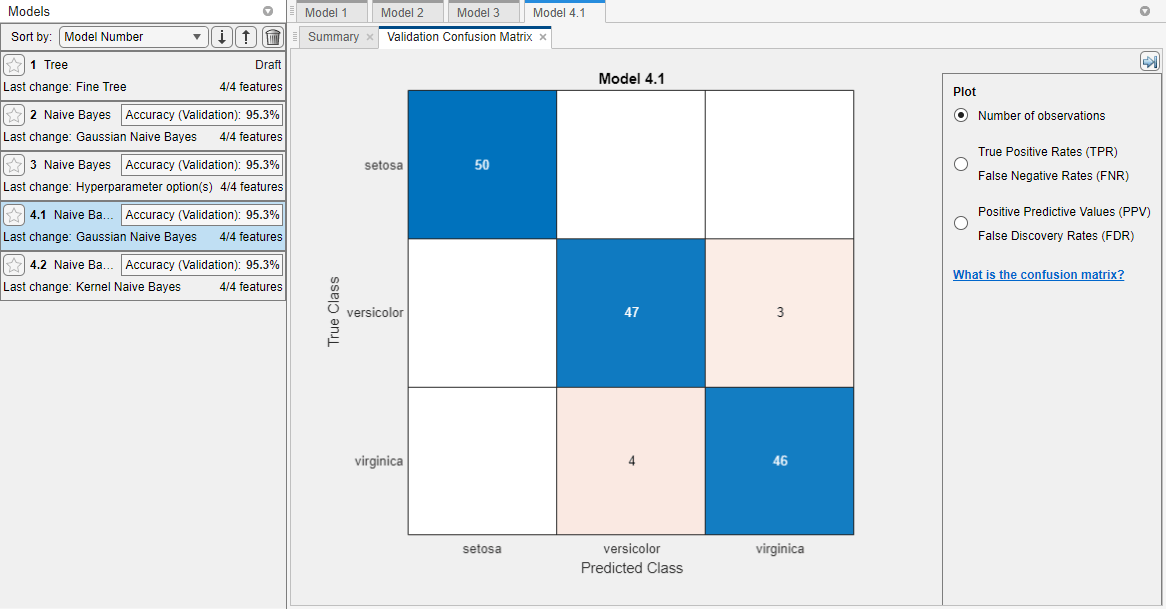
在“功能选择”对话框中,清除为的复选框PetalLength而且PetalWidth将它们从预测因子中排除。一个新的模型草案(模型4)出现在模型窗格的新设置(2/4特征),基于内核朴素贝叶斯模型(模型3.2)。
在培训部分中,点击火车使用新的预测器选项来训练一个新的内核朴素贝叶斯模型。
的模型窗格现在包括模型4。它也是一个内核朴素贝叶斯模型,仅使用4个预测因子中的2个进行训练。
属性中的模型,以确定包含哪些预测因子模型窗格,然后单击特征选择在特性部分,并注意选中了哪些复选框。只有萼片测量的模型(模型4)的值要低得多准确性(验证)得分高于包含所有预测因子的模型。
训练另一个只包含花瓣测量值的核朴素贝叶斯模型。更改“功能选择”对话框中的选择,然后单击火车.

仅使用花瓣测量训练的模型(模型5)的表现与包含所有预测因子的模型相当。与仅使用花瓣测量相比,使用所有测量结果的模型预测结果并不更好。如果数据收集是昂贵的或困难的,您可能更喜欢一个没有一些预测器就能令人满意地执行的模型。
要研究要包含或排除的特征,请使用平行坐标图。在分类学习者选项卡,在情节部分中,点击平行坐标.
在模型窗格中,单击最高的模型准确性(验证)得分。要进一步改进模型,请尝试更改朴素贝叶斯设置(如果可用)。在分类学习者选项卡,在模型类型部分中,点击先进的.回想一下先进的按钮仅对某些型号启用。更改设置,然后通过单击来训练新模型火车.
将训练好的模型导出到工作区。在分类学习者选项卡,在出口部分中,选择导出模型>导出模型.看到导出分类模型预测新数据.
检查训练这个分类器的代码。在出口部分中,点击生成函数.













使用相同的工作流来评估和比较您可以在“分类学习器”中训练的其他分类器类型。
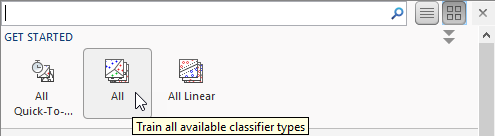
要尝试所有可用于您的数据集的不可优化分类器模型预设:
上的箭头模型类型部分打开分类器库。
在开始组中,单击所有,然后按火车在培训部分。

有关其他分类器类型的信息,请参见在分类学习App中训练分类模型.
相关的话题
您也可以从以下列表中选择一个网站:
