fitcnb
训练多类朴素贝叶斯模型
句法
描述
Mdl= fitcnb(TBL,ResponseVarName)Mdl),培养在表中的预测TBL和类标签的变量Tbl.ResponseVarName。
例子
培养出的朴素贝叶斯分类器
加载费舍尔的虹膜数据集。
加载fisheririsX = MEAS(:,3:4);Y =物种;制表(Y)
值计数百分比setosa 50 33.33%50花斑癣33.33%锦葵50 33.33%
该软件可以使用朴素贝叶斯方法对两类以上的数据进行分类。
训练朴素贝叶斯分类器。这是指定的类顺序很好的做法。
MDL = fitcnb(X,Y,...“类名”,{'setosa',“花斑癣”,“弗吉尼亚”})
Mdl = ClassificationNaiveBayes ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'setosa' 'versicolor' virginica'} ScoreTransform: 'none' NumObservations: 150 DistributionNames: {'normal' 'normal'} DistributionParameters: {3x2 cell}属性、方法
Mdl是一个训练有素的ClassificationNaiveBayes分类器。
默认情况下,软件模型使用具有一些均值和标准差的高斯分布的每个类别中的预测分布。使用点表示法显示特定高斯拟合的参数,例如,显示适合内的第一特征setosa。
setosaIndex = strcmp (Mdl.ClassNames,'setosa');估计= Mdl.DistributionParameters {setosaIndex,1}
估计=2×11.4620 0.1737
均值1.4620和标准偏差是0.1737。
绘制高斯等高线。
图gscatter (X (: 1), (:, 2), Y);甘氨胆酸h =;cxlim = h.XLim;cylim = h.YLim;持有在PARAMS = cell2mat(Mdl.DistributionParameters);亩=参数(2 *(1:3)-1,1:2);%提取手段西格玛=零(2,2,3);对于1 = 1:3 Sigma(:,:,j) = diag(Params(2*j,:)).^2;%创建对角协方差矩阵xlim = Mu(j,1) + 4*[-1]*sqrt(Sigma(1,1,j));ylim = Mu(j,2) + 4*[-1]*sqrt(Sigma(2,2,j));f = @ (x1, x2)重塑(mvnpdf ((x1 (:), x2(:)),μ(j,:),σ(:,:,j)),大小(x1));fcontour (f, [xlim ylim])%画出轮廓的多变量正态分布结束h。X大号一世米=CXlim; h.YLim = cylim; title(“朴素贝叶斯分类器 - 费舍尔的虹膜数据”)包含('花瓣长度(cm)')ylabel (“花瓣宽度(厘米)”)传说('setosa',“花斑癣”,“弗吉尼亚”)保持从
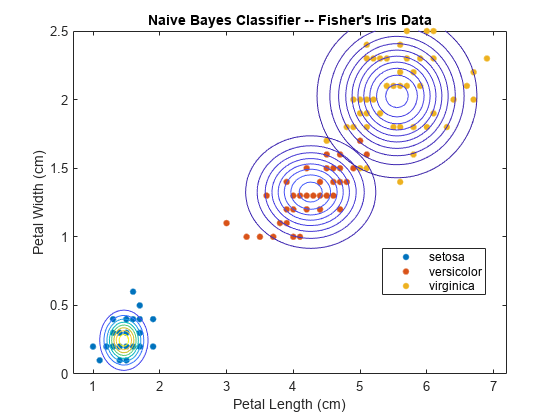
您可以使用名称 - 值对参数更改默认的分配'DistributionNames'。例如,如果一些预测是明确的,那么你可以指定他们使用多变量,多项随机变量'DistributionNames', 'mvmn'。
指定先验概率在训练朴素贝叶斯分类
构建一个朴素贝叶斯分类器对费舍尔的虹膜数据集。此外,培训期间指定先验概率。
加载费舍尔的虹膜数据集。
加载fisheririsX =量;Y =物种;类名= {'setosa',“花斑癣”,“弗吉尼亚”};%级顺序
X是一个包含150和虹膜4次花瓣测量的数值矩阵。ÿ是字符向量的单元阵列,它包含相应的虹膜物种。
默认情况下,在现有类的概率分布是在所述数据集,在这种情况下对于每个物种的33%的类的相对频率分布。但是,假设你知道,在人口虹膜的50%是setosa,20%是花斑癣,30%是弗吉尼亚。您可以通过训练过程中指定该分布作为先验概率将这一信息。
训练朴素贝叶斯分类器。指定类次序和现有类的概率分布。
现有= [0.5 0.2 0.3]。MDL = fitcnb(X,Y,“类名”一会,“在此之前”之前)
MDL = ClassificationNaiveBayes ResponseName: 'Y' CategoricalPredictors:[]类名:{ 'setosa' '云芝' '锦葵'} ScoreTransform: '无' NumObservations:150个DistributionNames:{ '正常' '正常' '正常' '正常'} DistributionParameters{3×4电池}属性,方法
Mdl是一个训练有素的ClassificationNaiveBayes分类,和它的一些特性出现在命令窗口。该软件将预测作为独立给出一个类,在默认情况下,适合使用它们正态分布。
朴素贝叶斯算法训练过程中不使用之前类概率。因此,您可以使用点符号训练后指定之前类概率。例如,假设你想看到使用默认之前类概率和一个模型,使用模型之间的性能差异先。
建立一个新的朴素贝叶斯模型Mdl,并指定先验类的概率分布为经验类分布。
defaultPriorMdl =铜牌;FreqDist = cell2table(平板状(Y));defaultPriorMdl.Prior = FreqDist {:,3};
该软件的标准化之前类概率总和为1。
估计使用两种模型的交叉验证误差10倍交叉验证。
RNG(1);%用于重现defaultCVMdl = crossval (defaultPriorMdl);defaultLoss = kfoldLoss (defaultCVMdl)
defaultLoss = 0.0533
CVMdl = crossval(MDL);损耗= kfoldLoss(CVMdl)
损失= 0.0340
Mdl执行比defaultPriorMdl。
指定朴素贝叶斯分类预测分布
加载费舍尔的虹膜数据集。
加载fisheririsX =量;Y =物种;
使用每一个预测器训练一个朴素贝叶斯分类器。这是指定的类顺序很好的做法。
Mdl1 = fitcnb (X, Y,...“类名”,{'setosa',“花斑癣”,“弗吉尼亚”})
Mdl1 = ClassificationNaiveBayes ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'setosa' 'versicolor' virginica'} ScoreTransform: 'none' NumObservations: 150 DistributionNames: {'normal' 'normal' 'normal'} DistributionParameters: {3x4 cell}属性、方法
Mdl1.DistributionParameters
ANS =3×4单元阵列{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}{2x1双}
Mdl1.DistributionParameters {1,2}
ANS =2×13.4280 0.3791
默认情况下,软件将每个类内的预测器分布建模为具有一定均值和标准差的高斯分布。有四个预测器和三个类级别。每个细胞在Mdl1.DistributionParameters对应于含有各分布的平均值和标准偏差的数值向量,例如,用于setosa的平均值和标准偏差虹膜萼片宽度3.4280和0.3791, 分别。
估计所述混淆矩阵Mdl1。
isLabels1 = resubPredict (Mdl1);ConfusionMat1 = confusionchart (Y, isLabels1);
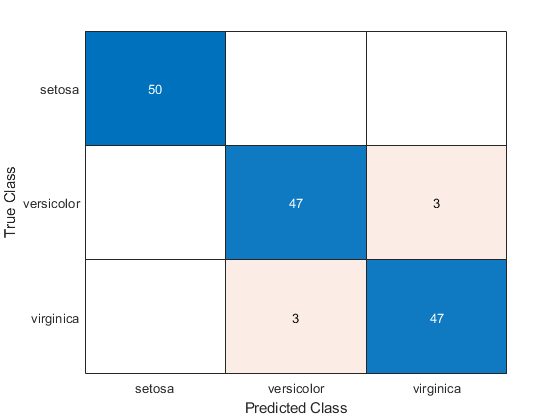
元素(Ĵ,ķ)混淆矩阵图表的表示观察的数目,该软件归类为ķ,但真正在课堂上Ĵ根据该数据。
重新训练使用用于预测1和2(在萼片长度和宽度)的高斯分布的分类器,以及用于预测3和4(花瓣的长度和宽度)的默认正常核密度。
MDL2 = fitcnb(X,Y,...'DistributionNames',{'正常','正常','核心','核心'},...“类名”,{'setosa',“花斑癣”,“弗吉尼亚”});Mdl2.DistributionParameters {1,2}
ANS =2×13.4280 0.3791
软件不训练参数到核密度。相反,软件会选择一个最佳宽度。属性指定宽度“宽度”名称-值对的论点。
估计所述混淆矩阵Mdl2。
isLabels2 = resubPredict (Mdl2);ConfusionMat2 = confusionchart (Y, isLabels2);
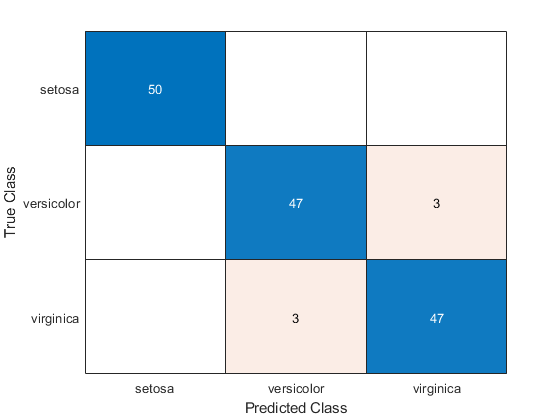
基于所述混淆矩阵,所述两个分类器训练样本中类似地执行。
使用交叉验证比较分类器
加载费舍尔的虹膜数据集。
加载fisheririsX =量;Y =物种;RNG(1);%用于重现
火车和交叉验证朴素贝叶斯分类使用默认选项和ķ倍交叉验证。这是指定的类顺序很好的做法。
CVMdl1 = fitcnb (X, Y,...“类名”,{'setosa',“花斑癣”,“弗吉尼亚”},...“CrossVal”,'上');
默认情况下,软件将每个类内的预测器分布建模为具有一定均值和标准差的高斯分布。CVMdl1是一个ClassificationPartitionedModel模型。
创建一个默认的朴素贝叶斯二进制分类器模板,并训练一个纠错、输出码的多类模型。
T = templateNaiveBayes();CVMdl2 = fitcecoc(X,Y,“CrossVal”,'上',“学习者”,T);
CVMdl2是一个ClassificationPartitionedECOC模型。您可以使用相同的名称 - 值对的参数作为指定朴素贝叶斯学习二元期权fitcnb。
比较出的样本ķ-折叠分类误差(误分类观测的比例)。
classErr1 = kfoldLoss(CVMdl1,“LossFun”,'ClassifErr')
classErr1 = 0.0533
classErr2 = kfoldLoss (CVMdl2,“LossFun”,'ClassifErr')
classErr2 = 0.0467
Mdl2具有较低的泛化误差。
训练朴素贝叶斯分类使用多项预测因素
一些垃圾邮件过滤器根据一个单词或标点符号(称为标记)在电子邮件中出现的次数将收到的电子邮件归类为垃圾邮件。预测因子是电子邮件中特定单词或标点符号出现的频率。因此,预测因子由多项随机变量组成。
本实施例说明使用朴素贝叶斯和多项式预测器的分类。
创建训练数据
假设你观察到的1000封电子邮件,并归类他们为垃圾邮件或垃圾邮件。通过随机分配做到这一点-1或1ÿ对于每一个电子邮件。
N = 1000;%样本量RNG(1);%用于重现Y = randsample([-1],n,true);%随机标签
要构建预测器数据,假设词汇表中有5个标记,每封电子邮件有20个观察到的标记。通过抽取随机的多项偏差,从五个令牌中生成预测数据。垃圾邮件与非垃圾邮件对应的令牌的相对频率应该有所不同。
tokenProbs = [0.2 0.3 0.1 0.15 0.25;...0.4 0.1 0.3 0.05 0.15];令牌相对频率tokensPerEmail = 20;%修正为方便X = 0 (n, 5);X (Y = = 1:) = mnrnd (tokensPerEmail, tokenProbs (: 1)、sum (Y = = 1));X (Y = = 1:) = mnrnd (tokensPerEmail, tokenProbs (2:)、sum (Y = = 1));
训练分类
训练朴素贝叶斯分类器。指定的预测是多项。
MDL = fitcnb(X,Y,'DistributionNames',“百万”);
Mdl是一个训练有素的ClassificationNaiveBayes分类器。
评估中,样品性能Mdl通过估计误分。
isGenRate = resubLoss(MDL,“LossFun”,'ClassifErr')
isGenRate = 0.0200
样本内误分类率为2%。
创建新数据
随机产生,代表了一批新的电子邮件偏离。
newN = 500;newY = randsample([ - 1 1],newN,TRUE);下一页末=零(newN,5);下一页末(newY == 1,:) = mnrnd(tokensPerEmail,tokenProbs(1,:),...总和(newY = = 1));newX(newY == -1,:) = mnrnd(tokenProbs),...总和(newY == -1));
评估分类器的性能
使用训练好的朴素贝叶斯分类器对新邮件进行分类Mdl,并确定算法是否可以推广。
oosGenRate =损失(Mdl newX newY)
oosGenRate = 0.0261
出样品的-错误分类率2.6%,表明该分类归纳得相当好。
优化朴素贝叶斯分类器
这个示例展示如何使用OptimizeHyperparameters名称 - 值对分类器使用,以尽量减少在朴素贝叶斯交叉验证损失fitcnb。这个例子使用了Fisher的虹膜数据。
加载费舍尔的虹膜数据。
加载fisheririsX =量;Y =物种;类名= {'setosa',“花斑癣”,“弗吉尼亚”};
使用“auto”参数优化分类。
对于重复性,设置随机种子,并使用“预计-改善,加上”采集功能。
RNG默认MDL = fitcnb(X,Y,“类名”一会,'OptimizeHyperparameters','汽车',...“HyperparameterOptimizationOptions”,结构('AcquisitionFunctionName',...“预计-改善,加上”))
警告:建议在优化朴素贝叶斯的宽度参数时首先标准化所有数值预测器。如果您已经这样做了,请忽略此警告。
| ===================================================================================================== ||ITER |EVAL |目的|目的|BestSoFar |BestSoFar |分布 - |宽度| | | result | | runtime | (observed) | (estim.) | Names | | |=====================================================================================================| | 1 | Best | 0.053333 | 0.75774 | 0.053333 | 0.053333 | normal | - |
|2 |最佳|0.046667 |0.76016 |0.046667 |0.049998 |内核|0.11903 |
| 3 |接受| 0.053333 | 0.29251 | 0.046667 | 0.046667正常| - |
|4 |接受|0.086667 |0.6733 |0.046667 |0.046668 |内核|2.4506 |
|5 |接受|0.046667 |0.57392 |0.046667 |0.046663 |内核|0.10449 |
|6 |接受|0.073333 |0.82565 |0.046667 |0.046665 |内核|0.025044 |
|7 |接受|0.046667 |0.75362 |0.046667 |0.046655 |内核|0.27647 |
| 8接受| 0.046667 b| 0.57496 | 0.046667 | 0.046647 |内核bb7 0.2031 |
|9 |接受|0.06 |0.43719 |0.046667 |0.046658 |内核|0.44271 |
|10 |接受|0.046667 |0.53128 |0.046667 |0.046618 |内核|0.2412 |
|11 |接受|0.046667 |0.75877 |0.046667 |0.046619 |内核|0.071925 |
|12 |接受|0.046667 |0.67806 |0.046667 |0.046612 |内核|0.083459 |
|13 |接受|0.046667 |1.2735 |0.046667 |0.046603 |内核|0.15661 |
|14 |接受|0.046667 |0.93114 |0.046667 |0.046607 |内核|0.25613 |
| 15 |接受| 0.046667 b| 0.68034 | 0.046667 | 0.046606 |内核| 0.17776 |
|16 |接受|0.046667 |0.34665 |0.046667 |0.046606 |内核|0.13632 |
| 17接受| 0.046667 b| 0.71023 | 0.046667 | 0.046606 |内核| 0.077598 |
|18 |接受|0.046667 |0.40713 |0.046667 |0.046626 |内核|0.25646 |
|19 |接受|0.046667 |0.89971 |0.046667 |0.046626 |内核|0.093584 |
| 20 |接受| 0.046667 b| 1.4125 | 0.046667 | 0.046627 |内核| 0.061602 |
| ===================================================================================================== ||ITER |EVAL |目的|目的|BestSoFar |BestSoFar |分布 - |宽度| | | result | | runtime | (observed) | (estim.) | Names | | |=====================================================================================================| | 21 | Accept | 0.046667 | 0.48559 | 0.046667 | 0.046627 | kernel | 0.066532 |
|22 |接受|0.093333 |0.61192 |0.046667 |0.046618 |内核|5.8968 |
|23 |接受|0.046667 |0.34903 |0.046667 |0.046619 |内核|0.067045 |
|24 |接受|0.046667 |0.41643 |0.046667 |0.04663 |内核|0.25281 |
| 25 |接受| 0.77772 | 0.046667 | 0.04663 |内核bb7 0.1473 |
|26 |接受|0.046667 |0.39873 |0.046667 |0.046631 |内核|0.17211 |
| 27 |接受| 0.44217 | 0.046667 | 0.046631 |内核bb7 0.12457 |
| 28 |接受| 0.046667 | 0.39119 | 0.046667 | 0.046631 |内核| 0.066659 |
|29 |接受|0.046667 |0.4653 |0.046667 |0.046631 |内核|0.1081 |
|30 |接受|0.08 |0.42473 |0.046667 |0.046628 |内核|1.1048 |


__________________________________________________________优化完成。30 MaxObjectiveEvaluations达到。总功能评价:30总运行时间:79.0981秒。总目标函数评估时间:(根据型号)DistributionNames宽度_________________ _______内核0.11903观测目标函数值= 0.046667估计目标函数值= 0.046667功能评估时间= 0.76016最佳估计可行点:19.0411最佳观察到的可行点DistributionNames宽度_________________ _______内核0.25613估计目标函数值= 0.046628估计函数评估时间= 0.58962
MDL = ClassificationNaiveBayes ResponseName: 'Y' CategoricalPredictors:[]类名:{ 'setosa' '云芝' '锦葵'} ScoreTransform: '无' NumObservations:150个HyperparameterOptimizationResults:[1x1的BayesianOptimization] DistributionNames:{1×4细胞} DistributionParameters:{3×4细胞}内核:{1×4细胞}支持:{1×4细胞}万博1manbetx宽度:[3x4的双]的属性,方法
输入参数
输出参数
更多关于
提示
算法
如果您指定
“DistributionNames”、“锰”当训练Mdl运用fitcnb,那么软件配合使用多项分布一袋令牌模型。该软件商店的概率是令牌Ĵ出现在课堂上ķ在属性DistributionParameters {。使用添加剂平滑[2],估计概率为ķ,Ĵ}哪里:
这是令牌出现的加权数Ĵ在班上ķ。
ñķ是在类的观测数ķ。
是用于观察的重量一世。软件对一个类内的权重进行规范化,这样它们的和就等于这个类的先验概率。
这是在类中的所有令牌出现的总加权数ķ。
如果您指定
'DistributionNames', 'mvmn'当训练Mdl运用fitcnb, 然后:对于每一个预测,该软件收集了独特级别的列表,存储在排序列表
CategoricalLevels,并认为每级的Bin。每个预测器/类的组合是分离的,独立多项随机变量。为预测
Ĵ在班上ķ使用列表中的每个分类级别的软件计数实例存储在CategoricalLevels {。Ĵ}该软件存储该预测的概率
Ĵ, 在班上ķ,有水平大号在属性DistributionParameters {,在各级ķ,Ĵ}CategoricalLevels {。使用添加剂平滑[2],估计概率为Ĵ}哪里:
哪个是针对哪个预测器的观测值的加权数Ĵ=大号在班上ķ。
ñķ是在类的观测数ķ。
如果Xij=大号,否则为0。
是用于观察的重量一世。软件对一个类内的权重进行规范化,这样它们的和就等于这个类的先验概率。
米Ĵ在预测器不同的电平的数量Ĵ。
米ķ是在类观测的加权数ķ。
参考
[1] Hastie, T., R. Tibshirani和J. Friedman。统计学习的要素, 第二版。纽约:施普林格,2008年。
[2]曼宁,C.D。,P.拉加,和M.Schütze。现代信息检索纽约州:剑桥大学出版社,2008年。
扩展功能
介绍了在R2014b
您还可以选择从下面的列表中的网站:
