预测
预测使用朴素贝叶斯分类模型标签
描述
输入参数
输出参数
例子
标签朴素贝叶斯分类器的测试样品观察
加载费舍尔的虹膜数据集。
加载fisheririsX = MEAS;%预测因素Y =物种;%响应RNG(1);
训练朴素贝叶斯分类器,并指定要抵抗的数据的30%的测试样品。这是指定的类顺序很好的做法。假设每个预测是有条件的,正态分布给予它的标签。
CVMdl = fitcnb(X,Y,'坚持',0.30,...“类名”{'setosa',“花斑癣”,“弗吉尼亚”});CMDL = CVMdl.Trained {1};%提取物训练有素的,紧凑的分类testIdx =试验(CVMdl.Partition);%提取测试指标XTEST = X(testIdx,:);YTest = Y(testIdx);
CVMdl是ClassificationPartitionedModel分类。它包含属性熟练,这是一个1×1单元阵列保持CompactClassificationNaiveBayes分类,该软件使用训练集训练。
标记测试样品观察结果。显示随机的一组测试样品中10个观察结果。
IDX = randsample(总和(testIdx),10);标记=预测(CMDL,XTEST);表(YTest(IDX),标签(IDX)'VariableNames',...{'TrueLabel','PredictedLabel'})
ANS =10×2表TrueLabel PredictedLabel ______________ ______________ { 'setosa'} { 'setosa'} { '云芝'} { '云芝'} { 'setosa'} { 'setosa'} { '锦葵'} { '锦葵'} { '云芝'} {'云芝'} { 'setosa'} { 'setosa'} { '锦葵'} { '锦葵'} { '锦葵'} { '锦葵'} { 'setosa'} { 'setosa'} { 'setosa'} {'setosa'}
估计后验概率和误分类成本
分类的目的是估计使用受训算法的新的观察后验概率。许多应用培训大型数据集,它可以使用在别处更好使用资源的算法。此示例示出了如何高效地估计使用朴素贝叶斯分类器的新的观察后验概率。
加载费舍尔的虹膜数据集。
加载fisheririsX = MEAS;%预测因素Y =物种;%响应RNG(1);
分区中的数据集分成两组:一个在训练集,另一种是新的未观测到的数据。储备10个观察新的数据集。
N =尺寸(X,1);newInds = randsample(N,10);INDS =〜ismember(1:N,newInds);XNew = X(newInds,:);YNew = Y(newInds);
训练朴素贝叶斯分类器。这是指定的类顺序很好的做法。假设每个预测是有条件的,正态分布给予它的标签。节省内存通过降低训练的SVM分类器的大小。
MDL = fitcnb(X(INDS,:),Y(INDS),...“类名”{'setosa',“花斑癣”,“弗吉尼亚”});CMDL =紧凑(MDL);谁是(“铜牌”,'CMDL')
名称大小字节类属性CMDL 1x1的5238 classreg.learning.classif.CompactClassificationNaiveBayes铜牌的1x1 12539 ClassificationNaiveBayes
该CompactClassificationNaiveBayes分类(CMDL)使用比更小的空间ClassificationNaiveBayes分类(MDL),因为后者存储数据。
预测标签,后验概率和预期类误判成本。由于真正的标签可用,比较它们与预测标签。
CMdl.ClassNames
ANS =3X1细胞{ 'setosa'} { '云芝'} { '锦葵'}
[标签,PostProbs,MisClassCost] =预测(CMDL,XNew);表(YNew,标签,PostProbs,'VariableNames',...{'TrueLabels','PredictedLabels',...'PosteriorProbabilities'})
ANS =10×3的表TrueLabels PredictedLabels PosteriorProbabilities ______________ _______________ _________________________________________ { 'setosa'} { 'setosa'} 1 4.1259e-16 1.1846e-23 { '云芝'} { '云芝'} 1.0373e-60 0.99999 5.8053e-06 { '锦葵'} {'锦葵'} 4.8708e-211 0.00085645 0.99914 { 'setosa'} { 'setosa'} 1 1.4053e-19 2.2672e-26 { '云芝'} { '云芝'} 2.9308e-75 0.99987 0.00012869 { 'setosa'}{ 'setosa'} 1 2.629e-18 4.4297e-25 { '云芝'} { '云芝'} 1.4238e-67 0.99999 9.733e-06 { '云芝'} { '云芝'} 2.0667e-110 0.94237 0.057625 {'setosa'} { 'setosa'} 1 4.3779e-19 3.5139e-26 { 'setosa'} { 'setosa'} 1 1.1792e-17 2.2912e-24
MisClassCost
MisClassCost =10×30.0000 1.0000 1.0000 1.0000 0.0000 1.0000 1.0000 0.9991 0.0009 0.0000 1.0000 1.0000 1.0000 0.0001 0.9999 0.0000 1.0000 1.0000 1.0000 0.0000 1.0000 1.0000 0.0576 0.9424 0.0000 1.0000 1.0000 0.0000 1.0000 1.0000
PostProbs和MisClassCost是15-通过-3数字矩阵,其中每一行对应于一个新的观察和每列对应于一个类。列的顺序对应的顺序CMdl.ClassNames。
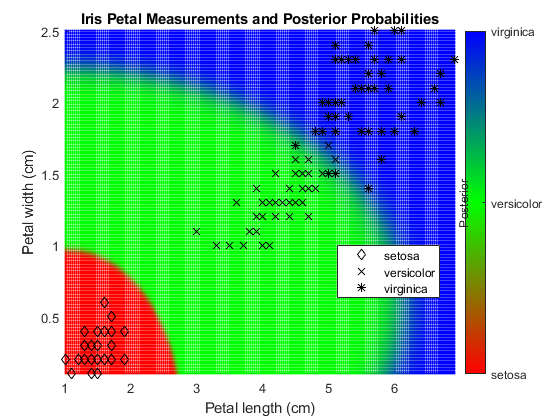
剧情后验概率为区域朴素贝叶斯分类
加载费舍尔的虹膜数据集。培养使用花瓣的长度和宽度的分类器。
加载fisheririsX = MEAS(:,3:4);Y =物种;
训练朴素贝叶斯分类器。这是指定的类顺序很好的做法。假设每个预测是有条件的,正态分布给予它的标签。
MDL = fitcnb(X,Y,...“类名”{'setosa',“花斑癣”,“弗吉尼亚”});
MDL是ClassificationNaiveBayes模型。你可以使用点符号访问其属性。
限定在所观察到的预测器空间值的网格。预测后验概率为网格中的每个实例。
XMAX = MAX(X);XMIN =分钟(X);H = 0.01;[x1Grid,x2Grid] = meshgrid(XMIN(1):H:XMAX(1),XMIN(2):H:XMAX(2));[〜,PosteriorRegion] =预测(MDL,[x1Grid(:),x2Grid(:)]);
剧情后验概率地区和训练数据。
数字;%绘制后部区域散射(x1Grid(:),x2Grid(:),1,PosteriorRegion);%调整颜色栏选项H =彩条;h.Ticks = [0 0.5 1];h.TickLabels = {'setosa',“花斑癣”,“弗吉尼亚”};h.YLabel.String =“后路”;h.YLabel.Position = [-0.5 0.5 0];%调整颜色地图选项d = 1E-2;CMAP =零(201,3);CMAP(1:101,1)= 1:-d:0;CMAP(1:201,2)= [0:d:1 1-d:-d:0];CMAP(101:201,3)= 0:d:1;颜色表(CMAP);%绘制数据保持上GH = gscatter(X(:,1),X(:,2)中,Y,数k,'DX *');标题“虹膜花瓣测量和后验概率”;xlabel'花瓣长度(cm)';ylabel“花瓣宽度(厘米)”;轴紧传说(GH,'位置','最好')保持离
更多关于
参考
[1] Hastie的,T.,R. Tibshirani,和J.弗里德曼。统计学习的要素, 第二版。纽约:施普林格,2008年。
扩展功能
您还可以选择从下面的列表中的网站:
