fitcsvm
训练支持向量万博1manbetx机(SVM)分类器的单类和二元分类
语法
描述
fitcsvm在低维或中维预测器数据集上训练或交叉验证支持向量机(SV万博1manbetxM)模型,用于单类和两类(二进制)分类。fitcsvm万博1manbetx支持使用核函数映射预测器数据,支持顺序最小优化(SMO),迭代单数据算法(ISDA),或l1利用二次规划实现目标函数最小化的软裕度最小化。
训练线性支持向量机模型对高维数据集,即包含许多预测变量的数据集进行二元分类,使用fitclinear代替。
对于组合二进制支持向量机模型的多类学习,使用错误校正输出码(ECOC)。有关更多细节,请参见fitcecoc.
要训练支持向量机回归模型,请参见fitrsvm对于低维和中维预测器数据集,或fitrlinear对于高维数据集。
Mdl= fitcsvm (资源描述,ResponseVarName)Mdl使用表中包含的样例数据进行训练资源描述.ResponseVarName变量的名称是否在资源描述它包含单类或双类分类的类标签。
例子
训练支持向量机分类器
载入费雪的虹膜数据集。去除萼片的长度和宽度和所有观察到的濑花虹膜。
负载fisheririsInds = ~strcmp(物种,“setosa”);X = meas(inds,3:4);Y =物种(inds);
使用处理过的数据集训练SVM分类器。
SVMModel = fitcsvm(X,y)
SVMModel = ClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'versicolor' 'virginica'} ScoreTransform: 'none' NumObservations: 100 Alpha: [24x1 double] Bias: -14.4149 KernelParameters: [1x1 struct] BoxConstraints: [100x1 double] ConvergenceInfo: [1x1 struct] Is万博1manbetxSupportVector: [100x1 logical] Solver: 'SMO' Properties, Methods
SVMModel是经过训练的ClassificationSVM分类器。显示属性SVMModel.例如,要确定类顺序,可以使用点表示法。
classOrder = SVMModel。一会
classOrder =2 x1细胞{'versicolor'} {'virginica'}
第一节课(“多色的”)为负类,第二类(“virginica”)是积极的阶级。方法可以在训练期间更改类顺序“类名”名称-值对参数。
绘制数据的散点图并圈出支持向量。万博1manbetx
sv = svmmodel 万博1manbetx. supportvector;图gscatter(X(:,1),X(:,2),y)保持在情节(sv (: 1), sv (:, 2),“柯”,“MarkerSize”10)传说(“多色的”,“virginica”,“万博1manbetx支持向量”)举行从
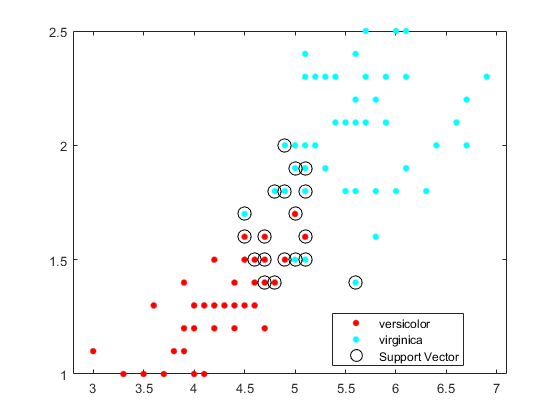
支持向量万博1manbetx是发生在估计类边界或超出估计类边界的观察值。
方法在训练期间设置框约束,可以调整边界(以及支持向量的数量)万博1manbetx“BoxConstraint”名称-值对参数。
训练和交叉验证SVM分类器
加载电离层数据集。
负载电离层rng (1);%用于重现性
使用径向基核训练SVM分类器。让软件为内核函数找到一个缩放值。标准化预测器。
SVMModel = fitcsvm(X,Y,“标准化”,真的,“KernelFunction”,“RBF”,...“KernelScale”,“汽车”);
SVMModel是经过训练的ClassificationSVM分类器。
交叉验证SVM分类器。默认情况下,该软件使用10次交叉验证。
CVSVMModel = crossval(SVMModel);
CVSVMModel是一个ClassificationPartitionedModel旨在分类器。
估计样本外误分类率。
classLoss = kfoldLoss(CVSVMModel)
classLoss = 0.0484
泛化率约为5%。
使用支持向量机和单类学习检测异常值
修改Fisher的虹膜数据集,将所有虹膜分配到同一类。在修改后的数据集中检测异常值,并确定异常值所占观测值的预期比例。
载入费雪的虹膜数据集。去掉花瓣的长度和宽度。把所有的鸢尾都当作来自同一类。
负载fisheririsX = meas(:,1:2);y = ones(size(X,1),1);
使用修改后的数据集训练SVM分类器。假设5%的观测值是异常值。标准化预测器。
rng (1);SVMModel = fitcsvm(X,y,“KernelScale”,“汽车”,“标准化”,真的,...“OutlierFraction”, 0.05);
SVMModel是经过训练的ClassificationSVM分类器。默认情况下,软件使用高斯内核进行单类学习。
绘制观察结果和决策边界。标记支持向量和潜在万博1manbetx异常值。
svInd = svm . issup万博1manbetxportvector;H = 0.02;%网格步长[X1,X2] = meshgrid(min(X(:,1)):h:max(X(:,1)),...min (X (:, 2)): h:马克斯(X (:, 2)));[~,score] = predict(SVMModel,[X1(:),X2(:)]);scoreGrid = shape(score,size(X1,1),size(X2,2));图绘制(X (: 1), (:, 2),“k”。)举行在情节(X (svInd, 1), X (svInd, 2),“罗”,“MarkerSize”,10)轮廓(X1,X2,scoreGrid)颜色栏;标题({\bf基于单类支持向量机的虹膜离群值检测})包含(“萼片长度(厘米)”) ylabel (“萼片宽度(厘米)”)传说(“观察”,“万博1manbetx支持向量”)举行从

将异常值与其余数据分隔开的边界出现在轮廓值所在的位置0.
验证交叉验证数据中阴性分数的观测值的比例接近5%。
CVSVMModel = crossval(SVMModel);[~,scorePred] = kfoldPredict(CVSVMModel);outlierRate = mean(scorePred<0)
outlierRate = 0.0467
利用二值支持向量机寻找多个类边界
创建一个散点图fisheriris数据集。将图中网格的坐标视为来自数据集分布的新观察值,并通过将坐标分配给数据集中的三个类中的一个来查找类边界。
载入费雪的虹膜数据集。用花瓣的长度和宽度作为预测因子。
负载fisheririsX = meas(:,3:4);Y =物种;
检查数据的散点图。
图gscatter (X (: 1), (:, 2), Y);H = gca;Lims = [h;Xl我米h.YLim];提取x轴和y轴的限制标题('{\bf虹膜测量散点图}');包含(“花瓣长度(厘米)”);ylabel (“花瓣宽度(厘米)”);传奇(“位置”,“西北”);
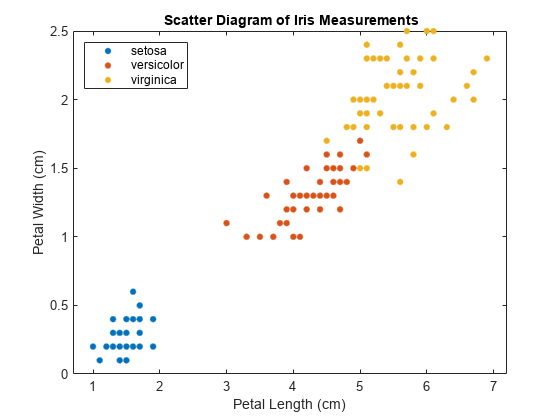
该数据包含三类,其中一类是线性可分的。
每个班级:
创建一个逻辑向量(
indx)表示观察结果是否属于该类。使用预测器数据和训练支持向量机分类器
indx.将分类器存储在单元格数组的单元格中。
定义类顺序。
SVMModels = cell(3,1);类=唯一的(Y);rng (1);%用于重现性为j = 1:numel(classes) indx = strcmp(Y,classes(j));为每个分类器创建二进制类SVMModels{j} = fitcsvm(X,indx,“类名”(虚假的真实),“标准化”,真的,...“KernelFunction”,“rbf”,“BoxConstraint”1);结束
SVMModels是3 × 1单元格数组,每个单元格包含ClassificationSVM分类器。对于每个细胞,阳性类分别是setosa, versicolor和virginica。
在图中定义一个精细网格,并将坐标视为来自训练数据分布的新观察值。使用每个分类器估计新观察结果的得分。
D = 0.02;[x1Grid, x2Grid] = meshgrid (min (X (: 1)): d:马克斯(X (: 1))...min (X (:, 2)): d:马克斯(X (:, 2)));xGrid = [x1Grid(:),x2Grid(:)];N = size(xGrid,1);Scores = 0 (N,numel(classes));为j = 1:numel(classes) [~,score] = predict(svm模型{j},xGrid);Scores(:,j) = score(:,2);%第二列包含积极的班级分数结束
每一行分数包含三个分数。得分最大的元素的索引是新类观察最有可能属于的类的索引。
将每个新的观察结果与给出最高分的分类器关联起来。
[~,maxScore] = max(Scores,[],2);
根据对应的新观察结果所属的类别,在图的区域中设置颜色。
图h(1:3) = gscatter(xGrid(:,1),xGrid(:,2),maxScore,...[0.1 0.5 0.5;0.5 0.1 0.5;0.5 0.5 0.1]);持有在h(4:6) = gscatter(X(:,1),X(:,2),Y);标题('{\bf虹膜分类区域}');包含(“花瓣长度(厘米)”);ylabel (“花瓣宽度(厘米)”);传奇(h, {“setosa地区”,“杂色的地区”,“virginica地区”,...“观察setosa”,的观察到的多色的,“观察virginica”},...“位置”,“西北”);轴紧持有从
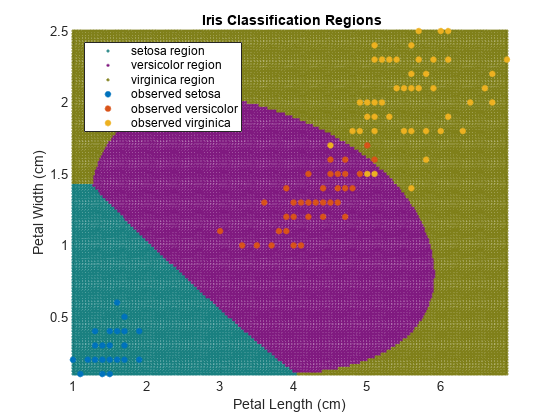
优化SVM分类器
自动优化超参数使用fitcsvm.
加载电离层数据集。
负载电离层
通过使用自动超参数优化找到最小化五倍交叉验证损失的超参数。为了再现性,设置随机种子并使用“expected-improvement-plus”采集功能。
rng默认的Mdl = fitcsvm(X,Y,“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,...“expected-improvement-plus”))
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| |运行时| | (estim(观察) .) | | | |=====================================================================================================| | 最好1 | | 0.21652 | 17.039 | 0.21652 | 0.21652 | 64.836 | 0.0015729 |
| 2 |接受| 0.35897 | 0.07617 | 0.21652 | 0.22539 | 0.036335 | 5.5755 |
| 3 |最佳|.13105 | 6.632 | 0.13105 | 0.14152 | 0.0022147 | 0.0023957 |
| 4 |接受| 0.35897 | 0.074778 | 0.13105 | 0.13108 | 5.1259 | 98.62 |
| 5 |接受| 0.1339 | 13.599 | 0.13105 | 0.13111 | 0.0011599 | 0.0010098 |
| 6 |接受| 0.13105 | 3.171 | 0.13105 | 0.13106 | 0.0010151 | 0.0045756 |
| 7 |最佳|.12821 | 8.4294 | 0.12821 | 0.12819 | 0.0010563 | 0.0022307 |
| 8 |接受| 0.1339 | 10.901 | 0.12821 | 0.13013 | 0.0010113 | 0.0026572 |
| 9 |接受| 0.12821 | 6.1095 | 0.12821 | 0.12976 | 0.0010934 | 0.0022461 |
| 10 |接受| 0.12821 | 3.646 | 0.12821 | 0.12933 | 0.0010315 | 0.0023551 |
| 11 |接受| 0.1396 | 16.231 | 0.12821 | 0.12954 | 994.04 | 0.20756 |
| 12 |接受| 0.13105 | 15.216 | 0.12821 | 0.12945 | 20.145 | 0.044584 |
| 13 |接受| 0.21368 | 17.538 | 0.12821 | 0.12787 | 903.79 | 0.056122 |
| 14 |接受| 0.1339 | 0.25382 | 0.12821 | 0.12939 | 0.018688 | 0.038639 |
| 15 |接受| 0.12821 | 2.712 | 0.12821 | 0.1295 | 5.6464 | 0.15938 |
| 16 |接受| 0.13675 | 9.392 | 0.12821 | 0.12798 | 0.5485 | 0.020716 |
| 17 |接受| 0.12821 | 6.1911 | 0.12821 | 0.12955 | 1.2899 | 0.063233 |
| 18 |接受| 0.1339 | 9.0842 | 0.12821 | 0.12957 | 869.51 | 0.94889 |
| 19 |接受| 0.13675 | 9.2152 | 0.12821 | 0.12957 | 112.89 | 0.31231 |
| 20 |接受| 0.13105 | 0.09432 | 0.12821 | 0.12958 | 0.0010803 | 0.03695 |
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| |运行时| | (estim(观察) .) | | | |=====================================================================================================| | 21日|接受| 0.13675 | 9.1747 | 0.12821 | 0.1299 | 7.7299 | 0.076169 |
| 22最佳|.12536 | 0.14985 | 0.12536 | 0.13007 | 0.0010485 | 0.013248 |
| 23 |接受| 0.20228 | 16.954 | 0.12536 | 0.12548 | 0.060212 | 0.0010323 |
| 24 |接受| 0.1339 | 0.21183 | 0.12536 | 0.12556 | 0.30698 | 0.16097 |
| 25 |接受| 0.1339 | 14.522 | 0.12536 | 0.12923 | 963.05 | 0.5183 |
| 26 |接受| 0.13675 | 0.24834 | 0.12536 | 0.12888 | 0.0039748 | 0.015475 |
| 27 |接受| 0.1339 | 1.4307 | 0.12536 | 0.12889 | 0.33582 | 0.066787 |
| 28 |接受| 0.1339 | 14.534 | 0.12536 | 0.12884 | 4.2069 | 0.032774 |
| 0.12536 | 0.11308 | 0.12536 | 0.12658 | 0.0010233 | 0.017839 |
| 0.12536 | 0.12514 | 0.12536 | 0.12579 | 0.0010316 | 0.019592 |
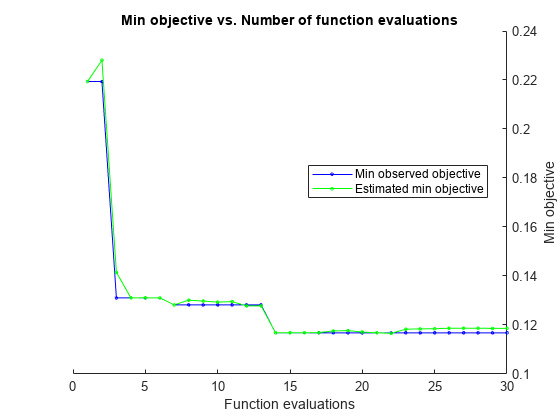

__________________________________________________________ 优化完成。最大目标:达到30。总运行时间:234.177秒。最佳可行观测点:BoxConstraint KernelScale _____________ ___________ 0.0010233 0.017839观测目标函数值= 0.12536估计目标函数值= 0.12579函数评估时间= 0.11308最佳估计可行点(根据模型):BoxConstraint KernelScale _____________ ___________ 0.0010233 0.017839估计目标函数值= 0.12579估计函数评估时间= 0.13623
Mdl = ClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' 'g'} ScoreTransform: 'none' NumObservations: 351 HyperparameterOptimizationResults: [1×1 BayesianOptimization] Alpha: [91×1 double] Bias: -5.6976 KernelParameters: [1×1 struct] BoxConstraints: [351×1 double] ConvergenceInfo: [1×1 struct] Is万博1manbetxSupportVector: [351×1 logical] Solver: 'SMO'属性,方法
输入参数
输出参数
限制
fitcsvm训练支持向量机分类器用于单类或两类学习应用。若要使用包含两个以上类的数据训练支持向量机分类器,请使用fitcecoc.fitcsvm万博1manbetx支持低维和中维数据集。对于高维数据集,使用fitclinear代替。
更多关于
提示
除非您的数据集很大,否则总是尝试将预测器标准化(参见
标准化).标准化使得预测器对它们所测量的尺度不敏感。交叉验证是一个很好的实践
KFold名称-值对参数。交叉验证结果决定了SVM分类器的泛化程度。单类学习:
支持向量的稀疏性是支持向万博1manbetx量机分类器的一个理想属性。若要减少支持向量的数量,请设置万博1manbetx
BoxConstraint到一个较大的值。这个操作增加了训练时间。为最佳训练时间,设置
CacheSize尽可能高的内存限制您的计算机允许。如果您期望的支持向量比训练集中的观察值要少得多,那万博1manbetx么您可以使用名称-值对参数缩小活动集,从而显著加快收敛速度
“ShrinkagePeriod”.指定是一个很好的实践“ShrinkagePeriod”,1000年.远离决策边界的重复观察结果不会影响收敛。然而,只要在决策边界附近出现一些重复的观察结果,就会大大减慢收敛速度。要加快收敛速度,请指定
“RemoveDuplicates”,真的如果:你的数据集包含许多重复的观察结果。
您怀疑一些重复的观察落在决策边界附近。
为了在训练期间保持原始数据集,
fitcsvm必须临时存储不同的数据集:原始数据集和没有重复观测的数据集。因此,如果指定真正的对于包含少量副本的数据集,那么fitcsvm消耗的内存接近原始数据的两倍。在训练一个模型之后,您可以生成预测新数据标签的C/ c++代码。生成C/ c++代码需要MATLAB编码器™.详情请参见代码生成简介.
算法
支持向量机二元分类算法的数学公式见万博1manbetx二值分类的支持向量机和理解支持向量机万博1manbetx.
南,<定义>,空字符向量(”,空字符串(""),< >失踪值表示缺失值。fitcsvm删除与丢失响应对应的整行数据。在计算总权重时(见下一个项目),fitcsvm忽略与至少一个缺失预测因子的观察结果相对应的任何权重。在平衡类问题中,这种行为会导致不平衡先验概率。因此,观察箱的约束可能不相等BoxConstraint.fitcsvm去除权值为零或先验概率为零的观测值。对于两类学习,如果你指定成本矩阵 (见
成本),然后软件更新类先验概率p(见之前)pc通过合并在 .具体地说,
fitcsvm完成以下步骤:计算
正常化pc*所以更新后的先验概率和为1。
K是类的数量。
重置成本矩阵为默认值
从先验概率为零的类对应的训练数据中去除观察值。
对于两类学习,
fitcsvm标准化所有的观察权重(参见权重)加起来为1。然后,该函数将归一化的权值重新归一化,使其之和为观测值所属类的更新先验概率。也就是观察的总权重j在课堂上k是wj归一化权值是否用于观察j;pc,k是类的更新先验概率吗k(见前面的项目)。
对于两类学习,
fitcsvm为训练数据中的每个观察值分配一个框约束。观察框约束的公式j是n是训练样本量,C0初始框约束(参见
“BoxConstraint”名称-值对参数),和 观察的总权重是多少j(见前面的项目)。如果你设置
“标准化”,真的和“成本”,“之前”,或“重量”那么,名称-值对参数fitcsvm使用相应的加权平均数和加权标准差对预测因子进行标准化。也就是说,fitcsvm标准化预测j(xj)使用xjk是观察k(行)的预测器j(列)。
假设
p你在训练数据中期望的异常值的比例,和你设置的异常值的比例OutlierFraction, p.对于单类学习,软件训练偏差项使100
p训练数据中%的观察结果为负值。软件实现强劲的学习对于两类学习。换句话说,该软件试图删除100个
p优化算法收敛时观测值的%。被删除的观测值对应于量级较大的梯度。
如果你的预测数据包含分类变量,那么软件通常对这些变量使用全虚拟编码。该软件为每个类别变量的每一级创建一个虚拟变量。
的
PredictorNames属性为每个原始预测器变量名存储一个元素。例如,假设有三个预测器,其中一个是具有三个级别的类别变量。然后PredictorNames是包含预测器变量的原始名称的字符向量的1 × 3单元格数组。的
ExpandedPredictorNames属性为每个预测器变量(包括虚拟变量)存储一个元素。例如,假设有三个预测器,其中一个是具有三个级别的类别变量。然后ExpandedPredictorNames是一个1 × 5的字符向量单元格数组,其中包含预测变量和新的虚拟变量的名称。类似地,
β属性为每个预测器(包括虚拟变量)存储一个beta系数。的
万博1manbetxSupportVectors属性存储支持向量(包括虚拟变量)的预测器值。万博1manbetx例如,假设有米万博1manbetx支持向量和三个预测因子,其中一个是三级分类变量。然后万博1manbetxSupportVectors是一个n5矩阵。的
X属性将训练数据作为原始输入存储,不包含虚拟变量。当输入是一个表时,X只包含用作预测器的列。
对于表中指定的预测器,如果任何变量包含有序(序数)类别,则软件对这些变量使用序数编码。
对于一个变量k软件会创建有序的关卡k- 1虚拟变量。的j虚变量为1适用于以下级别j,+1的水平j+ 1通过k.
对象中存储的虚拟变量的名称
ExpandedPredictorNames属性用值指示第一个级别+1.软件商店k- 1虚拟变量的其他预测器名称,包括级别2、3、…k.
所有求解器实现l1 .软边际最小化。
对于单类学习,软件估计拉格朗日乘数,α1、……αn,以致于
参考文献
[1] Christianini, N.和J. C. Shawe-Taylor。支持向量机和其他基于核的学习方法简介万博1manbetx.英国剑桥:剑桥大学出版社,2000年。
[2]风扇,r.e。,林志信。和c.j。林。用二阶信息选择工作集来训练支持向量机。万博1manbetx机器学习研究杂志, 2005年第6卷,1889-1918页。
[3]哈斯蒂,T., R.蒂布希拉尼,J.弗里德曼。统计学习的要素,第二版。纽约:施普林格,2008。
凯克曼V., t。黄和M.沃格特。从巨大数据集训练核机器的迭代单数据算法:理论和性能。万博1manbetx支持向量机:理论与应用.王立波主编,255-274。柏林:Springer-Verlag, 2005。
[5]肖科普夫,B. J. C.普拉特,J. C.肖-泰勒,A. J.斯莫拉,R. C.威廉姆森。"估计高维分布的支持度"万博1manbetx神经第一版, 2001年第13卷第7期,第1443-1471页。
[6] Scholkopf, B.和A. Smola。用核学习:支持向量机,正则化,优化和超越,自适万博1manbetx应计算和机器学习.马萨诸塞州剑桥:麻省理工学院出版社,2002年。
扩展功能
另请参阅
ClassificationPartitionedModel|ClassificationSVM|CompactClassificationSVM|fitSVMPosterior|fitcecoc|fitclinear|预测|quadprog|rng
在R2014a中介绍
您也可以从以下列表中选择网站:
