万博1manbetx支持向量机的二元分类
理解支持向量机万博1manbetx
可分离数据
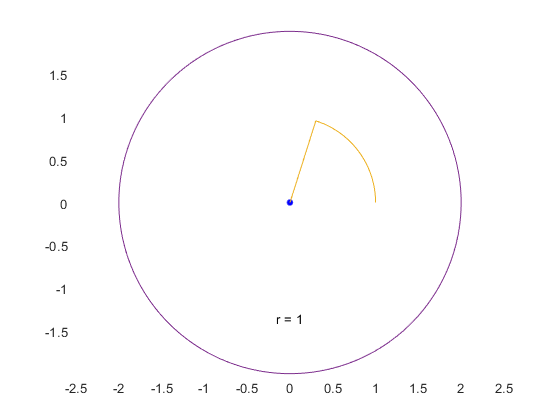
您可以使用您的数据正好有两类万博1manbetx支持向量机(SVM)。通过发现分离一类的所有数据点与其它类的最佳超平面的SVM数据分类。该最好超平面为SVM是指具有最大余量两个类之间。余量指平行于不具有内部数据点的超平面板坯的最大宽度。
该万博1manbetx支持向量是最靠近分离超平面的数据点;这些点是边界楼板上。下图说明这些定义,与+表示类型1的数据点,以及 - 指示类型-1的数据点。

数学公式:原始。这个讨论如下黑斯蒂,Tibshirani和弗里德曼[1]和Christianini和Shawe泰勒[2]。
训练的数据是一组点(向量)XĴ连同其类别ÿĴ。对于某些维度d中,XĴ∊[Rd和ÿĴ=±1。超平面的计算公式
哪里β∊[Rd和b是一个实数。
下面的问题定义最好分离超平面(即,决策边界)。找β和b这最小化| |β||使得对所有的数据点(XĴ,ÿĴ),
支持向量万博1manbetx是XĴ的边界上,那些其
对于数学上的方便,这个问题通常是给出最小化的问题,相当于 。这是一个二次规划问题。最优解 使矢量的分类ž如下:
是个分类分和表示距离ž从决策边界。
数学公式:双。它是计算简单,解决了双二次规划问题。为了获得双,采取积极的拉格朗日乘子αĴ乘以每个约束,并且从所述目标函数中减去:
在那里你找一个固定点大号P在β和b。设置的梯度大号P为0,你就会得到
| (1) |
代入大号P,你得到的双大号d:
您在最大化αĴ≥0。一般来说,许多αĴ在最大为0。非零αĴ在溶液中,以对偶问题定义超平面,如在可见式(1), 这使β作为总和αĴÿĴXĴ。数据点XĴ对应于非零αĴ是万博1manbetx支持向量。
的导数大号d相对于非零αĴ在最优条件下为0。这给了
特别是,它给出的值b在解处,取任意Ĵ与非零αĴ。
对偶是一个标准的二次规划问题。例如,优化工具箱™quadprog解决者解决这类问题。
数据不可分
您的数据可能不会允许分离超平面。在这种情况下,SVM可以使用软间隔,这意味着一个超平面分开很多,但不是所有的数据点。
有软利润率的两个标准配方。两者都涉及添加松弛变量ξĴ和惩罚参数C。
该大号1范数的问题是:
这样
该大号1-norm是指使用ξĴ为松弛变量,而不是它们的平方。这三个选项求解
SMO,ISDA,L1QP的fitcsvm最小化大号1范数的问题。该大号2范数的问题是:
受制于同样的约束。
在这些制剂中,你可以看到增加C更重视松弛变量ξĴ,这意味着优化试图使类之间的严格分离。同样地,减少C对0品牌误判不那么重要了。
数学公式:双。为了方便计算,考虑大号1偶问题这个软保证金配方。使用拉格朗日乘子μĴ的最小值函数大号1范数的问题是:
在那里你找一个固定点大号P在β,b和积极的ξĴ。设置的梯度大号P为0,你就会得到
这些方程直接导出了对偶公式:
受限制
最后一组的不平等,0≤αĴ≤C显示,为什么C有时也被称为箱约束。C保持拉格朗日乘子的允许值αĴ在“盒子”,有界区域。
的梯度方程b给出了解决方案b在一组非零的方面αĴ,其对应于所述支持向量。万博1manbetx
你可以写出和解决的对偶大号2以类似的方式范数的问题。有关详细信息,请参阅Christianini和Shawe泰勒[2]第六章。
fitcsvm实现。两个双软保证金问题是二次规划问题。在内部,fitcsvm有几种不同的算法来解决这些问题。
对于一类或两类分类,如果您没有设置在数据预期异常值的一小部分(见
OutlierFraction),那么默认求解器序列最小优化(SMO)。SMO通过一系列两点minimizations的最小化的范数的问题。在优化过程中,SMO尊重线性约束 并明确包括在模型中的偏项。SMO是比较快的。有关SMO的详细信息,请参阅[3]。对于二元分类,如果在数据集预计离群的一小部分,那么默认的求解是迭代单一数据算法。像SMO,ISDA解决了一个标准的问题。不像SMO,通过在一个点minimizations一系列ISDA最小化,不尊重线性约束,并且不显式地包括在模型中的偏差项。有关ISDA更多详细信息,请参阅[4]。
对于单类或二进制分类,如果您拥有优化工具箱许可证,则可以选择使用
quadprog解决了一个标准的问题。quadprog使用的内存很好的协议,但到高精确度的解决了二次规划问题。有关详细信息,请参阅二次规划定义(优化工具箱)。
带核的非线性变换
一些二进制分类问题没有一个简单的超平面作为一个有用的分离标准。对于这些问题,有保留了几乎所有的SVM分类超平面的简单的数学方法的变体。
这种方法使用了来自内核再生理论的这些结果:
有一类函数G(X1,X2)具有以下属性。存在线性空间小号和功能φ映射X至小号这样
G(X1,X2)= <φ(X1),φ(X2) >。
点积发生在空间小号。
这类函数包括:
多项式:对于一些正整数p,
G(X1,X2) = (1 +X1“X2)p。
径向基函数(高斯):
G(X1,X2)= EXP(-∥X1-X2)∥2)。
多层感知或乙状结肠(神经网络):对于正数p1和负数p2,
G(X1,X2)=的tanh(p1X1“X2+p2)。
注意
不是每一套p1和p2产生有效的再生核。
fitcsvm不支持乙状结肠内核万博1manbetx。相反,你可以定义乙状结肠内核,并使用指定它“KernelFunction”名称-值对的论点。有关详细信息,请参见使用自定义核训练SVM分类器。
使用核的数学方法依赖于超平面的计算方法。所有超平面分类的计算只使用点积。s manbetx 845因此,非线性核可以使用相同的计算和求解算法,得到非线性的分类器。得到的分类器是某些空间中的超曲面小号,但空间小号不需要识别或检查。
支持向量机万博1manbetx
正如任何监督的学习模式,首先训练支持向量机,然后交叉验证分类。万博1manbetx使用训练的机器进行分类(预测)的新数据。此外,为了获得满意的预测准确性,您可以使用各种SVM内核函数,你必须调整的内核函数的参数。
训练SVM分类
火车,并任选地交验证,使用SVM分类fitcsvm。最常见的语法是:
SVMModel = fitcsvm(X,Y, 'KernelFunction', 'RBF',... '标准化',真, '类名',{ 'negClass', 'posClass'});
输入是:
X-预测数据矩阵,其中每行为一个观测值,每列为一个预测值。ÿ-类标签的数组,其中每一行对应于中对应行的值X。ÿ可以是分类,字符或字符串数组,逻辑或数字载体,或字符向量的单元阵列。KernelFunction- 默认值是“线性”对于两班学习,这由超平面的数据分离。价值“高斯”(要么“rbf”)是单类学习的默认值,指定使用高斯(或径向基函数)核函数。成功训练SVM分类器的一个重要步骤是选择合适的核函数。标准化-在训练分类器之前,软件是否需要对预测器进行标准化的标志。类名-区分消极类和积极类,或指定在数据中包含哪些类。负类是第一个元素(或字符数组的第一行),例如,'negClass',阳性类是第二元件(或行的字符阵列的),例如,'posClass'。类名数据类型必须与ÿ。这是指定的类名很好的做法,特别是如果你是比较不同的分类器的性能。
产生的,训练模型(SVMModel)包含从SVM算法优化的参数,使您对新数据进行分类。
欲了解更多名称 - 值对,你可以用它来控制训练,看fitcsvm参考页。
新的分类与SVM分类数据
使用新的分类数据预测。对于分类使用已训练SVM分类新数据的语法(SVMModel)是:
[标号,得分=预测(SVMModel,下一页末);
所得载体标签中的每一行的分类X。得分是一个ñ-by-2软分数矩阵。每一行对应的行X,这是一个新的观察。第一列包含被分类在负类的分数的意见,而第二列包含被分类在正类的得分观测。
为了估计的后验概率,而不是分数,先通过训练的SVM分类器(SVMModel)fitPosterior,该嵌合的得分 - 后概率变换函数到分数。语法是:
ScoreSVMModel = fitPosterior (SVMModel, X, Y);
房地产ScoreTransform的分类器ScoreSVMModel包含最佳的转换功能。通过ScoreSVMModel至预测。而不是返回的分数,输出参数得分包含一个观测值的后验概率被分类在负(第1列得分)或正的(的第二列)得分)类。
调整SVM分类
使用“OptimizeHyperparameters”的名称-值对参数fitcsvm找到的参数值,最大限度地减少了交叉验证的损失。符合条件的参数'BoxConstraint',“KernelFunction”,'KernelScale','PolynomialOrder',“标准化”。例如,看到的优化SVM分类适合使用贝叶斯优化。另外,您也可以使用bayesopt功能,如图优化交叉验证SVM分类使用bayesopt。该bayesopt功能允许更灵活的定制优化。您可以使用bayesopt功能优化所有参数,包括不符合资格的参数,当您使用的优化fitcsvm函数。
你也可以尝试分类的调整参数手动根据该方案:
数据传递到
fitcsvm,并设置名称 - 值对参数'KernelScale', '汽车'。假设训练的SVM模型被称为SVMModel。该软件使用启发式方法来选择内核的规模。启发式过程使用二次抽样。因此,为了再现结果,使用设定的随机数种子rng在训练分类器之前。十字通过它传递给验证分类
crossval。默认情况下,该软件进行10倍交叉验证。通过交叉验证的SVM模型,得到
kfoldLoss估计和保留分类误差。重新训练SVM分类,但调整
'KernelScale'和'BoxConstraint'名称-值对参数。BoxConstraint- 一个策略是尝试盒子约束参数的等比数列。例如,取11度的值,从1E-5至1E5通过10倍增加BoxConstraint可能会降低支持向量的数量,而且还可能会增加训练时间。万博1manbetxKernelScale-一种策略是尝试RBF sigma参数的几何序列按原始核尺度缩放。通过:检索原始内核的规模,例如,
ks,使用点符号:KS = SVMModel.KernelParameters.Scale。请使用与原始的新内核尺度因素。例如,乘法
ks由11个值1E-5至1E5,以10的倍数递增。
选择产生最低分类错误的模型。您可能要进一步细化参数,以获得更好的精度。开始与您的初始参数,并执行另一个交叉验证步骤,此时使用的1.2倍。
火车SVM分类使用高斯核
这个例子说明如何生成与高斯核函数的非线性分类。首先,生成一个类单位圆盘内部的点的在两个维度,并且在从半径为1的环带,以半径2.另一个类的点,生成基于与所述高斯径向基函数内核数据的分类器。默认的线性分类显然是不适合这个问题,因为该模型是圆形对称的。设置框约束参数天道酬勤要做一个严格的分类,意思是没有分类错误的训练点。其他内核函数可能无法使用这种严格的框约束,因为它们可能无法提供严格的分类。尽管rbf分类器可以分离类,但结果可能会过度训练。
生成100个点均匀分布在单元盘。要做到这一点,产生一个半径[R作为均匀随机变量的平方根,产生一个角Ť均匀地(0, ),并把在点([RCOS(Ť),[R罪(Ť))。
RNG(1);%用于重现R = SQRT(兰特(100,1));%半径T = 2 * PI *兰特(100,1);角%DATA1 = [R * COS(T)中,r * SIN(t)的。];%要点
生成100点均匀分布在环。半径是再次成正比平方根,此时从1到4中的均匀分布的平方根。
R2 = SQRT(3 *兰特(100,1)+1);%半径T2 = 2 * PI *兰特(100,1);角%DATA2 = [R2 * COS(T2)中,R 2 * SIN(T2)。。];%点
绘制点,并绘制半径为1和2的圆进行比较。
图;情节(DATA1(:,1),DATA1(:,2),'R'。,'MarkerSize', 15)上情节(data2(: 1)、data2 (:, 2),'B'。,'MarkerSize',15)ezpolar(@(x)的1); ezpolar(@(X)2);轴等于保持从
将数据放入一个矩阵中,并做一个分类向量。
DATA3 = [DATA1; DATA2];theClass描述=酮(200,1);theClass描述(1:100)= -1;
火车与SVM分类KernelFunction设置为“rbf”和BoxConstraint设置为天道酬勤。画出决策边界和标志的支持向量。万博1manbetx
%训练SVM分类CL = fitcsvm(DATA3,theClass描述,“KernelFunction”,“rbf”,...'BoxConstraint',天道酬勤,“类名”[1]);%预测分数在网格d = 0.02;[x1Grid,x2Grid] = meshgrid(分钟(DATA3(:,1)):d:最大(DATA3(:,1)),...分钟(data3 (:, 2)): d:马克斯(data3 (:, 2)));xGrid = [x1Grid (:), x2Grid (:));[~,分数]=预测(cl, xGrid);%绘制数据和决策边界图;H(1:2)= gscatter(DATA3(:,1),数据3(:,2),theClass描述,'RB','');保持上ezpolar(@(x)的1);H(3)=图(DATA3(cl.IsSuppo万博1manbetxrtVector,1),数据3(cl.IsSupportVector,2),“柯”);轮廓(x1Grid,x2Grid,重塑(得分(:,2),尺寸(x1Grid)),[0 0],数k);图例(H,{' 1 ',“+ 1”,“万博1manbetx支持向量”});轴等于保持从

fitcsvm生成一个接近半径为1的圆的分类器。这种差异是由随机训练数据造成的。
使用默认参数,使训练更接近圆形的分类界限,而是一个misclassifies一些训练数据。此外,默认值BoxConstraint是1和,因此,有更多的支持向量。万博1manbetx
CL2 = fitcsvm(DATA3,theClass描述,“KernelFunction”,“rbf”);[〜,scores2] =预测(CL2,XGRID);图;H(1:2)= gscatter(DATA3(:,1),数据3(:,2),theClass描述,'RB','');保持上ezpolar(@(x)的1);H(3)=图(DATA3(cl2.IsSuppo万博1manbetxrtVector,1),数据3(cl2.IsSupportVector,2),“柯”);轮廓(x1Grid x2Grid,重塑(scores2(:, 2),大小(x1Grid)), [0 0),数k);图例(H,{' 1 ',“+ 1”,“万博1manbetx支持向量”});轴等于保持从

使用自定义核训练SVM分类器
这个例子说明了如何使用一个定制的内核功能,如乙状结肠内核,训练SVM分类,并调整定制的内核函数参数。
在单位圆内生成一组随机的点。将第一和第三象限的点标记为属于积极类,将第二和第四象限的点标记为属于消极类。
RNG(1);%用于重现N = 100;每个象限点的数量%R1 = SQRT(兰特(2 * N,1));%随机半径T1 =π/ 2 *兰特(N,1);(PI / 2 *兰特(N,1)+ PI)];%随机的角度为Q1和Q3X1 = [r1.*cos(t1) r1.*sin(t1)];极地%至笛卡尔转换R2 = SQRT(RAND(2 * N,1));T2 =π/ 2 *兰特(N,1)+ pi / 2之间;(PI / 2 *兰特(N,1)-pi / 2)];Q2和Q4的随机角度X2 = [R2 * COS(T2)R2 * SIN(T2)。。];X = [X1;X2];%预测因素Y =酮(4 * N,1);Y(2 * N + 1:结束)= -1;% 标签
图数据。
图;gscatter(X(:,1),X(:,2),Y);标题(“模拟数据散点图”)

写接受在特征空间作为输入两个矩阵,并且将它们转换为使用S形核革兰氏矩阵的函数。
函数G = mysigmoid(U,V)%Sigmoid核与斜率γ和截距c函数伽马= 1;c = 1;G =的tanh(γ-* U * V” + C);结束
这段代码保存为一个文件名为mysigmoid您MATLAB®路径。
列车采用S形核函数SVM分类。这是规范数据的良好做法。
Mdl1 = fitcsvm (X, Y,“KernelFunction”,“mysigmoid”,“标准化”,真正的);
Mdl1是ClassificationSVM分类器包含估计的参数。
图中的数据,并确定支持向量和决策边界。万博1manbetx
%计算分数在网格d = 0.02;网格的步长%[x1Grid, x2Grid] = meshgrid (min (X (: 1)): d:马克斯(X (: 1))...分(X(:,2)):d:最大(X(:,2)));xGrid = [x1Grid (:), x2Grid (:));%网格[〜,scores1] =预测(Mdl1,XGRID);%的分数图;h (1:2) = gscatter (X (: 1), (:, 2), Y);保持上H(3)=图(X(Mdl1.IsSuppo万博1manbetxrtVector,1),...X(Mdl1.Is万博1manbetxSupportVector,2),“柯”,'MarkerSize',10);%支万博1manbetx持向量轮廓(x1Grid,x2Grid,重塑(scores1(:,2),尺寸(x1Grid)),[0 0],数k);%决策边界标题(“带有决策边界的散点图”)图例({' 1 ','1',“万博1manbetx支持向量”},'位置','最好');保持从

您可以通过调整内核参数来改进决策边界的形状。这也可能降低样本内的误分类率,但是,您应该首先确定样本外的误分类率。
使用10倍交叉验证确定样本外误分类率。
CVMdl1 = crossval(Mdl1);misclass1 = kfoldLoss(CVMdl1);misclass1
misclass1 = 0.1375
外的样本的分类错误率是13.5%。
写另一个双曲线函数,但集γ= 0.5;。
函数G = mysigmoid2 (U, V)%Sigmoid核与斜率γ和截距c函数γ= 0.5;c = 1;G =的tanh(γ-* U * V” + C);结束
这段代码保存为一个文件名为mysigmoid2您MATLAB®路径。
列车采用调整后的乙状结肠内核另一SVM分类。绘制数据和所述判定区域,并确定出样品的最误判率。
Mdl2 = fitcsvm (X, Y,“KernelFunction”,“mysigmoid2”,“标准化”,真正的);[~, scores2] =预测(Mdl2 xGrid);图;h (1:2) = gscatter (X (: 1), (:, 2), Y);保持上h(3) =情节(X (Mdl2.IsSu万博1manbetxpportVector, 1),...X(Mdl2.Is万博1manbetxSupportVector,2),“柯”,'MarkerSize',10);标题(“带有决策边界的散点图”)轮廓(x1Grid,x2Grid,重塑(scores2(:,2),尺寸(x1Grid)),[0 0],数k);传说({' 1 ','1',“万博1manbetx支持向量”},'位置','最好');保持从CVMdl2 = crossval(MDL2);misclass2 = kfoldLoss(CVMdl2);misclass2
misclass2 = 0.0450

乙状结肠斜率调整后,新的决策边界似乎由超过66%,以提供更好的样本内配合,和交叉验证率合同。
优化SVM分类适合使用贝叶斯优化
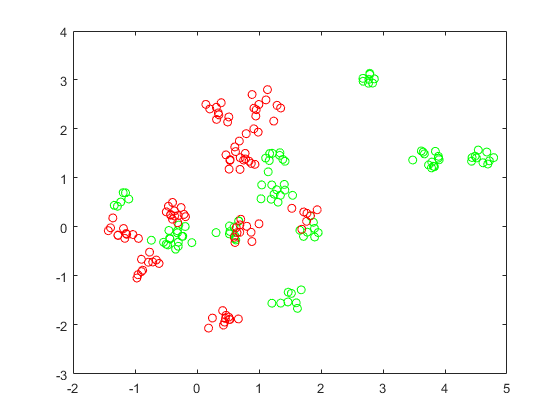
这个例子展示了如何使用属性优化SVM分类fitcsvm功能OptimizeHyperparameters名称 - 值对。分类工作从高斯混合模型点的位置。在统计学习的要素,黑斯蒂,Tibshirani和弗里德曼(2009年),第17页介绍了模型。该模型开始产生10个碱基点“绿色”类,分布式2- d独立法线与平均值(1,0)和单位方差。它也为“红色”类,分布式2- d独立法线与平均值(0,1)和单位方差生成10个基点。对于每个类(绿色和红色),产生100个随机点如下:
选择一个基点米的随机适当的颜色均匀。
生成与平均2 d的正态分布的独立随机点米方差I/5,其中I是2×2单位矩阵。在这个例子中,使用方差I/50来更清楚地显示优化的优势。
生成点和分类
产生用于每个类别的10点碱基的点。
rng默认%用于重现grnpop = mvnrnd([1,0],眼(2),10);redpop = mvnrnd([0,1],眼(2),10);
查看基点。
情节(grnpop(:,1),grnpop(:,2),'走')举行上情节(redpop(:,1),redpop(:,2),'RO')举行从

由于一些红色基点接近绿色的基点,它可能很难单独的基于位置的数据点进行分类。
生成每个类的100个数据点。
redpts =零(100,2); grnpts = redpts;为I = 1:100 grnpts(I,:) = mvnrnd(grnpop(兰迪(10),:),眼(2)* 0.02);redpts(I,:) = mvnrnd(redpop(兰迪(10),:),眼(2)* 0.02);结束
查看数据点。
图图(grnpts(:,1),grnpts(:,2),'走')举行上情节(redpts (: 1) redpts (:, 2),'RO')举行从
准备数据进行分类
把数据分成一个矩阵,并进行矢量grp该标签类中每个点的。
CDATA = [grnpts; redpts];GRP =酮(200,1);%绿色标签1,红色标签-1grp (101:200) = 1;
准备交叉验证
建立了交叉验证的分区。这一步解决列车组和测试组在每一步的优化使用。
c = cvpartition (200'KFold',10);
优化飞度
为了找到一个不错的选择,这意味着具有低交叉验证损失一个,设置选项使用贝叶斯优化。使用相同的交叉验证分区C在所有的优化。
为了重现性,使用“预计-改善,加上”采集功能。
OPTS =结构(“优化”,'bayesopt',“ShowPlots”,真正,'CVPartition'c...'AcquisitionFunctionName',“预计-改善,加上”);svmmod = fitcsvm(CDATA,GRP,“KernelFunction”,“rbf”,...“OptimizeHyperparameters”,'汽车','HyperparameterOptimizationOptions',OPTS)
| ===================================================================================================== ||ITER |EVAL |目的|目的|BestSoFar |BestSoFar |BoxConstraint |KernelScale | | | result | | runtime | (observed) | (estim.) | | | |=====================================================================================================| | 1 | Best | 0.345 | 0.51679 | 0.345 | 0.345 | 0.00474 | 306.44 |
| 2 b|最佳| 0.115 b| 0.18443 | 0.115 | 0.12678 | 430.31 | 1.4864 |
|3 |接受|0.52 |0.13467 |0.115 |0.1152 |0.028415 |0.014369 |
|4 |接受|0.61 |0.15058 |0.115 |0.11504 |133.94 |0.0031427 |
| 5 |接受| 0.34 | 0.14258 | 0.115 bb5 0.11504 | 0.010993 | 5.7742
|6 |最佳|0.085 |0.11448 |0.085 |0.085039 |885.63 |0.68403 |
|7 |接受|0.105 |0.093757 |0.085 |0.085428 |0.3057 |0.58118 |
|8 |接受|0.21 |0.097925 |0.085 |0.09566 |0.16044 |0.91824 |
| 9 |接受| 0.085 b| 0.12164 | 0.085 bb5 0.08725 | 972.19 | 0.46259 |
|10 |接受|0.1 |0.10145 |0.085 |0.090952 |990.29 |0.491 |
|11 |最佳|0.08 |0.12452 |0.08 |0.079362 |2.5195 |0.291 |
|12 |接受|0.09 |0.098778 |0.08 |0.08402 |14.338 |0.44386 |
|13 |接受|0.1 |0.098501 |0.08 |0.08508 |0.0022577 |0.23803 |
|14 |接受|0.11 |0.093424 |0.08 |0.087378 |0.2115 |0.32109 |
|15 |最佳|0.07 |0.11532 |0.07 |0.081507 |910.2 |0.25218 |
|16 |最佳|0.065 |0.11326 |0.065 |0.072457 |953.22 |0.26253 |
|17 |接受|0.075 |0.12262 |0.065 |0.072554 |998.74 |0.23087 |
|18 |接受|0.295 |0.11651 |0.065 |0.072647 |996.18 |44.626 |
|19 |接受|0.07 |0.12281 |0.065 |0.06946 |985.37 |0.27389 |
|20 |接受|0.165 |0.096372 |0.065 |0.071622 |0.065103 |0.13679 |
| = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = | | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| | |运行时(观察)| (estim) | | | | = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = | | | 21日接受| 0.345 | 0.094329 | 0.065 | 0.071764 | 971.7 | 999.01 |
| 22 |接受| 0.61 b| 0.10339 | 0.065 | 0.071967 | 0.0010168 | 0.0010005 |
|23 |接受|0.345 |0.09488 |0.065 |0.071959 |0.0010674 |999.18 |
| 24 |接受| 0.35 | 0.096074 | 0.065 bb5 0.071863 | 0.0010003 | 40.628 |
|接受| 0.24 b| 0.16217 | 0.065 bb5 0.072124 | 996.55 | 10.423 |
|26 |接受|0.61 |0.11167 |0.065 |0.072068 |958.64 |0.0010026 |
| 27 |接受| 0.47 | 0.10976 | 0.065 bb5 0.07218 | 993.69 | 0.029723
|28 |接受|0.3 |0.091906 |0.065 |0.072291 |993.15 |170.01 |
|接受| 0.16 | 0.25883 | 0.065 bb5 0.072104 | 992.81 | 3.8594 |
|30 |接受|0.365 |0.10465 |0.065 |0.072112 |0.0010017 |0.044287 |


__________________________________________________________优化完成。30 MaxObjectiveEvaluations达到。总功能评价:30总运行时间:30.3878秒。总目标函数评估时间:3.9881最佳观察到的可行点:BoxConstraint KernelScale _____________ ___________ 953.22 0.26253观测目标函数值= 0.065估计目标函数值= 0.073726功能评估时间= 0.11326最佳估计可行点(根据型号):BoxConstraint KernelScale _____________ ___________ 985.370.27389估计目标函数值= 0.072112估计函数评估时间= 0.11822
svmmod = ClassificationSVM ResponseName: 'Y' CategoricalPredictors:[]类名:[-1 1] ScoreTransform: '无' NumObservations:200个HyperparameterOptimizationResults:[1×1 BayesianOptimization]阿尔法:[77×1双]偏压:-0.2352 KernelParameters:1×1结构] BoxConstraints:[200×1双] ConvergenceInfo:[1×1结构] IsSupportVector:[200万博1manbetx×1逻辑]求解: 'SMO' 的属性,方法
找到最优化模型的损失。
lossnew = kfoldLoss (fitcsvm (grp cdata,'CVPartition'c“KernelFunction”,“rbf”,...'BoxConstraint',svmmod.HyperparameterOptimizationResults.XAtMinObjective.BoxConstraint,...'KernelScale',svmmod.HyperparameterOptimizationResults.XAtMinObjective.KernelScale))
lossnew = 0.0650
这种损失是一样下“所观察的目标函数值”优化输出挂失。
可视化优化的分类器。
d = 0.02;[x1Grid, x2Grid] = meshgrid (min (cdata (: 1)): d:马克斯(cdata (: 1)),...分钟(CDATA(:,2)):d:最大(CDATA(:,2)));xGrid = [x1Grid (:), x2Grid (:));[〜,分数] =预测(svmmod,XGRID);图;H =南(3,1);预分配%H(1:2)= gscatter(CDATA(:,1),CDATA(:,2),GRP,'RG',' + *’);保持上H(3)=图(CDATA(svmmod.IsSuppo万博1manbetxrtVector,1),...CDATA(svmmod.Is万博1manbetxSupportVector,2),“柯”);轮廓(x1Grid,x2Grid,重塑(得分(:,2),尺寸(x1Grid)),[0 0],数k);图例(H,{' 1 ',“+ 1”,“万博1manbetx支持向量”},'位置','东南');轴等于保持从

绘制SVM分类模型的后验概率区域
这个例子展示了如何在一个观察网格上预测SVM模型的后验概率,然后在网格上绘制后验概率。绘制后验概率暴露了决策边界。
加载Fisher的虹膜数据集。利用花瓣的长度和宽度训练分类器,并从数据中去除维吉尼亚树种。
负载fisheririsclassKeep = ~ strcmp(物种,“弗吉尼亚”);X = MEAS(classKeep,3:4);Y =物种(classKeep);
使用数据训练支持向量机分类器。指定类的顺序是一种很好的做法。
SVMModel = fitcsvm (X, y,“类名”{'setosa',“多色的”});
估计最优分数变换函数。
RNG(1);%用于重现[SVMModel,ScoreParameters] = fitPosterior(SVMModel);
警告:类是完全分开的。最佳得分 - 后变换是阶跃函数。
ScoreParameters
ScoreParameters =结构体字段:类型: '步' 下界:-0.8431 UPPERBOUND:0.6897 PositiveClassProbability:0.5000
最佳得分变换函数是阶跃函数,因为类是分开的。田野下界和UPPERBOUND的ScoreParameters指示对应于类分离超平面(裕度)内的观察得分的区间的下限和上限终点。没有训练观察下降幅度之内。如果一个新的得分是在区间,则软件将指定相应观测的正类的后验概率,即,在该值PositiveClassProbability现场ScoreParameters。
在观测预报空间中定义一个网格值。预测网格中每个实例的后验概率。
XMAX = MAX(X);XMIN =分钟(X);d = 0.01;[x1Grid,x2Grid] = meshgrid(XMIN(1):d:XMAX(1),XMIN(2):d:XMAX(2));[〜,PosteriorRegion] =预测(SVMModel,[x1Grid(:),x2Grid(:)]);
绘制正类后验概率区域和训练数据。
图;contourf (x1Grid x2Grid,...重塑(PosteriorRegion(:,2),尺寸(x1Grid,1),大小(x1Grid,2)));H =彩条;h.Label.String =“P({\{杂色的}})';h.YLabel.FontSize = 16;CAXIS([0 1]);色彩表喷射;保持上gscatter(X(:,1),X(:,2)中,Y,'MC','。X'10],[15日);sv = X (SVMModel.I万博1manbetxsSupportVector:);情节(sv (: 1), sv (:, 2),“哟”,'MarkerSize'15,'行宽'2);轴紧保持从

在两班的学习,如果类是分开的,然后有三个区域:一个地方的意见有积极的类后验概率0,一个它在哪里1,另外,其中它是正类先验概率。
分析用线性支持向量机图片万博1manbetx
此示例示出了如何确定的形状占据由训练包括线性SVM二进制学习者纠错输出编码(ECOC)模型的图像的哪个象限。这个例子也说明ECOC车型的磁盘空间的消耗是商店支持向量,它们的标签,以及估计万博1manbetx 系数。
创建数据集
随机放置半径五个圈50由-50图像。制作5000张图片。为每个图像表明圈占据象限的标签。象限1是在右上象限图2是在左上,象限3是在左下和象限4是在右下角。所述预测是每个像素的强度。
d = 50;%高度和以像素为单位的图像的宽度N = 5E4;%样本大小X =零(N,d ^ 2);%预测矩阵预分配Y =零(N,1);%预分配的标签θ= 0:(1 / d):(2 *π);r = 5;%圆半径RNG(1);%用于重现为J = 1:n的figmat =零(d);%是空的图像C = datasample((R + 1):( d - 的R - 1),2);%随机圆心X = R * cos(THETA)+ C(1);%定界Y = R * SIN(THETA)+ C(2);IDX = sub2ind([d d],圆(y)时,圆的(X));%转换为线性索引figmat(IDX)= 1;%绘制圆形X(J,:) = figmat(:);%存储数据Y(j)的=(C(2)> =地板(d / 2))+ 2 *(C(2)<地板(d / 2))+...(c(1) < floor(d/2)) +...2 *((C(1)> =地板(d / 2))及(三(2)<地板(d / 2)));%确定象限结束
情节一个观察。
图imagesc(figmat) h = gca;h.YDir ='正常';标题(sprintf的('象限%d',Y(结束)))
训练ECOC型号
用25%的保留样本,并指定训练和坚持样本指数。
p = 0.25;本量利= cvpartition (Y,'坚持', p);%交叉验证数据分区isIdx =训练(CVP);%训练样本指数oosIdx =测试(CVP);%的测试样本指针
创建一个SVM模板指定存储二进制学习者的支持向量。万博1manbetx通过它和训练数据fitcecoc训练模型。确定训练样本的分类错误。
T = templateSVM('Save万博1manbetxSupportVectors',真正的);MdlSV = fitcecoc(X(isIdx,:),Y(isIdx),“学习者”,T);isLoss = resubLoss(MdlSV)
isLoss = 0
MdlSV是一个训练有素的ClassificationECOC多类模式。它存储的训练数据和每个二进制学习者的支持向量。万博1manbetx对于大的数据集,例如在图像分析,该模型可以消耗大量的存储器。
确定的磁盘空间量的ECOC模型消耗。
infoMdlSV =卫生组织('MdlSV');mbMdlSV = infoMdlSV.bytes / 1.049e6
mbMdlSV = 763.6151
该模型消耗763.6 MB。
提高效率型
您可以评估出来的样本外的表现。您也可以评估模型是否已经过拟合与压实模型不包含支持向量,其相关参数和训练数据。万博1manbetx
丢弃训练好的ECOC模型万博1manbetx中的支持向量和相关参数。然后,使用。从得到的模型中丢弃训练数据紧凑。
MDL = discard万博1manbetxSupportVectors(MdlSV);CMDL =紧凑(MDL);信息=卫生组织(“铜牌”,'CMDL');[bytesCMdl, bytesMdl] = info.bytes;memreduce = 1 - [bytesMdl bytesCMdl]/ infomdlsb .bytes
memReduction =1×20.0626 0.9996
在这种情况下,丢弃所述支持向量减少约6%的内存消耗。万博1manbetx压实和废弃支持向量由约99.96%减少的大小。万博1manbetx
管理支持向量的另一种方法是通过指定较大的框约束,如使用更少万博1manbetx的支持向量是更理想的,并消耗更少的存储器100虽然SVM模型训练期间减少它们的数量,增加了箱子约束趋于的值增加训练时间。
删除MdlSV和Mdl从工作区。
明确MdlMdlSV
评估坚持样本的表现
计算保留样本的分类错误。绘制坚持样本预测的样本。
oosLoss =损耗(CMDL,X(oosIdx,:),Y(oosIdx))
oosLoss = 0
yHat =预测(CMDL,X(oosIdx,:));nVec = 1:尺寸(X,1);oosIdx = nVec(oosIdx);图;为J = 1:9副区(3,3,j)的于imagesc(重塑(X(oosIdx(j)中,:),[d d]))H = GCA;h.YDir ='正常';标题(sprintf的('象限:%d',yHat(J)))结束文本(-1.33 * d,4.5 * d + 1,“预测”,'字体大小',17)

该模型没有任何错误分类坚持样本的观察。
也可以看看
相关话题
参考
[1] Hastie的,T.,R. Tibshirani,和J.弗里德曼。统计学习的要素, 第二版。纽约:施普林格,2008年。
[2] Christianini,N.,和J. Shawe-泰勒。简介支持向量机和其他基于内核的学习方法万博1manbetx。英国剑桥:剑桥大学出版社,2000。
[3]范,R.-E.,P.-H.陈忠和C.-J.林。“工作使用训练支持向量机的二阶信息设置选择。”万博1manbetx机器学习研究杂志, 2005年第6卷,第189 - 1918页。
[4] Kecman V.,T. -M。黄和M.沃格特。“迭代单数据算法从海量数据集培训核机器:理论和性能。”在万博1manbetx支持向量机:理论与应用。由王脂微球,255-274编辑。柏林:施普林格出版社,2005年。
您也可以从以下列表中选择一个网站:
