bootci
引导置信区间
句法
描述
例子
引导置信区间
计算统计过程控制能力指标的置信区间。
从平均值1和标准偏差1生成30个随机数。
RNG('默认')重复性的%y = normrnd(1, 1, 30岁,1);
指定工艺的规格下限和上限。定义能力索引。
LSL = 3;USL = 3;= @ (x)能力(USL-LSL)。/(6 *性病(x));
使用2000 Bootstrap样本计算能力索引的95%置信区间。默认,bootci使用偏置校正和加速百分位方法来构建置信区间。
ci = bootci(2000,有能力,y)
ci =2×10.5937 0.9900
计算能力指数的学生化置信区间。
sci = bootci(2000年{能力,y},“类型”那'学生')
SCI =2×10.5193 0.9930.
非线性回归模型系数的引导置信区间
计算非线性回归模型系数的引导置信间隔。在该示例中使用的技术涉及引导预测器和响应值,并假设预测器变量是随机的。对于假设预测器变量的技术是固定并引导残差的技术,请参阅线性回归模型系数的引导置信区间。
笔记:这个示例使用nlinfit(当您只需要非线性回归模型的系数估计或残差时,它很有用,并且您需要重复拟合模型多次,如在自动启动的情况下。如果您需要进一步调查拟合的回归模型,请通过使用创建非线性回归模型对象fitnlm.。您可以通过使用使用的系数为所得模型的系数创造置信区间COEFCI.对象函数,虽然此函数不使用自举。
从非线性回归模型中生成数据 ,在那里 那 , 和 是系数;预测器变量X呈指数分布,均值为2;误差项 通常以平均值0分布和标准偏差0.1。
modelfun = @(b,x)(b(1)+ b(2)* exp(-b(3)* x));RNG('默认')重复性的%b = [1; 3; 2);x = exprnd (2100 1);Y = modelfun(b,x) + normrnd(0, 0.1100,1);
为使用中初始值的非线性回归模型创建函数句柄Beta0.。
beta0 = [2; 2; 2];Beta = @(预测器,响应)nlinfit(预测器,响应,modelfun,beta0)
β=function_handle具有值:@(预测器,响应)nlinfit(预测器,响应,modelfun,beta0)
计算非线性回归模型的系数的95%Bootstrap置信区间。从生成的数据创建引导样本X和y。
ci = bootci(1000年,β,x, y)
ci =2×30.9821 2.9552 2.0180 1.0410 3.1623 2.2695
前两种置信区间包括真正的系数值 和 , 分别。但是,第三次置信区间不包括真正的系数值 。
现在计算模型系数的99%Bootstrap置信区间。
newci = bootci(1000年,{β,x, y},'Α', 0.01)
newci =2×30.9730 2.9112 1.9562 1.0469 3.1876 2.3133
所有三个置信区间包括真正的系数值。
线性回归模型系数的引导置信区间
计算线性回归模型系数的引导置信间隔。在该示例中使用的技术涉及引导残差并假设预测器变量是固定的。对于假设预测器变量的技术是随机的,并引导预测器和响应值,请参阅非线性回归模型系数的引导置信区间。
笔记:这个示例使用回归,当您只需要一个回归模型的系数估计或残差,并且您需要重复拟合一个模型多次时,这是有用的,就像在bootstrapping的情况。如果需要进一步研究拟合的回归模型,可以使用Fitlm.。您可以通过使用使用的系数为所得模型的系数创造置信区间COEFCI.对象函数,虽然此函数不使用自举。
加载样本数据。
加载hal
执行线性回归并计算残差。
x =[(大小(热)),成分);y =热量;b =回归(y、x);yfit = x * b;Resid = y - yfit;
计算线性回归模型系数的95% bootstrap置信区间。从残余物中创建bootstrap样本。通过指定,使用带有自举偏差和标准误差的正态逼近区间“类型”、“正常”。在这种情况下,不能使用默认置信区间类型。
ci = bootci(1000,{@(bootr)回归(yfit + bootr,x),star},......“类型”那'普通的')
ci =2×5-47.7130 0.3916 -0.6298 -1.0697 -1.2604 172.4899 2.7202 1.6495 1.2778 0.9704
绘制估计的系数B.,省略截距术语,并显示显示系数置信区间的误差条。
斜坡= B(2:结束)';Dublubrlengths = Slopes-Ci(1,2:结束);upperbarlengths = ci(2,2:end)-slopes;errorbar(1:4,斜坡,updarbarlengs,upperbarlengths)xlim([0 5])标题(系数的置信区间的)
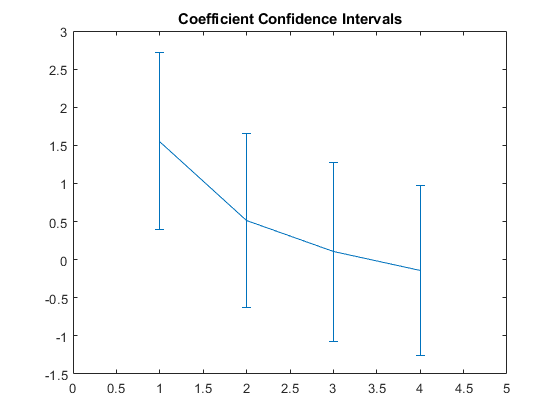
只有第一个非截距系数与0有显著差异。
多个统计数据的置信区间
计算100个自助样本的平均值和标准偏差。找出每个统计量的95%置信区间。
从指数分布产生100个随机数,平均值5。
RNG('默认')重复性的%Y = EXPRND(5,100,1);
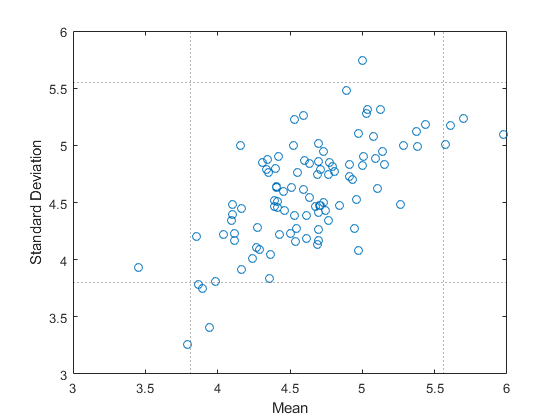
从向量中绘制100引导样本y。对于每个引导样本,计算平均值和标准偏差。找到均值和标准偏差的95%引导置信区间。
[ci,bootstat] = bootci(100,@(x)[均值(x)std(x)],y);
ci (: 1)包含平均置信区间的下界和上界,以及C(:,2)包含标准偏差置信区间的下限和上限。每一排bootstat.包含引导样本的平均值和标准偏差。
绘制每个自助样本的均值和标准差作为一个点。绘制均值置信区间的下界和上界为垂直线虚线,绘制标准差置信区间的下界和上界为水平线虚线。
plot(bootstat(:,1),bootstat(:,2),'o')Xline(CI(1,1),':')Xline(CI(2,1),':')Yline(CI(1,2),':')Yline(CI(2,2),':')xlabel('吝啬的')ylabel('标准偏差')
输入参数
输出参数
参考
A. C.戴维森,D. V.欣克利。引导方法及其应用程序。剑桥大学出版社,1997年。
[2] efron,布拉德利。折刀,引导和其他重采样计划。费城:1982年工业和应用数学协会。
[3] Diciccio,Thomas J.和Bradley Efron。“引导置信区间。”统计科学11日,没有。3(1996): 189 - 228。
[4] efron,布拉德利和罗伯特J. Tibshirani。Bootstrap简介。纽约:1993年Chapman&Hall。
扩展功能
您还可以从以下列表中选择一个网站:
