在分类学习者应用程序中使用测试集检查分类器性能
此示例显示如何在分类学习者中培训多个模型,并根据其验证精度确定最佳性能模型。检查在完整数据集培训的最佳性能模型的测试准确性,包括培训和验证数据。
在matlab.®命令窗口,加载
电离层数据集,并创建包含该数据的表。将表分为训练集和测试集。负载电离层tbl = array2table(x);tbl.y = y;RNG('默认')数据拆分的再现性的%分区= cvpartition (Y,“坚持”, 0.15);idxTrain =培训(分区);%训练集指标tblTrain =(资源(idxTrain:);tblTest =(资源(~ idxTrain:);
开放分类学习者。单击应用程序选项卡,然后单击右侧的箭头应用程序要打开Apps Gallery的部分。在机器学习和深度学习组中,单击分类学习者.
在分类学习者标签,在文件部分中,点击新会议并选择从工作空间.
在“工作区”对话框的“新会话”中,选择
tbltrain表的数据集变量列表。如对话框所示,该应用程序选择响应和预测器变量。默认响应变量是
Y.为了防止过度装备,默认验证选项是5倍交叉验证。对于此示例,请勿更改默认设置。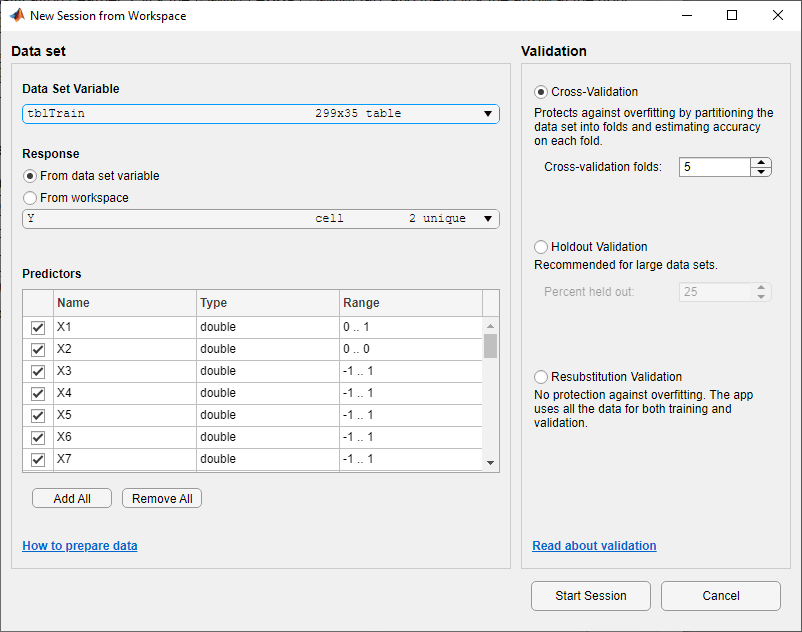
要接受默认选项并继续,请单击开始课程.
训练所有预设模型。在分类学习者标签,在模型类型段,单击箭头以打开图库。在开始组中,单击全部.在培训部分中,点击火车.该应用程序训练每一种预设的模型类型,并显示模型在模型窗格。
提示
如果您有并行计算工具箱™,则可以培训所有型号(全部)同时选择使用并行按钮培训节之前点击火车.你点击后火车,打开“打开并行池”对话框将打开并保持打开,而该应用程序打开并行工人池。在此期间,您无法与软件进行互动。池打开后,应用程序同时列出模型。
根据验证精度对训练的模型进行排序。在模型窗格中,打开排序方式列表并选择
准确性(验证).在模型窗格中,单击验证精度最高的三个模型旁边的星形图标。该应用程序通过在方框中列出验证的准确性来突出显示。在这个例子中,训练有素的介质高斯支持向量机模型验证精度最高。

该应用程序显示第一个模型的验证混淆矩阵(型号1.1)。蓝色值表示正确的分类,红色值表示不正确的分类。这模型左边的窗格显示了每个模型的验证精度。
请注意
验证在结果中引入了一些随机性。您的模型验证结果可能与本例中显示的结果不同。
检查性能最好的模型的测试集性能。首先将测试数据导入应用程序。
在分类学习者标签,在测试部分中,点击测试数据并选择从工作空间.
在“导入测试数据”对话框中,选择
tblTest表的测试数据集变量列表。如对话框所示,应用程序识别响应和预测变量。
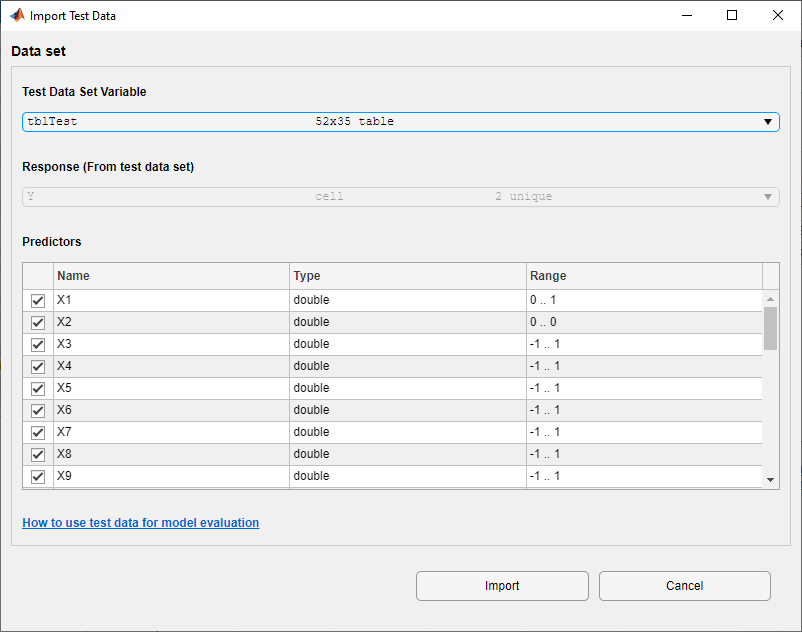
点击进口.
计算最佳预设模型的准确性
tblTest数据。为方便起见,一次计算所有模型的测试集精度。在分类学习者标签,在测试部分中,点击测试所有并选择测试所有.该应用程序计算在完整数据集上培训的模型的测试集性能,包括培训和验证数据。根据测试集的准确性对模型进行排序。在模型窗格中,打开排序方式列表并选择
准确性(测试).尽管显示测试精度,该应用程序仍然概述了最高验证精度的模型的度量。目视检查模型的测试集性能。对于每个带星号的模型,在模型窗格。在分类学习者标签,在情节段,单击箭头以打开图库,然后单击混乱矩阵(测试)在里面测试结果团体。
重新排列图的布局以更好地比较它们。首先,关闭验证混淆矩阵型号1.1.然后,单击位于模型绘图选项卡最右侧的Document Actions箭头。选择
瓷砖都选项并指定一个1乘3的布局。单击隐藏情节选项按钮 在图的右上角给图留出更多的空间。
在图的右上角给图留出更多的空间。在这个例子中,训练有素的支持向量机内核模型仍然是测试集数据上的最佳性能模型之一。

要返回原始布局,您可以单击布局按钮情节部分并选择单一模式(默认).
比较受训人员的验证和测试准确性支持向量机内核模型。在当前模型的总结窗格中,比较准确性(验证)价值培训结果到准确性(测试)价值测试结果.在本例中,这两个值很接近,这表明验证精度是对该模型测试精度的一个很好的估计。




相关话题
您还可以从以下列表中选择一个网站:
