预测
使用广义添加剂模型(GAM)进行分类观察
描述
例子
GAM的标记检验样本观察
使用训练样品训练广义添加剂模型,然后标记测试样品。
加载渔民数据集。创造X.作为包含versicolor和Virginica Irises的萼片和花瓣测量的数字矩阵。创造y作为包含相应的IRIS物种的字符向量的单元阵列。
加载渔民第1 = strcmp(物种,'versicolor') | strcmp(物种,“virginica”);x = meas(inds,:);Y =物种(Inds,:);
随机分区观察到培训集和使用类信息的分层进行测试集y.指定30%HoldOut样本进行测试。
rng (“默认”)%的再现性cv = cvpartition(y,'持有',0.30);
提取培训和测试指数。
训练=训练(简介);testinds =测试(CV);
指定培训和测试数据集。
xtrain = x(训练,:);ytrain = y(训练器);xtest = x(testinds,:);ytest = y(testinds);
用预测器训练一个广义的可加性模型XTrain.和班级标签ytrain..推荐的做法是指定类名。
mdl = fitcgam(Xtrain,Ytrain,“类名”,{'versicolor'那“virginica”})
MDL = ClassificationGam RecordingEname:'y'类分类预测器:[] ClassNames:{Versicolor''virginica'} ScoreTransform:'Logit'拦截:-1.1090 numObservations:70属性,方法
MDL.是一个ClassificationGAM模型对象。
预测测试样品标签。
标签=预测(Mdl XTest);
创建一个包含真实标签和预测标签的表。显示一个随机的10个观察的表。
t =表(欧美、标签、'variablenames',{'真品'那“预测标签”});IDX = RANDSAMPLE(SUM(TESTINDS),10);t(idx,:)
ans =10×2表真正的标签预测标签 ______________ _______________ {' virginica’}{‘virginica}{‘virginica}{‘virginica}{“癣”}{‘virginica}{‘virginica}{‘virginica}{‘virginica}{‘virginica}{“癣”}{“癣”}{“癣”}{“癣”}{“癣”}{“癣”}{“癣”}{“癣”}{' virginica '}{' virginica '}
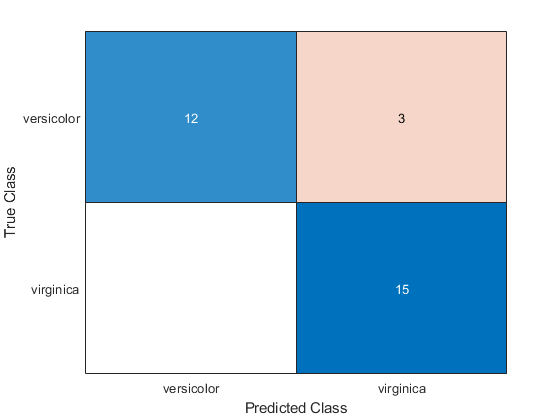
从真正的标签创建混淆图表ytest.和预测的标签标签.
CM = ConfusionChart(Yest,Label);
比较后概率的登录
使用包含预测器的线性和交互条款的分类GAM来估计后验概率的后概率。使用内存有效的模型对象对新的观测进行分类。指定在分类新观察时是否包括交互术语。
加载电离层数据集。此数据集具有34个预测器和351个雷达返回的二进制响应,无论是坏的吗('B')或好(‘g’)。
加载电离层
将数据集划分为两个集:一个包含训练数据,另一个包含新的、未观察到的测试数据。为新的测试数据集保留10个观测值。
rng (“默认”)%的再现性n =尺寸(x,1);newinds = randsample(n,10);inds =〜ismember(1:n,newinds);xnew = x(newinds,:);ynew = y(newinds);
使用预测器训练游戏X.和班级标签y.推荐的做法是指定类名。指定包含10个最重要的交互条款。
mdl = fitcgam(x(inds,:),y(inds),“类名”,{'B'那‘g’},'互动'10);
MDL.是一个ClassificationGAM模型对象。
通过减少训练模型的大小来节省内存。
cmdl = compact(mdl);Whos(“Mdl”那'cmdl')
名称大小字节类属性cmdl 1x1 1081082 classreg.learning.classif.compactclassificationgam mdl 1x1 1282640 Classificationgam
CMDL.是一个CompactClassificationgam.模型对象。
使用线性和交互术语预测标签,然后仅使用线性术语。要排除交互术语,请指定'internalidantaction',false.通过指定,估计后验概率的对数ScoreTransform财产'没有'.
cmdl.scoretransform ='没有';(标签、分数)=预测(CMdl XNew);[labels_nointeraction, scores_nointeraction] =预测(CMdl XNew,'internalideraction'、假);t =表(YNew、标签分数,labels_nointeraction scores_nointeraction,......'variablenames',{“真正的标签”那'预测标签'那'分数'......'没有互动的预测标签'那的分数没有相互作用的})
t =10×5表真正的标签预测标签在没有互动的情况下进行预测的标签,没有互动分数___________ _________________________________________________________________________30.23 {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} {'g'} -40.23 40.23 {'g'} {'g'} -40.23 40.23 {'g'} -4121541.215 {'g'} -38.737 38.737 {'g'} {'g'} {'g'} {'g'} -44.413 44.413 {'g'} -42.186 42.186 {'b'} {'b'} 3.0658 -3.0658 {'b'} 1.4338 -1.4338 {'g'} {'g'} -84.637 84.637 {'g'} -81.269 81.269 {'g'} {'g'} -27.44 27.44 {'g'} -24.831 24.831 {'g'} {'G'} -62.989 62.989 {'g'} -60.4 60.4 {'g'} {'g'} {'g'} -77.109 77.109 {'g'} -75.937 75.937 {'g'} {'g'} {'g'} -48.519 48.519 {''g'} -47.067 47.067 {'g'} {'g'} -56.256 56.256 {'g'} -53.373 53.373
测试数据的预测标签Xnew.不因包含交互项而有所不同,但估计得分值是不同的。
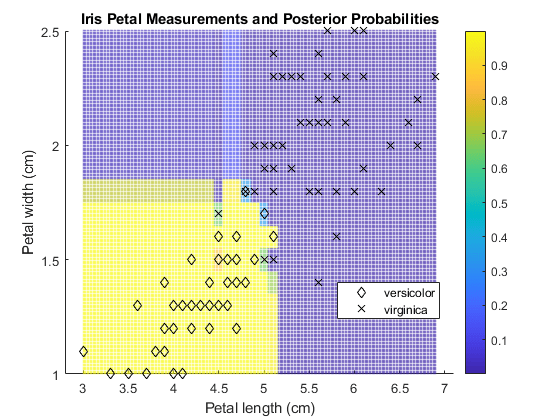
绘制后验概率区域
训练广义添加剂模型,然后使用第一类的概率值绘制后验概率区域。
加载渔民数据集。创造X.作为一个数字矩阵,其包含versicolor和Virginica Irises的两个花瓣测量。创造y作为包含相应的IRIS物种的字符向量的单元阵列。
加载渔民第1 = strcmp(物种,'versicolor') | strcmp(物种,“virginica”);X = MEAS(INDS,3:4);Y =物种(Inds,:);
用预测器训练一个广义的可加性模型X.和班级标签y.推荐的做法是指定类名。
mdl = fitcgam(x,y,“类名”,{'versicolor'那“virginica”});
MDL.是一个ClassificationGAM模型对象。
在观察到的预测器空间中定义一个值的网格。
xMax = max (X);xMin = min (X);x1 = linspace (xMin (1) xMax (1), 250);xMax x2 = linspace (xMin (2), (2), 250);[x1Grid, x2Grid] = meshgrid (x1, x2);
预测网格中每个实例的后验概率。
[〜,posteriorregion] =预测(mdl,[x1grid(:),x2grid(:)]);
使用第一类的概率值绘制后验概率区域'versicolor'.
h =分散(x11grid(:),x2grid(:),1,psteriorregion(:,1));H.Markeredgealpha = 0.3;
绘制培训数据。
hold上gh = gscatter (X (: 1), X (:, 2), Y,“k”那'dx');标题(“虹膜花瓣的测量和后验概率”)xlabel('花瓣长度(cm)')ylabel(“花瓣宽度(cm)”)传奇(GH,'位置'那“最好”)Colorbar Hold.关闭
输入参数
输出参数
更多关于
您还可以从以下列表中选择一个网站:
