kfoldMargin
为观察分类利润率不用于训练
语法
M = kfoldMargin(OBJ)
输入参数
|
类型的分区分类模型 |
输出参数
|
的分类。 |
例子
更多关于
分数
对于判别分析,为分数分类的是分类的后验概率。对于判别分析后验概率的定义,请参阅后验概率。
对于集合,是一种分类分数表示分类到类的置信度。分数越高,信心越强。
不同的集成算法对其分数有不同的定义。此外,分数的范围取决于合奏的类型。例如:
AdaBoostM1得分范围为-∞到∞。袋分数范围从0来1。
对于树木,分数一个叶节点的分类的后验概率是该节点的分类的后验概率。该分类在一个节点上的后验概率是导致该分类节点的训练序列的数量除以导致该节点的训练序列的数量。
例如,考虑分类的预测X作为真正当X<0.15要么X>0.95和X是假的。
生成100个随机点,它们归类:
rng (0,“旋风”)%的再现性X =兰德(100 1);Y = (abs(X - .55) > .4);树= fitctree (X, Y);视图(树,“模式”,“图”)
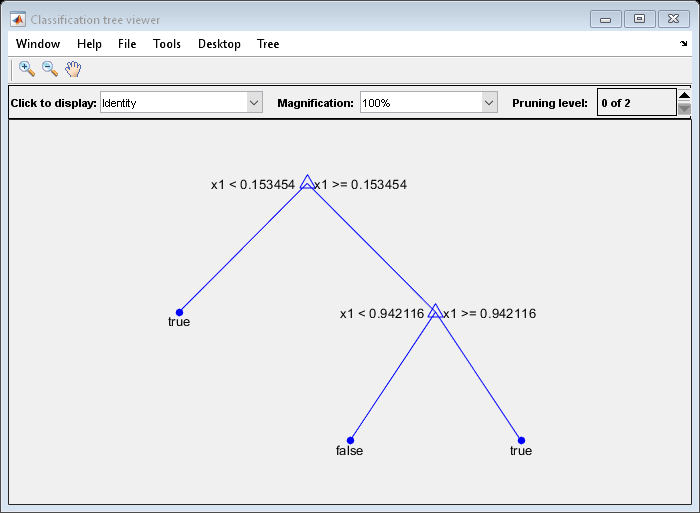
修剪树:
tree1 =修剪(树,“水平”1);视图(树1,“模式”,“图”)
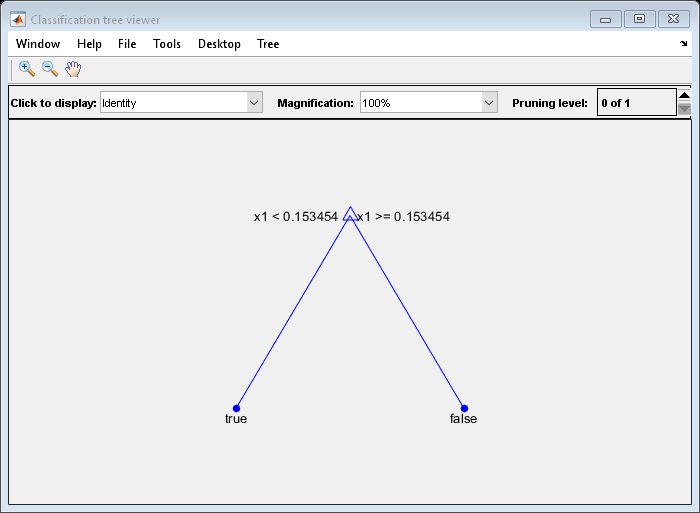
经过修剪的树能够正确地分类小于0.15 a的观察值真正。它还正确分类,从0.15到0.94的意见假。然而,它错误地将大于.94 a的观测结果分类假。因此,大于.15的观察值大约为.05/.85=。06年的真正,约。8/。85=。94年假。
计算预测得分前10行的X:
[~,分数]=预测(tree1 X (1:10));(分数X (1:10)):
ans =10×30.9059 0.0941 0.8147 0.9059 0.0941 0.9058 0 1.0000 0.1270 0.9059 0.0941 0.6324 0 1.0000 0.0975 0.9059 0.0941 0.2785 0.9059 0.0941 0.5469 0.9059 0.0941 0.9575 0.9059 0.0941 0.9649
的确,每一个价值X(最右列),其小于0.15具有相关联的得分(左边和中间列)0和1,而其它值X有相关的分数0.91和0.09。(得分的区别0.09而不是预期的06)是由于统计波动:有8观察X范围内(1).95而不是预期的5观察。
您还可以选择从下面的列表中的网站:
