kfoldPredict
预测观测响应不用于训练
句法
标记= kfoldPredict(OBJ)
[标号,得分= kfoldPredict(OBJ)
(标签、分数、成本)= kfoldPredict (obj)
描述
标签= kfoldPredict(OBJ)OBJ,交叉验证的分类。对于每一个褶皱,kfoldPredict预测类标签使用的培训上了倍的观测模型中倍观察。
输出参数
|
如在训练中使用的相同类型的类别标签的矢量的响应数据 |
|
尺寸的数字矩阵 |
|
数值矩阵的误分类代价大小 |
例子
从一个集合中估计交叉验证的预测
查找基于Fisher的虹膜数据模型中的交叉验证的预测。
加载费舍尔的虹膜数据集。
加载fisheriris
使用AdaBoostM2训练分类树的集合。指定树桩为弱学习者。
rng (1);%的再现性t = templateTree (“MaxNumSplits”1);MDL = fitcensemble(MEAS,物种,'方法','AdaBoostM2',“学习者”,T);
交叉验证使用所述训练集合10倍交叉验证。
CVMdl = crossval (Mdl);
估计交叉验证预测的标签和分数。
[elabel, escore] = kfoldPredict (CVMdl);
显示每个类的最高分和最低分。
马克斯(escore)
ANS =1×39.3862 8.9871 10.1866
分钟(escore)
ANS =1×30.0018 3.8359 0.9573
创建混淆矩阵使用交叉验证预测
使用判别分析模型的10倍交叉验证的预测创建一个混淆矩阵。
加载fisheriris数据集。X包含花三围为150个不同的花,ÿ列出的品种,或类,每个花。创建一个变量订单它指定了类的顺序。
加载fisheririsX = MEAS;Y =物种;为了=唯一的(y)的
订单=3 x1细胞{ 'setosa'} { '云芝'} { '锦葵'}
通过使用创建一个10倍交叉验证的判别分析模型fitcdiscr功能。默认,fitcdiscr确保训练和测试集有大致花卉品种相同比例。指定花类的顺序。
cvmdl = fitcdiscr (X, y,'KFold'10,“类名”、订单);
预测的测试集花卉品种。
predictedSpecies = kfoldPredict(cvmdl);
创建真正的类值进行比较,以预测的类值的混淆矩阵。
predictedSpecies confusionchart (y)

更多关于
得分
对于判别分析,为得分分类的后验概率是分类的后验概率。判别分析中后验概率的定义见后验概率。
对于乐团,分类得分代表一个分类的信心到一个类。分数越高,信心越高。
不同的合奏算法对自己的分数有不同的定义。此外,分数的范围取决于合奏类型。例如:
AdaBoostM1分数范围从负无穷到正无穷。袋得分范围为0至1。
对于绿树成荫,得分叶节点的分类的是在该节点分类的后验概率。在节点分类的后验概率是训练序列的数目铅与分类该节点,通过训练序列的铅的数量,以该节点划分。
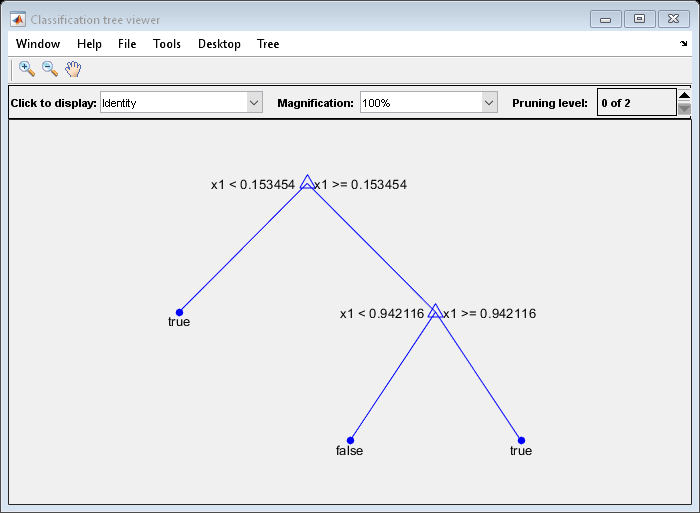
例如,考虑对预测器进行分类X如真正的什么时候X<0.15或X>0.95,X是假的,否则。
生成100个随机点并进行分类:
RNG(0,“扭腰”)%,持续重现X =兰德(100 1);Y = (abs(X - .55) > .4);树= fitctree (X, Y);视图(树,'模式',“图”)
修剪树:
树1 =剪枝(树,'水平'1);视图(tree1,'模式',“图”)
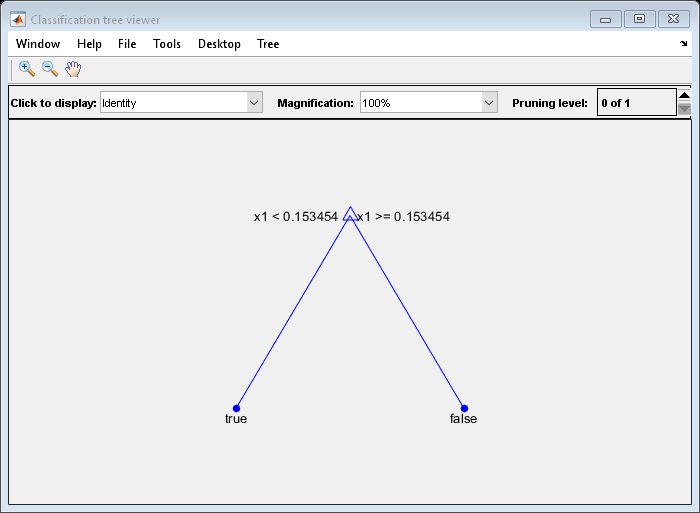
该修剪树正确分类是小于0.15的意见真正的。它还能正确地将0.15到0.94之间的观测数据进行分类假。但是,它错误地归类是大于0.94的意见假。因此,大于.15的观察值大约为.05/.85=。06年的真正的和约0.8 / 0.85 = 0.94对假。
的前10行计算预测分数X:
[〜,得分=预测(树1,X(1:10));[得分X(1:10,:)]
ANS =10×30.9059 0.0941 0.8147 0.9059 0.0941 0.9058 0 1.0000 0.1270 0.9059 0.0941 0.6324 0 1.0000 0.0975 0.9059 0.0941 0.2785 0.9059 0.0941 0.5469 0.9059 0.0941 0.9575 0.9059 0.0941 0.9649
事实上,每一个值X(最右列)小于0.15的关联分数(左列和中间列)为0和1,而其他值为X有相关的分数0.91和0.09。所不同的(得分0.09而不是预期的0.06)是由于统计波动:有8在观察X在范围内(.95,1)而不是预期的五观察结果。
您也可以从以下列表中选择网站:
