ClassificationPartitionedECOC
交叉验证的多类ECOC模型支持向量机(SVM)等分类万博1manbetx
描述
ClassificationPartitionedECOC是一组经过交叉验证的折叠训练的错误校正输出码(ECOC)模型。使用一个或多个“kfold”函数估计交叉验证分类的质量:kfoldPredict,kfoldLoss,kfoldMargin,kfoldEdge,kfoldfun。
每个受训的“kfold”方法使用模型训练倍(以倍),观察到预测进行验证倍(超出倍)观察的响应。例如,假设您使用5重交叉验证。在这种情况下,软件随机分配各观察分成五组相同大小(大约)的。该培训褶皱包含四个组(大约4/5的数据),以及验证倍包含另一组(大约是数据的1/5)。在这种情况下,交叉验证的过程如下:
该软件训练的第一款车型(存储在
CVMdl.Trained {1}),使用后四组的观察结果,并保留第一组的观察结果以供验证。软件训练第二种模型(存储在
CVMdl.Trained {2}),利用第一组及后三组的观察资料。软件将观察结果保存在第二组中以备验证。软件在第三、第四和第五种模型中以类似的方式进行。
如果验证通过使用kfoldPredict,该软件计算在组观测预测我通过使用我TH模型。总之,软件估计通过使用而没有观察训练的模型中的每个观察响应。
创建
您可以创建一个ClassificationPartitionedECOC模型有两种方式:
属性
对象的功能
kfoldEdge |
交叉验证的ECOC模型的分类边缘 |
kfoldLoss |
对于交叉验证ECOC模型分类损失 |
kfoldMargin |
交叉验证的ECOC模型的分类裕度 |
kfoldPredict |
对交叉验证的ECOC模型中的观测结果进行分类 |
kfoldfun |
使用交叉验证的ECOC模型的交叉验证功能 |
例子
旨在ECOC分类器
用支持向量机二值学习器对ECOC分类器进行交叉验证,并估计广义分类误差。
加载Fisher虹膜数据集。指定预测数据X和响应数据Y。
负载fisheririsX =量;Y =物种;rng (1);%用于重现
创建一个SVM模板,并对预测器进行标准化。
T = templateSVM(“标准化”,真正的)
T =用于分类SVM拟合模板。阿尔法:为0x1双] BoxConstraint:[] CacheSize的:[] CachingMethod: '' ClipAlphas:[] DeltaGradientTolerance:[]小量:[] GapTolerance:[] KKTTolerance:[] IterationLimit:[] KernelFunction: '' KernelScale:[]KernelOffset:[] KernelPolynomialOrder:[] NumPrint:[]女:[] OutlierFraction:[] RemoveDuplicates:[] ShrinkagePeriod:[]求解: '' StandardizeData:1个SaveSupportVectors:万博1manbetx[] VerbosityLevel:[]版本:2所述的方法:“SVM'类型:‘分类’
t为SVM模板。大多数模板对象属性都是空的。在训练ECOC分类器时,软件将适用的属性设置为默认值。
训练ECOC分类,并指定类的顺序。
Mdl = fitcecoc (X, Y,“学习者”,T,...“类名”,{'setosa',“多色的”,“弗吉尼亚”});
Mdl是ClassificationECOC分类器。您可以使用点符号访问它的属性。
旨在Mdl使用10倍交叉验证。
CVMdl = crossval (Mdl);
CVMdl是ClassificationPartitionedECOC交叉验证的ECOC分类器。
估计广义分类错误。
genError = kfoldLoss(CVMdl)
genError = 0.0400
广义分类误差为4%,说明ECOC分类器具有较好的泛化能力。
加快训练速度ECOC量词使用分档和并行计算
使用火车一抗所有ECOC分类GentleBoost决策树与代理分割的集成。为了加速训练,bin数值预测器和使用并行计算。只有在以下情况下才有效fitcecoc使用树形学习者。训练后,使用10倍交叉验证估计分类误差。注意,并行计算需要并行计算工具箱™。
加载示例数据
装入并检查心律失常数据集。
负载心律失常[N,P] =尺寸(X)
n = 452
P = 279
isLabels =独特(Y);nLabels =元素个数(isLabels)
nLabels = 13
汇总(分类(Y))
值计数百分比1 245 54.20%2 44 9.73%3 15 3.32%4 15 3.32%5 13 2.88%6 25 5.53%7 3 0.66%8 2 0.44%9 9 1.99%10 50 11.06%14 4 0.88%15 5 1.11%16 22 4.87%
数据集包含279预测因子,和样本容量452相对较小。在16个不同标签中,只有13个在回应中出现(Y)。每个标签描述不同程度的心律失常,54.20%的观察结果在课堂上进行1。
训练单一对所有ECOC分类器
创建一个合奏的模板。您必须指定至少三个参数:一个方法,许多学习者,和学习者的类型。在这个例子中,指定“GentleBoost”该方法,One hundred.以及一个决策树模板,该决策树模板使用代理分割,因为存在缺失的观察结果。
tTree = templateTree(“代孕”,“上”);tEnsemble = templateEnsemble(“GentleBoost”,100,tTree);
tEnsemble是模板对象。它的大多数属性是空的,但是软件在训练时用默认值填充它们。
使用决策树的集合作为二进制学习器来训练一个对所有的ECOC分类器。为了加快训练速度,可以使用并行计算。
分档(
'NumBins',50) - 当你有一个大的训练数据集,可以加快使用培训(精度可能减少)'NumBins'名称 - 值对的参数。该参数才有效fitcecoc使用树形学习者。如果你指定'NumBins'值,然后软件将每个数值预测器放入指定数量的等概率箱子中,然后在箱子索引(而不是原始数据)上生长树。你可以试着'NumBins',50第一,然后更改'NumBins'值取决于精度和训练速度。并行计算(
'选项',statset( 'UseParallel',真)) - 用一个并行计算工具箱许可证,则可以加快通过使用并行计算,它发送每个二进制学习者到池中一个工人的计算。工人的数量取决于您的系统配置。当您使用决策树二进制学习者,fitcecoc使用英特尔线程构建模块(TBB)为双核系统和上述平行化的训练。因此,指定“UseParallel”选项不是一台计算机上有帮助。使用群集此选项。
另外,指定先验概率为1/K,其中K= 13是不同的类的数量。
选项= statset(“UseParallel”,真正的);Mdl = fitcecoc (X, Y,“编码”,'onevsall',“学习者”tEnsemble,...“在此之前”,'制服','NumBins',50岁,“选项”、选择);
使用“本地”配置文件启动并行池(parpool)…连接到并行池(worker数量:6)。
Mdl是ClassificationECOC模型。
交叉验证
交叉验证使用10倍交叉验证的ECOC分类器。
CVMdl = crossval (Mdl,“选项”、选择);
警告:一个或多个折叠没有从所有组中包含了点。
CVMdl是ClassificationPartitionedECOC模型。该警告表明,当软件至少进行了一次训练时,有些类没有被表示出来。因此,这些折叠不能预测缺失类的标签。您可以使用单元索引和点表示法检查折叠的结果。例如,通过输入来访问第一个折叠的结果CVMdl.Trained {1}。
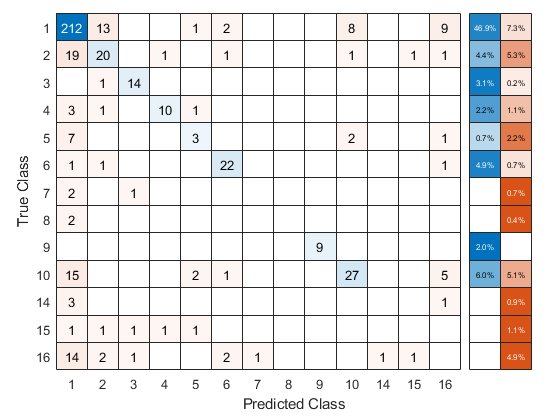
使用交叉验证的ECOC分类器来预测验证折叠标签。你可以使用confusionchart。通过更改内部位置属性移动图表并调整其大小,以确保百分比显示在行摘要中。
oofLabel = kfoldPredict(CVMdl,“选项”、选择);ConfMat = confusionchart (Y, oofLabel,'RowSummary',“total-normalized”);ConfMat。InnerPosition = [0.10 0.12 0.85 0.85];
重现离散化数据
利用BinEdges训练模型的性质和离散化函数。
X = Mdl.X;%的预测数据Xbinned =零(大小(X));边缘= Mdl.BinEdges;%查找分级预测的指标。idxNumeric =找到(〜cellfun(@的isEmpty,边缘));如果iscolumn(idxNumeric) = idxNumeric';结束为idxNumeric x = x (:,j);%将x转换为数组,如果x是一个表。如果istable(X)X = table2array(X);结束%组通过使用离散化函数X到箱中。xbinned =离散化(x,[无穷;边缘{};正]);Xbinned (:, j) = Xbinned;结束
Xbinned包含二进制位索引,取值范围为1到箱柜的数目,对于数值预测因子。Xbinned值是0分类预测。如果X包含南s,则相应Xbinned值是南年代。
介绍了R2014b
您也可以从以下列表中选择网站:
