使用硬群体群集高斯混合数据
这个例子展示了如何在混合高斯分布的模拟数据上实现硬聚类。
通过实现拟合模型的多元正态分量可以表示聚类,可以使用高斯混合模型对数据进行聚类。
模拟高斯分布式混合的数据
模拟使用两个二核高斯分布的混合的数据mvnrnd.
RNG('默认')重复性的%Mu1 = [1 2];Sigma1 = [3 .2;2 2);Mu2 = [-1 -2];Sigma2 = [20 0;0 1];X = [mvnrnd (mu1 sigma1,200);mvnrnd (mu2 sigma2,100)];n =大小(X, 1);图散射(X(: 1),(:, 2), 10日'ko')
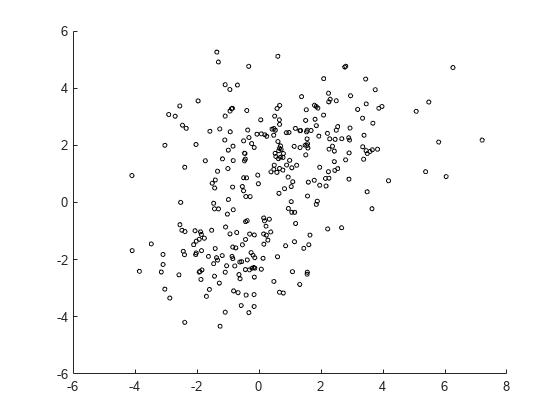
将模拟数据拟合到高斯混合模型
拟合二元高斯混合模型(GMM)。在这里,您知道了要使用的组件的正确数量。在实践中,对于真实数据,这个决策需要比较不同组件数量的模型。同时,要求显示期望最大化拟合程序的最终迭代。
选项= statset('展示','最终的');gm = fitgmdist(x,2,“选项”选项)
成分1:混合比例:0.629514 Mean: 1.0756 2.0421成分2:混合比例:0.370486 Mean: -0.8296 -1.8488
绘制双组分混合物分布的估计概率密度轮廓。两个二元正态分量重叠,但它们的峰是不同的。这表明数据可以合理地分为两个集群。
持有在gmpdf = @(x,y)arrayfun(@(x0,y0)pdf(gm,[x0,y0]),x,y);Fcontour(GMPDF,[ - 8,6])标题('散射图和装配GMM轮廓') 抓住离开

使用装有的GMM聚类数据
集群实现“硬聚类”,一种将每个数据点精确地分配给一个聚类的方法。GMM,集群将每个点分配到GMM中的两个混合组件之一。每个簇的中心是相应的混合物组分意味着。有关“软群集”的详细信息,请参阅用软聚类方法聚类高斯混合数据.
通过将装配的GMM和数据传递给群集将数据分区为群集集群.
idx =集群(通用,X);Cluster1 = (idx == 1);%| 1 |对于群集1会员资格= (idx == 2);% |2|用于集群2成员图gscatter (X (: 1), (:, 2), idx,rb的,'+ o')传说(“集群1”,《集群2》,'地点',“最佳”)
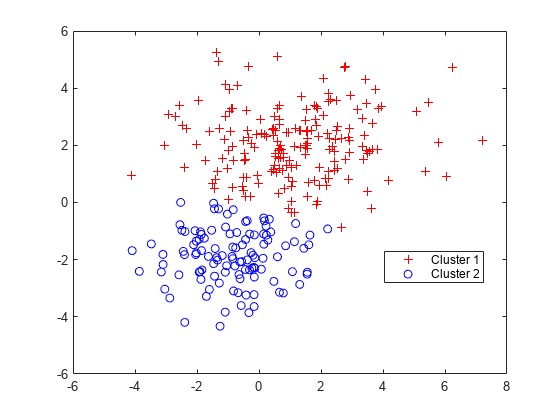
每个聚类对应于混合分布中的一个二元正态分量。集群根据集群成员关系评分将数据分配给集群。每个聚类隶属度得分是数据点来自相应分量的后验概率估计。集群将每个点赋给对应于最高后验概率的混合分量。
您可以通过将装配的GMM和数据传递给以下任一方法来估算群集成员身份后面概率:
集群,并请求返回第三个输出参数
估计聚类成员后验概率
估计并绘制每个点的第一组件的后验概率。
p =后验(Gm,x);图分散(x(cluster1,1),x(cluster1,2),10,p(cluster1,1),'+') 抓住在散射(X (cluster2, 1), X (cluster2, 2), 10, P (cluster2, 1),'o') 抓住离开clrmap =喷气机(80);colormap (clrmap (9:72:)) ylabel (colorbar,“成分1后验概率”)传说(“集群1”,《集群2》,'地点',“最佳”) 标题(“散点图和聚类1后验概率”)

P是一个n-2集群成员资格概率的2个矩阵。第一列包含集群1的概率,第二列对应于群集2。
将新数据分配给群集
你也可以用the集群方法将新数据点分配给原始数据中发现的混合组分。
从高斯分布的混合模拟新数据。而不是使用mvnrnd,您可以使用下面的方法创建具有真正混合成分的平均值和标准偏差的GMMGMDistribution.,然后通过GMM到随机模拟数据。
μ= [mu1;mu2];σ=猫(3 sigma1 sigma2);P = [0.75 0.25];%混合比例gmtrue = Gmdistribution(mu,sigma,p);x0 =随机(Gmtrue,75);
通过通过装有的GMM为新数据分配群集(通用汽车)和新数据集群.请求集群成员身份后部概率。
[idx0, ~, P0] =集群(通用,X0);图fcontour (gmPDF [min (X0 (: 1)) max (X0(: 1))最小(X0(:, 2))最大(X0 (:, 2))))在gscatter (X0 (: 1), X0 (:, 2), idx0,rb的,'+ o')传说(“安装GMM轮廓”,“集群1”,《集群2》,'地点',“最佳”) 标题(“新数据集群分配”) 抓住离开
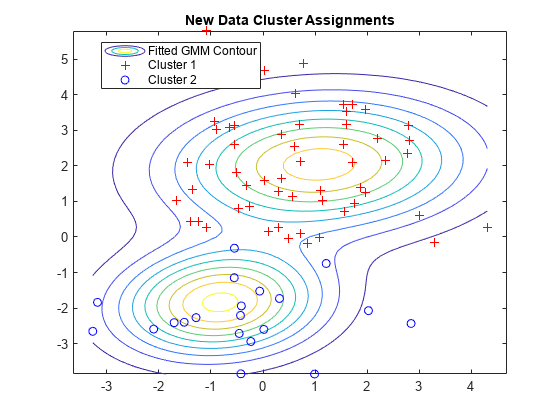
为集群为了在聚类新数据时提供有意义的结果,X0应该来自相同的人群X,用来创建混合分布的原始数据。特别是在计算后验概率时X0,集群和后使用估计的混合概率。
另请参阅
集群|fitgmdist|GMDistribution.|后|随机
相关话题
您还可以从以下列表中选择一个网站:
