集群中使用高斯混合模型
本主题使用统计和机器学习工具箱™函数介绍高斯混合模型(GMM)的聚类簇,以及一个示例,该示例展示了在拟合GMM模型时指定可选参数的效果fitgmdist。
如何高斯混合模型Cluster数据
高斯混合模型(的GMM)通常用于数据聚类。您可以使用转基因微生物要么执行硬群集或柔软的聚类的查询数据。
去表演硬聚类,所述GMM受让人查询数据点,以最大化该组件后验概率多元正常组分,给出的数据。也就是说,给定一个装有GMM,簇将查询数据分配给产生最高后验概率的组件。硬集群将数据点精确地分配给一个集群。关于如何将GMM拟合到数据,使用拟合模型进行聚类,并估计组件后验概率的示例,请参见集群混合高斯数据使用硬聚类。
此外,还可以使用GMM来对数据进行更灵活的集群,被称为柔软的(要么模糊)集群。软聚类方法分配分数为每个簇的数据点。的分数的值指示数据点到集群的关联强度。相对于硬聚类方法,软聚类方法是灵活的,因为他们可以将数据点分配到多个集群。当您执行GMM集群,得分的后验概率。对于具有GMM软聚类的一个例子,请参见集群混合高斯数据使用软聚类。
GMM聚类可以容纳具有在其中不同的尺寸和相关结构的簇。因此,在某些应用中,, GMM聚类可以比的方法,如更合适ķ——集群。与许多集群方法一样,GMM集群要求在拟合模型之前指定集群的数量。集群的数量指定了GMM中组件的数量。
对于转基因微生物,请遵循以下最佳做法:
考虑部件的协方差结构。您可以指定对角或全协方差矩阵,以及所有部件是否有相同的协方差矩阵。
指定的初始条件。该期望最大化(EM)算法适合GMM。如ķ-means聚类算法,EM对初始条件敏感,可能会收敛到局部最优。可以为参数指定自己的起始值,为数据点指定初始集群分配,或者随机选择数据点,或者指定参数的使用ķ-means ++算法。
实现正规化。举例来说,如果你有超过个数据点的预测,那么你可以为正规化估计稳定性。
用不同的协方差选项和初始条件拟合GMM
本实施例中探讨指定为协方差结构和初始条件不同的选项时执行GMM聚类的影响。
加载费舍尔的虹膜数据集。考虑聚类萼片测量,并使用测量萼片在2- d可视化的数据。
负载fisheriris;X =量(:,1:2);(氮、磷)= (X)大小;情节(X (: 1) X (:, 2),'','MarkerSize',15);标题(“费舍尔”的虹膜数据集”);xlabel('萼片长度(cm)');ylabel(“萼片宽度(厘米)”);
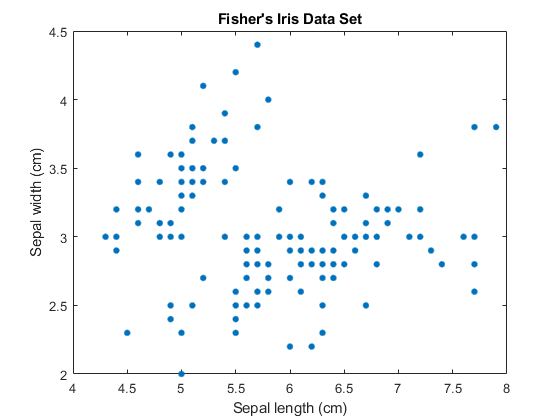
组件的数量ķ在GMM确定亚群体,或簇的数目。在此图中,很难确定是否两个,三个,或者更高斯要素是适当的。一个GMM的复杂性随着ķ增大。
指定不同的协方差结构选项
每个高斯分量具有协方差矩阵。几何上,协方差结构决定的置信度的椭球形状绘制在一个集群。您可以指定所有组件的协方差矩阵是否对角线或完整,以及所有部件是否有相同的协方差矩阵。规格每个组合确定椭圆体的形状和取向。
为EM算法指定三个GMM组件和1000个最大迭代。为了重现性,设置随机种子。
RNG(3);K = 3;GMM组件数量%选项= statset(“麦克斯特”,1000);
指定协方差结构的选择。
σ= {“对角线”,'充分'};%选项为协方差矩阵类型nSigma = numel(Sigma公司);SharedCovariance = {TRUE,FALSE};%指标为相同或不相同的协方差矩阵SCtext = {'真正',“假”};NSC = numel(SharedCovariance);
创建一个2-D网格覆盖平面由极端的测量。稍后将使用此网格在集群上绘制置信椭圆。
d = 500;%网格长度X1 = linspace(分钟(X(:,1)) - 2,MAX(X(:,1))+ 2,d);X2 = linspace(分钟(X(:,2)) - 2,MAX(X(:,2))+ 2,d);[x1grid,x2grid] = meshgrid(X1,X2);X0 = [x1grid(:) x2grid(:)];
指定以下内容:
对于协方差结构选项的所有组合,适合一个三分量的GMM。
使用拟合GMM集群的2-d网格。
获取为每个置信区域指定99%概率阈值的分数。这个规格决定了椭球体的长轴和短轴的长度。
颜色的每个椭圆形使用类似的颜色作为其集群。
阈值= SQRT(chi2inv(0.99,2));计数= 1;为我= 1:nSigma为(X,k,)'CovarianceType',西格玛{I},...'SharedCovariance',SharedCovariance {Ĵ}“选项”,选项);%合身GMMclusterX =簇(gmfit,X);%簇索引mahalDist =泰姬陵(gmfit, X0);从每个网格点的每个GMM部件%距离%在每个GMM分量上绘制椭球,并显示聚类结果。副区(2,2,计数);H1 = gscatter(X(:,1),X(:,2),clusterX);保持上为M = 1:K = IDX mahalDist(:,米)<=阈值;颜色= H1(米)。颜色* 0.75 - 0.5 *(H1(米)。颜色 - 1);H2 =情节(X0(IDX,1),X0(IDX,2),'','颜色',颜色,'MarkerSize',1);uistack(H2,'底部');结束情节(gmfit.mu(:,1),gmfit.mu(:,2),'KX',“线宽”2,'MarkerSize',10)的标题(的sprintf('西格玛为%s \ nSharedCovariance =%s' 的,西格玛{I},{SCtext}Ĵ),“字形大小”8)传说(h1, {'1','2','3'})举行从计数=计数+ 1;结束结束
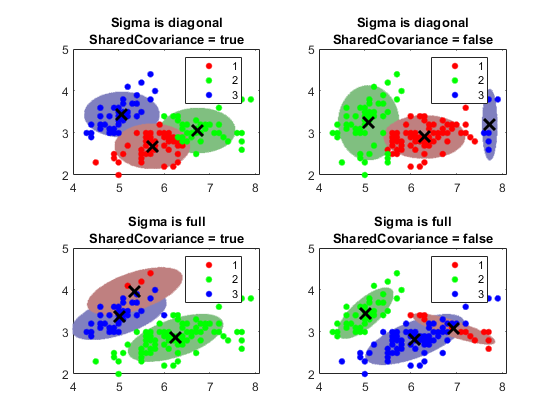
的信任区中的概率阈值确定长轴和短轴的长度,和协方差类型决定的轴线的方向。注意有关的协方差矩阵选项如下:
对角线协方差矩阵表明该预测是不相关的。椭圆的长轴和短轴平行或垂直于X和ÿ轴。本说明书中通过增加的参数的总数 ,预测器的数目,对于每个部件,但是比全协方差说明书更简洁。
完整的协方差矩阵允许相关预测,没有限制到椭圆的相对方位X和ÿ轴。每个组件通过增加的参数的总数 ,但是捕获了预测器之间的关联结构。这个规格可能会导致过拟合。
共享协方差矩阵表示所有分量具有相同的协方差矩阵。所有的椭圆都有相同的大小和相同的方向。此规范比非共享规范更节省,因为参数的总数只增加了一个组件的协方差参数的数量。
非共享的协方差矩阵表明每个组件都有自己的协方差矩阵。所有椭圆的大小和方向可能会有所不同。本说明书中通过增加参数的数量ķ乘以一个组件的协方差参数的数量,但是可以捕获组件之间的协方差差异。
图中还显示了簇并不总是保持集群顺序。如果您群集几个装gmdistribution楷模,簇可以用于类似的部件分配不同的簇标签。
指定不同的初始条件
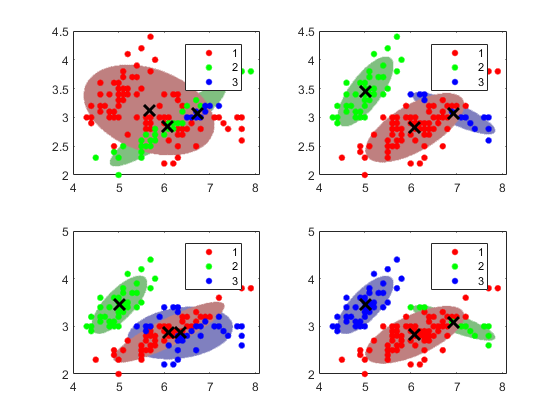
使GMM与数据匹配的算法对初始条件很敏感。为了说明这种敏感性,拟合四个不同的gmm如下:
对于第一个GMM,分配大多数数据指向第一个集群。
对于第二GMM,随机指定的数据点簇。
对于第三GMM,使数据点到另一个集群随机分配。
对于第四GMM,使用ķ-表示++获取初始集群中心。
initialCond1 = [(n-8, 1);[2;2;2;2);[3;3;3;3]];%对于第一GMMinitialCond2 = randsample (1: k, n,真的);%对于第二GMMinitialCond3 = randsample(1:K,N,TRUE);%对于第三GMMinitialCond4 =“+”;%对于第四GMMcluster0 = {initialCond1;initialCond2;initialCond3;initialCond4};
对于所有的情况下,使用ķ= 3层的组件,非共享和完全协方差矩阵,相同的初始混合物的比例,和相同的初始协方差矩阵。对于稳定性,当你尝试不同的设置初始值,增加EM算法迭代次数。此外,笼络集群信心椭球。
聚合=南(4,1);为(X,k,'CovarianceType','充分',...'SharedCovariance',假,'开始',cluster0 {j},...“选项”,选项);clusterX =簇(gmfit,X);%簇索引mahalDist =泰姬陵(gmfit, X0);从每个网格点的每个GMM部件%距离%在每个GMM分量上绘制椭球,并显示聚类结果。副区(2,2,j)的;H1 = gscatter(X(:,1),X(:,2),clusterX);从每个网格点的每个GMM部件%距离保持上;nK =元素个数(独特(clusterX));为m = 1时:为nK IDX = mahalDist(:,米)<=阈值;颜色= H1(米)。颜色* 0.75 + -0.5 *(H1(米)。颜色 - 1);H2 =情节(X0(IDX,1),X0(IDX,2),'','颜色',颜色,'MarkerSize',1);uistack(H2,'底部');结束情节(gmfit.mu(:,1),gmfit.mu(:,2),'KX',“线宽”2,'MarkerSize',10)图例(H1,{'1','2','3'});保持从聚合(j) = gmfit.Converged;%指标收敛结束
总和(融合)
ANS = 4
所有算法融合。每个数据点的初始集群分配都会导致不同的、符合的集群分配。可以为名称-值对参数指定一个正整数“重复测试”,它运行的算法的指定次数。后来,fitgmdist选择能产生最大可能性的契合。
当以规范
有时,EM算法的迭代期间,拟合协方差矩阵可以成为病态的,这意味着可能性逃逸到无穷大。如果一个或多个下列条件存在可能发生此问题:
你比个数据点的预测。
您指定了太多的部件装配。
变量是高度相关的。
为了克服这个问题,你可以使用指定一个小的正数“RegularizationValue”名称 - 值对的参数。fitgmdist增加了该号码的所有协方差矩阵的对角元素,这确保了所有矩阵是正定的。规制可以降低最大似然值。
模型符合统计数据
在大多数应用中,组件的数量ķ和适当的协方差结构Σ是未知的。优化GMM的一种方法是比较信息标准。两种流行的信息准则是赤基信息准则(AIC)和贝叶斯信息准则(BIC)。
两者AIC和BIC采取优化,负对数似然,然后用参数模型的数目(该模型复杂性)惩罚它。然而,BIC的复杂性惩罚比AIC更严重。因此,AIC往往会选择更复杂的模型可能过度拟合,而BIC倾向于选择简单的模型可能underfit。一个好的做法是评估模型时看两个标准。较低的AIC或BIC值表明更好的拟合模型。另外,确保你的选择ķ协方差矩阵结构适合你的应用。fitgmdist存储AIC和BIC装gmdistribution在属性的模型对象另类投资会议和BIC。您可以通过使用点表示法访问这些属性。有关说明如何选择适当的参数的例子,见调整高斯混合模型。
也可以看看
相关话题
您还可以选择从下面的列表中的网站:
