代码生成和分类学习应用
分类学习者非常适合交互地选择和训练分类模型,但它不会生成基于训练模型标记数据的C/ c++代码。的生成功能按钮出口分类学习者app部分生成MATLAB代码用于训练模型,但不生成C/ c++代码。这个示例展示了如何从一个使用导出的分类模型预测标签的函数生成C代码。本例根据以下步骤建立了一个模型,该模型预测了给定各种财务比率的企业的信用评级:
使用信用评级数据集的文件中
CreditRating_Historical.dat,包含在统计和机器学习工具箱™中。采用主成分分析(PCA)减少数据维数。
火车一组模型的支持代码生成标签预测。万博1manbetx
具有最小导出模型5倍,交叉验证的分类精度。
从该变换新的预测数据,然后预测使用导出的模型对应的标签的入口点函数生成的C代码。
装入样本数据
加载样本数据,并将数据导入到分类学习应用。查看使用散点图中的数据并删除不必要的预测。
使用readtable在文件中加载历史信用评级数据集CreditRating_Historical.dat到表。
企业资信= readtable(“CreditRating_Historical.dat”);
在应用程序选项卡,单击分类学习者。
在分类学习,在分类学习者选项卡,文件部分中,点击新建会话并选择从工作区。
在New Session对话框中,选择表信用评级。所有的变量,除确定为响应之一,是双精度数值向量。请点击开始会议比较基于5倍交叉验证的分类精度的分类模型。
分类学习者加载数据和图表的变量散点图WC_TA与ID。由于身份证号码也没有什么帮助的阴谋显示,选择RE_TA对于X下预测。
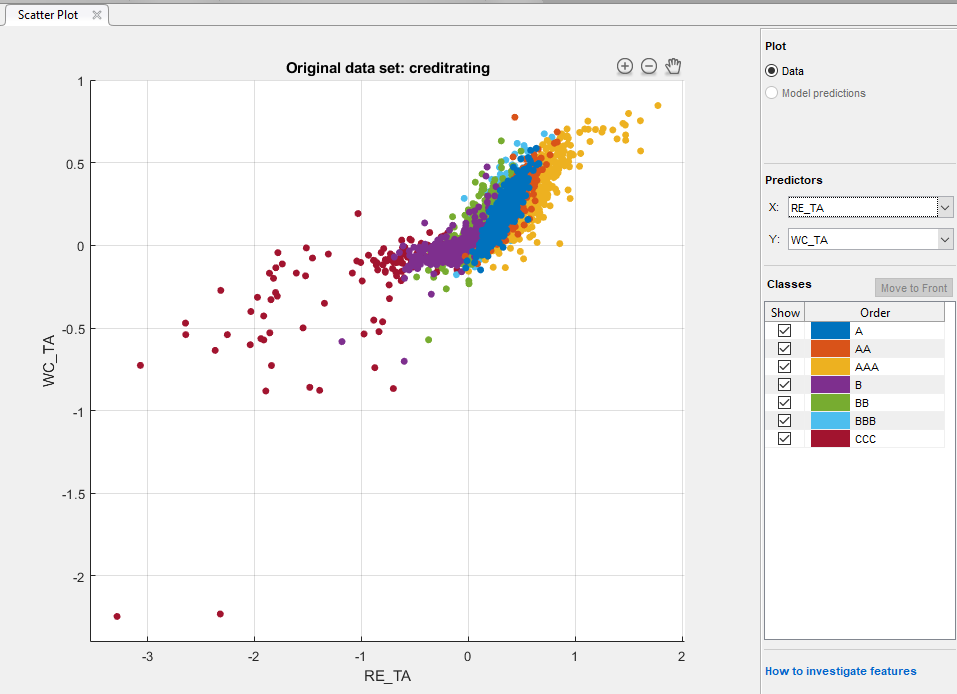
散点图表明这两个变量可以分离类AAA,BBB,BB,CCC相当好。然而,对应于剩余类的意见被混合到这些类。
身份证号码是不是预测很有帮助。因此,在特征部分中,点击特征选择然后清除ID复选框。您还可以通过在新建会话使用对话框中的复选框去掉从一开始就没有必要预测。这个例子显示,当你已经囊括了所有的预测如何删除未使用的预测生成代码。
启用PCA
启用PCA以减少数据维度。
在特征部分中,点击PCA,然后选择启用PCA。此操作适用于PCA预测数据,然后训练模型前转换数据。分类学习者只使用共同解释了变异的95%的部件。
火车模型
火车一组模型的支持代码生成标签预测。万博1manbetx
选择以下分类模型和选项,支持代码生成标签预测,然后进行交叉验证(更多详情,请参阅万博1manbetx代码生成简介)。选择每个模型中,型号类型部分中,单击显示更多箭头,然后单击模型。选择模型并指定任何选项之后,关闭任何打开的菜单,然后单击培养在里面训练部分。
| 模型和选项可供选择 | 描述 |
|---|---|
| 下决策树中,选择所有的树 | 各种复杂的分类树 |
| 下万博1manbetx支持向量机中,选择所有支持向量机 | 各种复杂的支持向量机和使用不同的内核。复杂支持向量机需要时间来适应。 |
| 下集成分类器中,选择提高了树。在型号类型部分中,点击高级。减少拆分的最大数量来五和增加许多学习者来One hundred.。 | 提升了分类树的集合 |
| 下集成分类器中,选择袋装树。在型号类型部分中,点击高级。增加拆分的最大数量来50和增加许多学习者来One hundred.。 | 分类树的随机森林 |
后交叉验证每个模型类型,数据浏览器显示每个模型和它的5倍,交叉验证分类准确度,和与亮点最佳的精度模型。
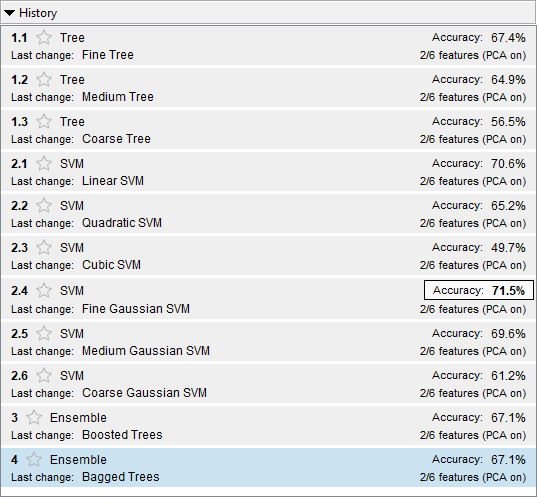
选择产生最大5倍,交叉验证分类精度,这是精细高斯SVM学习者的纠错输出编码(ECOC)模型模型。启用PCA,分类学习者使用两个预测出六个。
在地块部分中,点击混淆矩阵。
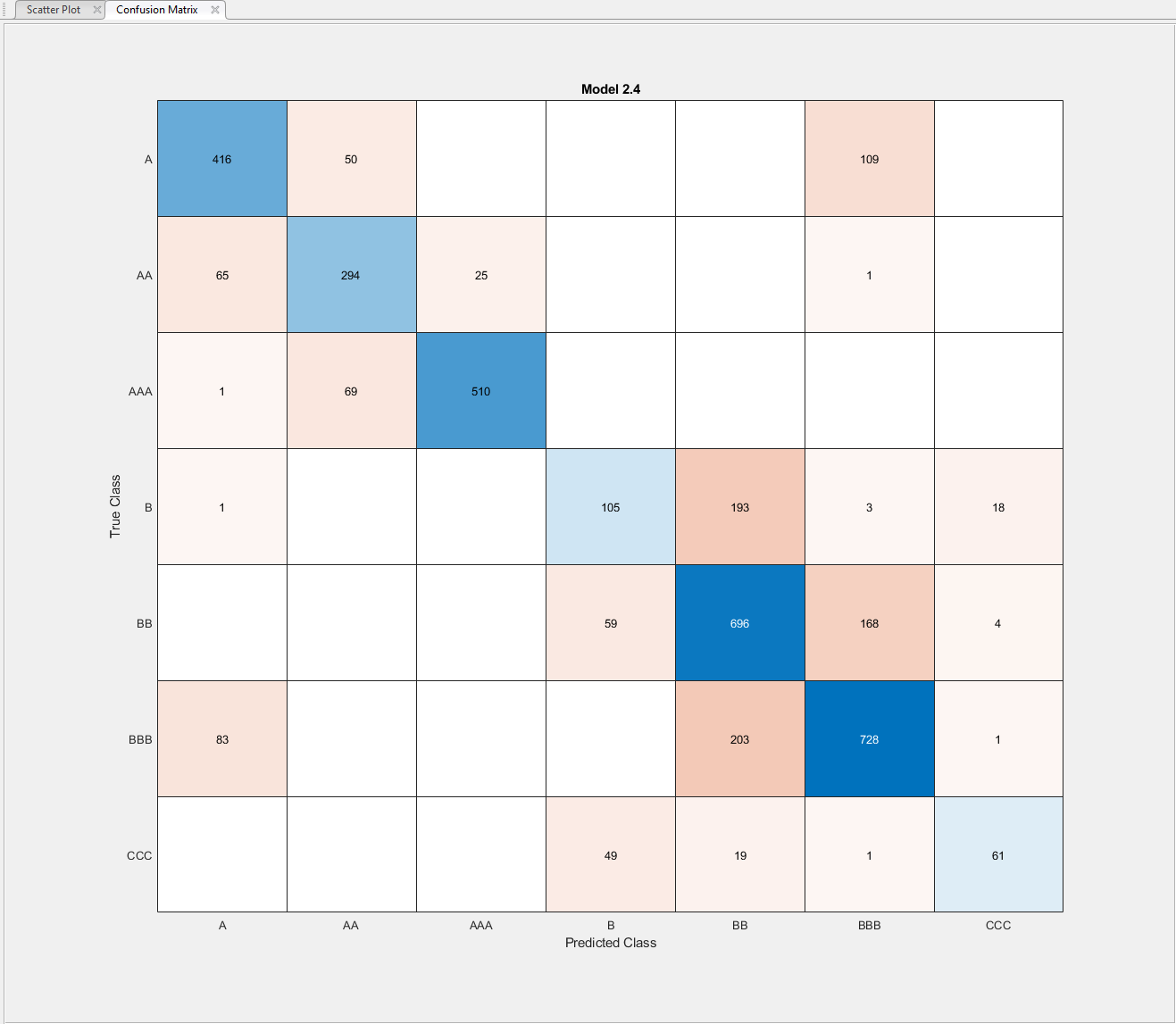
该模型并不好之间的区分一个,乙,C类。然而,该模型并不能很好地区分这些组中的特定级别,特别是较低的B级别。
导出模型到工作区
导出模型到MATLAB®工作空间并保存模型使用saveLearnerForCoder。
在出口部分中,点击出口模式,然后选择出口紧凑型。请点击好吧在对话框中。
结构trainedModel出现在MATLAB工作区。场ClassificationSVM的trainedModel包含了紧凑型。
在命令行中,保存紧凑型到一个名为ClassificationLearnerModel.mat在当前文件夹。
saveLearnerForCoder (trainedModel.ClassificationSVM'ClassificationLearnerModel')
生成预测的C代码
预测使用对象的功能需要一个训练有素的模型对象,但-args的选择codegen不接受这样的对象。通过使用来绕过这个限制saveLearnerForCoder和loadLearnerForCoder。通过使用保存一个训练好的模型saveLearnerForCoder。然后,定义一个入口点函数,使用以下命令加载保存的模型loadLearnerForCoder并调用预测功能。最后,使用codegen生成的入口点函数的代码。
数据进行预处理
以同样的方式预处理新的数据你预处理训练数据。
为了预处理,需要以下三个模型参数:
removeVars- 最多列向量p识别变量索引的元素从所述数据,其中除去p是预测变量的原始数据的数量pcaCenters- 正好行向量q主成分分析中心pcaCoefficients-q-通过-[RPCA系数,其中矩阵[R最多是q
指定预测变量的您在使用选择数据删除索引特征选择在分类学习者。摘自PCA统计trainedModel。
removeVars = 1;pcaCenters = trainedModel.PCACenters;pcaCoefficients = trainedModel.PCACoefficients;
保存模型参数指定的文件ModelParameters.mat在当前文件夹。
保存('ModelParameters.mat','removeVars','pcaCenters','pcaCoefficients');
定义入口点函数
一个入口点函数是你定义的代码生成功能。因为你不能使用在顶级调用任何函数codegen,您必须定义一个调用支持代码生成的函数的入口点函数,然后使用codegen。
在当前文件夹,定义一个名为功能mypredictCL.m:
接受数字矩阵(
X)含有相同的预测变量原始观测的作为的那些传递到分类学习者加载分类模型
ClassificationLearnerModel.mat和模型参数ModelParameters.mat删除对应于指数的预测变量
removeVars变换使用PCA中心剩余的预测数据(
pcaCenters)和系数(pcaCoefficients)通过分类学习者估计返回使用模型预测标签
函数标记= mypredictCL(X)% # codegen使用模型%MYPREDICTCL分类信用评级从出口%分类学习% MYPREDICTCL加载经过训练的分类模型(SVM)和模型%参数(removeVars,pcaCenters,和pcaCoefficients),去除在X对应于预测数据的原始矩阵的列%% index在removeVars中,使用主成分分析变换结果矩阵%中心和PCA系数的pcac效率,则%使用转换后的数据进行分类的信用评级。X是一个数字n行7列的%矩阵。label是一个n乘1的单元格数组%预测标签。训练的分类模型和模型参数SVM = loadLearnerForCoder('ClassificationLearnerModel');数据= coder.load (“ModelParameters”);removeVars = data.removeVars;pcaCenters = data.pcaCenters;pcaCoefficients = data.pcaCoefficients;%删除未使用的预测变量keepvars = 1:大小(X, 2);idx = ~ ismember (keepvars removeVars);keepvars = keepvars (idx);XwoID = X (:, keepvars);通过%PCA变换预测Xpca = bsxfun (@minus XwoID pcaCenters) * pcaCoefficients;%从支持向量机生成标签标记=预测(SVM,Xpca);结束
生成代码
因为C和c++是静态类型语言,所以必须在编译时确定入口函数中所有变量的属性。指定大小可变的参数coder.typeof并使用的参数生成代码。
创建一个名为双精度矩阵X代码生成使用coder.typeof。的行数X是任意的,但那X一定有p列。
P =尺寸(企业资信,2) - 1;X = coder.typeof(0,[Inf文件,P],[1 0]);
有关指定大小可变的参数的更多详细信息,请参阅为代码生成指定可变大小的参数。
生成从MEX函数mypredictCL.m。使用-args选项来指定X作为参数。
codegenmypredictCL-argsX
codegen生成MEX文件mypredictCL_mex.mexw64在当前文件夹。文件扩展名取决于您的平台。
验证生成的代码
验证MEX函数返回预期的标签。
从原始数据集中去除响应变量,然后随机绘制15个观测值。
RNG('默认');%用于重现m = 15;testsampleT = datasample(creditrating(:,1:(end - 1)),m);
预计通过使用相应的标签predictFcn在分类学习器训练的分类模型中。
testLabels = trainedModel.predictFcn(testsampleT);
所得到的表转换成一个矩阵。
testsample = table2array (testsampleT);
的列testsample对应于由分类学习者加载的预测数据的列。
通过测试数据mypredictCL。功能mypredictCL预测相应的标签预测分类学习器训练的分类模型。
testLabelsPredict = mypredictCL (testsample);
预测通过使用所生成的MEX功能相应的标签mypredictCL_mex。
testLabelsMEX = mypredictCL_mex(testsample);
比较两组预测。
ISEQUAL(testLabels,testLabelsMEX,testLabelsPredict)
ANS =逻辑1
是平等的返回逻辑1(真),如果所有的输入是相等的。predictFcn,mypredictCL和MEX函数返回的值相同。
也可以看看
codegen|coder.typeof|learnerCoderConfigurer|loadLearnerForCoder|saveLearnerForCoder
相关的话题
您也可以从以下列表中选择网站:
