使用核平滑的条件分位数估计
这个例子展示了如何使用分位数随机森林估计给定预测数据的响应的条件分位数,并通过使用核平滑估计响应的条件分布函数。
quantile-estimation速度,quantilePredict,oobQuantilePredict,quantileError,oobQuantileError使用线性插值来预测响应条件分布中的分位数。但是,您可以获得响应权值,它由分布函数组成,然后将它们传递给ksdensity以计算速度为代价获得精度。
从模型生成2000个观察结果
是均匀分布在0和1之间的吗 。将数据存储在表中。
n = 2000;rng (“默认”);%的再现性t = randsample (linspace (0, 1, 1 e2), n, true) ';ε= randn (n, 1)。* sqrt (t。^ 2/2 + 0.01);Y = 0.5 + t +;台=表(t, y);
使用整个数据集训练一组袋装回归树。指定200个弱学习者并保存out- bag索引。
rng (“默认”);%的再现性Mdl = TreeBagger(200台,“y”,“方法”,“回归”,...“OOBPrediction”,“上”);
Mdl是一个TreeBagger合奏。
对所有训练样本观测进行包外、条件0.05和0.95分位数(90%置信区间)预测oobQuantilePredict,即通过插值。请求响应权重。记录执行时间。
Tau = [0.05 0.95];tic [quantInterp,yw] = oobQuantilePredict(Mdl, yw)分位数的,τ);timeInterp = toc;
quantInterp是一个94 × 2的预测分位数矩阵;行对应于Mdl。X列对应的分位数概率τ。yw为94 × 94稀疏响应权矩阵;行对应训练样本观测值,列对应Mdl。X。响应权重是独立的τ。
使用核平滑预测包外、条件0.05和0.95分位数并记录执行时间。
n =元素个数(Tbl.y);quantKS = 0 (n,元素个数(τ));%预先配置抽搐为j = 1:n quantKS(j,:) = ksdensity(Tbl.y,tau,“函数”,“icdf”,“重量”yw (:, j));结束timeKS = toc;
quantKS是符合quantInterp。
评估核平滑估计和插值之间的执行时间比率。
timeKS / timeInterp
ans = 4.3864
执行核平滑比执行插值需要更多的时间。这个比率取决于您的机器的内存,因此结果会有所不同。
用两组预测分位数绘制数据。
[圣,idx] = (t)进行排序;图;h1 =情节(t y“。”);持有在h2 =情节(sT, quantInterp (idx:)“b”);h3 =情节(sT, quantKS (idx:)“r”);传奇([h1 h2 (1) h3(1)]。“数据”,“插值”,内核平滑的);标题(分位数估计的)举行从
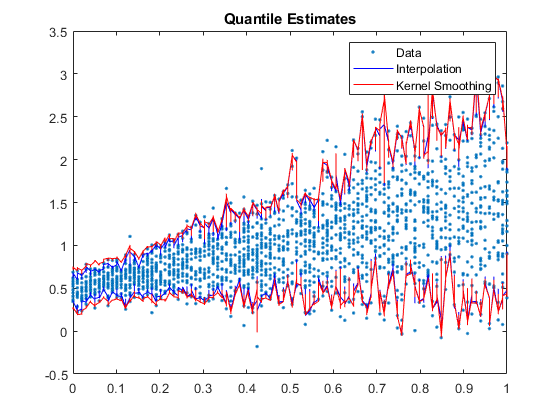
两组估计分位数相当一致。但是,对于较小的值,从插值的分位数间隔显得稍微紧凑t而不是核平滑。
另请参阅
ksdensity|oobQuantilePredict|TreeBagger|TreeBagger
相关的话题
你也可以从以下列表中选择一个网站:
