TreeBagger类
决策树包
描述
TreeBagger将决策树集合用于分类或回归。Bagging代表引导聚合。集合中的每棵树都是在输入数据的独立绘制的引导副本上生长的。不包括在这个副本中的观察结果对于这个树来说是“out of bag”。
TreeBagger依赖于ClassificationTree和RegressionTree生长单独的树的功能。特别是,ClassificationTree和RegressionTree接受为每个决策分割随机选择的特性数量作为可选输入参数。也就是说,TreeBagger实现随机森林算法[1].
对于回归问题,TreeBagger万博1manbetx支持均值和分位数回归(即分位数回归森林)[2]).
为了预测平均响应或估计给定数据的均方误差,通过
TreeBagger模型和数据预测或错误,分别。要对袋外观察执行类似的操作,请使用oobPredict或oobError.为了估计响应分布的分位数或给定数据的分位数误差,通过a
TreeBagger模型和数据quantilePredict或quantileError,分别。要对袋外观察执行类似的操作,请使用oobQuantilePredict或oobQuantileError.
建设
| TreeBagger | 创建决策树包 |
对象的功能
附加 |
添加新树到集合 |
紧凑的 |
决策树的紧凑集成 |
错误 |
误差(误分类概率或MSE) |
fillprox |
训练数据的接近矩阵 |
growTrees |
训练额外的树,并添加到整体 |
保证金 |
分类保证金 |
mdsprox |
接近矩阵的多维尺度 |
meanMargin |
意思是分类保证金 |
oobError |
Out-of-bag错误 |
oobMargin |
Out-of-bag利润率 |
oobMeanMargin |
Out-of-bag意味着利润 |
oobPredict |
包外观测的集合预测 |
oobQuantileError |
回归树袋外分位数损失 |
oobQuantilePredict |
从回归树的袋外观察的分位数预测 |
partialDependence |
计算部分依赖 |
plotPartialDependence |
创建部分依赖图(PDP)和个人条件期望图(ICE) |
预测 |
使用袋装决策树预测响应 |
quantileError |
使用回归树的袋的分位数损失 |
quantilePredict |
预测响应分位数使用袋回归树 |
属性
|
包含响应变量的类名的单元格数组 |
|
一个逻辑标志,指定是否应该计算训练观察的包外预测。默认值是 如果这面旗是
如果这面旗是
|
|
一个逻辑标志,指定是否应该计算变量重要性的包外估计。默认值是 如果这面旗是
|
|
方阵, 这个属性是:
|
|
返回的默认值
|
|
大小为1 × -的数字数组据nvar将分割标准的变化通过每个变量的分割进行求和,并在整个已长成的树木集合中取平均值。 |
|
随机选择的观察结果的一部分,并替换每个引导副本。每个副本的大小为脑袋× |
|
对于不降低总风险的拆分,是否合并具有相同父类的决策树叶子的逻辑标志。默认值为 |
|
树木使用的方法。可能的值是 |
|
每片树叶的最低观察次数。默认情况下, |
|
集合中等于决策树数目的标量值。 |
|
大小为1 × -的数字数组据nvar,其中每个元素给出了这个预测器上所有树的分割数。 |
|
为每个决策分裂随机选择的预测器或特征变量的数目。默认情况下, |
|
逻辑阵列大小脑袋——- - - - - -NumTrees,在那里脑袋训练数据中的观察数和NumTrees为集合中树的数量。一个 |
|
大小数字数组脑袋-by-1包含用于计算每次观测的袋外响应的树的数量。脑袋为用于创建集合的训练数据中的观测数。 |
|
大小为1 × -的数字数组据nvar包含对每个预测变量(特征)的变量重要性的度量。对于任何一个变量,如果该变量的值在包外观察值中排列,则度量值是提高保证金的数量和降低保证金的数量之间的差异。对每棵树计算这个度量,然后在整个集合上取平均值,再除以整个集合上的标准差。对于回归树,此属性为空。 |
|
大小为1 × -的数字数组据nvar包含每个预测变量(特征)的重要性度量。对于任何一个变量,如果该变量的值是在袋子外的观察值中排列的,则度量是预测误差的增加。对每棵树计算这个度量,然后在整个集合上取平均值,再除以整个集合上的标准差。 |
|
大小为1 × -的数字数组据nvar包含每个预测变量(特征)的重要性度量。对于任何变量,如果该变量的值在包外观察值中排列,则度量是分类边际的减少。对每棵树计算这个度量,然后在整个集合上取平均值,再除以整个集合上的标准差。对于回归树,此属性为空。 |
|
有大小的数字数组脑袋1,脑袋为训练数据中的观测数,包含每个观测值的离群值。 |
|
每个类的先验概率的数字向量。元素的顺序 这个属性是:
|
|
有大小的数字矩阵脑袋——- - - - - -脑袋,在那里脑袋为训练数据中的观测数,包含观测值之间的接近度度量值。对于任意两个观测值,它们的接近度定义为这些观测值落在同一片叶子上的树木的比例。这是一个对称矩阵,对角线和非对角线上的元素从0到1都有1s。 |
|
的 |
|
一个逻辑标志,指定是否对每个具有替换的决策树进行数据采样。此属性 |
|
|
|
大小相同的单元格数组NumTrees-by-1包含集合中的树。 |
|
大小矩阵据nvar——- - - - - -据nvar通过变量关联的预测措施,对整个成年树木进行平均。如果你增加了布景 |
|
包含预测变量(特性)名称的单元格数组。 |
|
长度权值的数值向量脑袋,在那里脑袋为训练数据中的观察数(行)。 |
|
有大小的表格或数字矩阵脑袋——- - - - - -据nvar,在那里脑袋观察数(行数)和据nvar为训练数据中变量(列)的个数。如果你用一个预测值表来训练集合,那么 |
|
一个大小脑袋响应数据数组。的元素 |
例子
袋装分类树的序列集合
载入费雪的虹膜数据集。
负载fisheriris
使用整个数据集训练一组袋装分类树。指定50弱的学习者。存储每棵树的观察结果。
rng (1);%的再现性Mdl = TreeBagger(50、量、物种,“OOBPrediction”,“上”,...“方法”,“分类”)
Mdl = TreeBagger Ensemble with 50 bagged decision trees: Training X: [150x4] Training Y: [150x1] Method: classification NumPredictors: 4 NumPredictorsToSample: 2 MinLeafSize: 1 InBagFraction: 1 SampleWithReplacement: 1 ComputeOOBPrediction: 1 ComputeOOBPredictorImportance: 0 Proximity: [] ClassNames:'setosa' 'versicolor' 'virginica'属性,方法
Mdl是一个TreeBagger合奏。
Mdl。树存储经过训练的分类树的50 × 1细胞向量(CompactClassificationTree模型对象)组成集成。
绘制第一个训练的分类树的图。
视图(Mdl。{1},“模式”,“图”)

默认情况下,TreeBagger深树生长。
Mdl。OOBIndices将包外索引存储为逻辑值矩阵。
用已生长的分类树的数量绘制出包外误差。
图;oobErrorBaggedEnsemble = oobError (Mdl);情节(oobErrorBaggedEnsemble)包含“已长成的树的数量”;ylabel“Out-of-bag分类错误”;

袋外误差随着树木的生长而减小。
要给袋子外的观察做标记,请放过Mdl来oobPredict.
袋装回归树的序列集合
加载carsmall数据集。考虑一个模型,它可以预测给定发动机排量的汽车的燃油经济性。
负载carsmall
使用整个数据集训练一组袋装回归树。指定100个弱学习者。
rng (1);%的再现性Mdl = TreeBagger(位移,100英里,“方法”,“回归”);
Mdl是一个TreeBagger合奏。
使用训练过的回归树包,您可以估计条件均值响应或执行分位数回归来预测条件分位数。
对于最小和最大样本内位移之间的十个等间距发动机位移,预测条件平均响应和条件四分位数。
predX = linspace (min(位移),max(位移),10)';predX mpgMean =预测(Mdl);mpgQuartiles = quantilePredict (Mdl predX,分位数的, 0.25, 0.5, 0.75);
在同一图中绘制观察结果、估计平均响应和四分位数。
图;情节(位移,英里/加仑,“o”);持有在情节(predX mpgMean);情节(predX mpgQuartiles);ylabel (的燃油经济性);包含(发动机排量的);传奇(“数据”,“平均响应”,第一四分位数的,“中值”,“第三四分位数”);

无偏预测重要估计
加载carsmall数据集。考虑一个模型,它可以预测一辆汽车的平均燃油经济性,该模型给出了汽车的加速度、汽缸数、发动机排量、马力、制造商、车型年份和重量。考虑气缸,制造行业,Model_Year作为分类变量。
负载carsmall气缸=分类(缸);及时通知=分类(cellstr (Mfg));Model_Year =分类(Model_Year);X =表(加速、气缸、排量、马力、制造行业,...Model_Year、重量、MPG);rng (“默认”);%的再现性
显示类别变量中表示的类别数量。
numCylinders =元素个数(类别(气缸))
numCylinders = 3
numMfg =元素个数(类别(有限公司))
numMfg = 28
numModelYear =元素个数(类别(Model_Year))
numModelYear = 3
因为只有3个类别气缸和Model_Year在标准CART中,预测器分割算法更喜欢分割连续预测器而不是这两个变量。
使用整个数据集训练一个包含200棵回归树的随机森林。要种植无偏的树,指定使用曲率测试的分裂预测器。由于数据中缺少值,请指定代理拆分的用法。存储包外信息用于预测因子的重要性估计。
Mdl = TreeBagger (200 X,“英里”,“方法”,“回归”,“代孕”,“上”,...“PredictorSelection”,“弯曲”,“OOBPredictorImportance”,“上”);
TreeBagger商店可以预测物业的重要性OOBPermutedPredictorDeltaError.用条形图比较估计值。
小鬼= Mdl.OOBPermutedPredictorDeltaError;图;酒吧(imp);标题(“弯曲测试”);ylabel (的预测估计的重要性);包含(“预测”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;

在这种情况下,Model_Year最重要的预测因素是什么重量.
比较小鬼用于预测从使用标准CART生长树木的随机森林中计算的重要性估计值。
MdlCART = TreeBagger (200 X,“英里”,“方法”,“回归”,“代孕”,“上”,...“OOBPredictorImportance”,“上”);impCART = MdlCART.OOBPermutedPredictorDeltaError;图;酒吧(impCART);标题(“标准车”);ylabel (的预测估计的重要性);包含(“预测”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
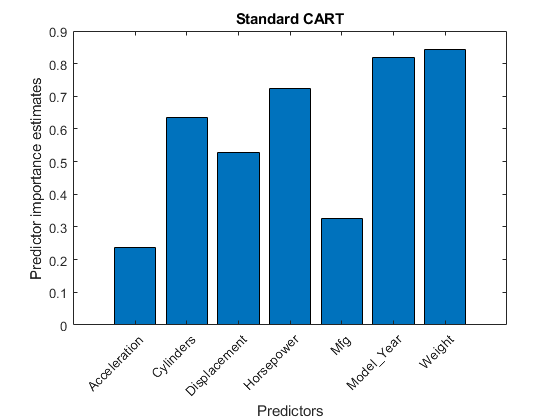
在这种情况下,重量这是最重要的。接下来两个最重要的预测因素是Model_Year紧随其后的是马力,这是一个连续的预测器。
复制语义
价值。要了解这如何影响您对类的使用,请参见比较句柄类和值类在MATLAB®面向对象编程的文档。
提示
对于一个TreeBagger模型对象B,树属性存储的单元格向量B.NumTreesCompactClassificationTree或CompactRegressionTree模型对象。用于树的文本或图形显示t在细胞载体中,输入
视图(B。树木{t})
选择功能
Statistics and Machine Learning Toolbox™提供了三种对象用于套袋和随机森林:
详细了解两者的区别TreeBagger以及袋装套装(ClassificationBaggedEnsemble和RegressionBaggedEnsemble),看套袋式和套袋式的比较.
参考文献
[1] Breiman, L。随机森林。机器学习45,pp. 5-32, 2001。
[2] Meinshausen, N.“分位数回归森林”机器学习研究杂志,第7卷,2006年,第983-999页。
你也可以从以下列表中选择一个网站:
