绘图竞争依赖性
创建部分依赖图(PDP)和个人条件期望图(ICE)
语法
描述
例子
创建部分相关图
使用的方法训练回归树Carsmall.数据集,并创建一个PDP,该PDP显示特征和经过训练的回归树中的预测响应之间的关系。
加载Carsmall.数据集。
负载Carsmall.
指定重量那气瓶,马力为预测变量(X), 和MPG.作为响应变量(y)。
X =(重量、气缸、马力);Y = MPG;
使用回归树使用X和y.
Mdl = fitrtree (X, Y);
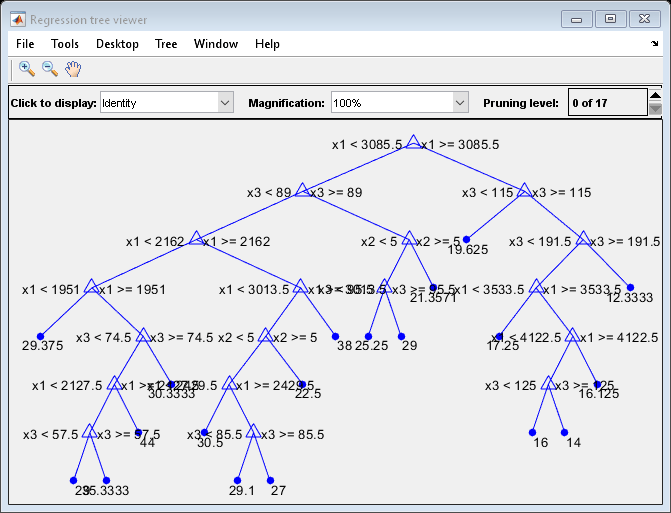
查看经过训练的回归树的图形显示。
查看(MDL,“模式”那'图形')
创建第一个预测变量的PDP,重量.
plotPartialDependence (Mdl, 1)
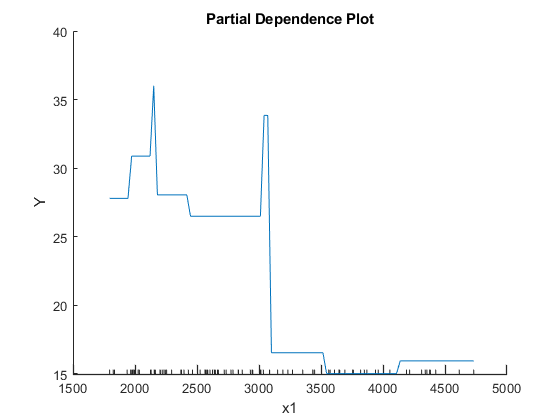
这条标绘线代表了两者之间的平均部分关系重量(标记为x1) 和MPG.(标记为y)在训练的回归树中Mdl. 这个X-轴次刻度表示中的唯一值x1.
回归树查看器显示第一个决定是x1小于3085.5。PDP还显示了附近的大变化x1= 3085.5。树查看器根据预测器变量在每个节点处可视化每个节点的每个决定。您可以找到基于值的几个节点x1,但确定依赖y在x1不简单。然而绘图竞争依赖性绘图平均预测反应x1,所以你可以清楚地看到部分依赖y在x1.
标签x1和y是预测器名称和响应名称的默认值。您可以通过指定名称-值对参数来修改这些名称'predictornames'和'responsebame'当你训练Mdl使用fitrtree..您还可以使用轴标签来修改轴标签XLabel.和伊拉贝尔功能。
为多个类创建部分依赖性绘图
用。训练朴素贝叶斯分类模型渔民数据集,并创建一个PDP,显示预测变量和多个类别的预测分数(后验概率)之间的关系。
加载渔民数据集,包括物种(物种)及尺寸(量)萼片长度,萼片宽度,花瓣长度和花瓣宽度为150鸢尾标本。数据集包含来自三种种类中的每一个的50个标本:Setosa,Versicolor和Virginica。
负载渔民
培训一个天真的贝叶斯分类模型物种作为响应量为预测因子。
MDL = FITCNB(MEAS,物种);
创建一个PDP的分数预测Mdl对于所有三个课程物种对阵第三预测变量x3.通过使用该标签来指定类标签Classnames.的属性Mdl.
plotPartialDependence (Mdl 3 Mdl.ClassNames);
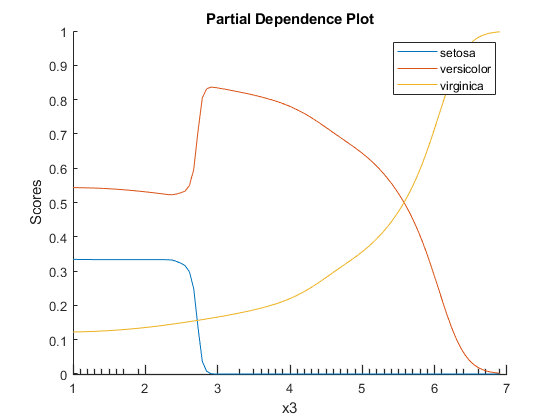
根据该模型,概率弗吉尼亚州增加x3. 发生的概率setosa从哪里约0.33x3是0到2.5左右,然后概率下降到几乎0。
创建个人有条件期望地块
使用生成的样本数据训练高斯过程回归模型,其中响应变量包括预测变量之间的交互作用。然后,创建ICE图,显示每个观测的特征和预测响应之间的关系。
生成样本预测器数据x1和x2.
RNG('默认')重复性的%n = 200;x1 =兰德(n - 1) * 2 - 1;x2 =兰德(n - 1) * 2 - 1;
生成响应值,包括之间的交互x1和x2.
y = x1-2 * x1。*(x2> 0)+ 0.1 * rand(n,1);
使用Gaussian进程回归模型[x1 x2]和y.
mdl = fitrgp([x1 x2],y);
为第一个预测器创建一个包括PDP(红线)的图x1的散点图(圆形标记)x1并预测响应,并通过指定进行一组冰块(灰线)“条件”作为'中心'.
plotPartialDependence (Mdl 1“条件”那'中心')
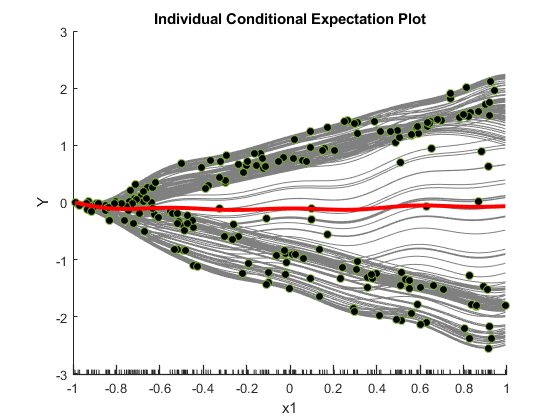
什么时候“条件”是'中心'那绘图竞争依赖性偏移图,使所有图从零开始,这有助于检查所选特征的累积效应。
PDP找到平均的关系,因此它不会透露隐藏的依赖项,特别是当响应包括特征之间的交互时。然而,冰块清楚地表明了两个不同的回应依赖性x1.
部分相关图使用新的预测数据
训练分类模型的集合并创建两个pdp,一个使用训练数据集,另一个使用新数据集。
加载人口普查1994.数据集,其中包含美国的年薪数据,分类为<= 50K.或> 50 k,以及一些人口统计学变量。
负载人口普查1994.
从表中提取要分析的变量子集AdultData.和成人测试.
X = adultdata (: {'年龄'那“workClass”那“education_num”那“marital_status”那“种族”那......“性”那'资本收益'那'capital_loss'那“每周小时数”那'薪水'});xnew = Adulttest(:,{'年龄'那“workClass”那“education_num”那“marital_status”那“种族”那......“性”那'资本收益'那'capital_loss'那“每周小时数”那'薪水'});
用。训练分类器集合薪水作为响应,其余变量使用函数作为预测器fitcensemble.对于二进制分类,fitcensemble使用Logitboost.方法。
mdl = fitcensemble(x,'薪水');
检查类名Mdl.
mdl.classnames.
ans =.2×1分类<= 50k> 50k
创建所预测的分数的部分依赖关系图Mdl第二类薪水(> 50 k)反对预测指标年龄使用培训数据。
plotPartialDependence(MDL,'年龄'Mdl.ClassNames (2))

为类创建一个分数的PDP> 50 k反对年龄使用来自表的新预测仪数据XNew..
plotPartialDependence(MDL,'年龄'Xnew Mdl.ClassNames (2))

这两张图显示了预测高分的部分依赖性的相似形状薪水(> 50 k) 在年龄. 这两个曲线图都表明,高薪的预测分数在30岁之前快速上升,然后在60岁之前几乎保持不变,然后快速下降。然而,根据新数据绘制的曲线图显示,65岁以上的人得分略高。
比较预测变量的重要性
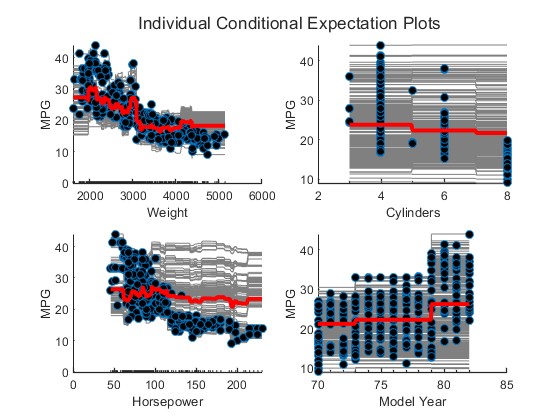
使用培训回归的集合Carsmall.数据集,并使用新数据集为每个预测变量创建PDP绘图和冰块,CARBIG.. 这个n, compare the figures to analyze the importance of predictor variables. Also, compare the results with the estimates of predictor importance returned by the预测的重要性函数。
加载Carsmall.数据集。
负载Carsmall.
指定重量那气瓶那马力,model_year.为预测变量(X), 和MPG.作为响应变量(y)。
X =[重量、气缸、马力,Model_Year];Y = MPG;
使用训练回归集成X和y.
mdl = fitrensemble(x,y,......'predictornames', {“重量”那“汽缸”那“马力”那'模型年'},......'responsebame'那'mpg');
通过使用绘图竞争依赖性和预测的重要性功能。的绘图竞争依赖性函数可视化所选预测值和预测响应之间的关系。预测的重要性总结预测器具有单个值的重要性。
为每个预测器创建一个包括PDP图(红线)和ICE图(灰线)的图绘图竞争依赖性并指定“有条件的”,“绝对”.每个图还包括一个散点图(圆圈标记)的选定预测器和预测响应。同时,加载CARBIG.数据集并将其用作新的预测器数据,XNew..当你提供XNew.,绘图竞争依赖性功能使用XNew.而不是中的预测数据Mdl.
负载CARBIG.Xnew =[重量、气缸、马力,Model_Year];图t = tiledlayout(2,2,“瓦莱斯帕奇”那'袖珍的');标题(T,“个体条件期望图”)为i = 1:4 nextdile plotpartialdendence(mdl,i,xnew,“条件”那“绝对”) 标题('')结尾
计算通过使用计算预测的预测值估计预测的重要性.该函数对每个预测器的分裂导致的均方误差(MSE)的变化进行求和,然后除以分支节点的数量。
Imp = predictorimportance(mdl);图酒吧(IMP)标题(“预测重要性估计”) ylabel (“估计”)包含('预测者') ax = gca;斧子。XTickLabel = Mdl.PredictorNames;
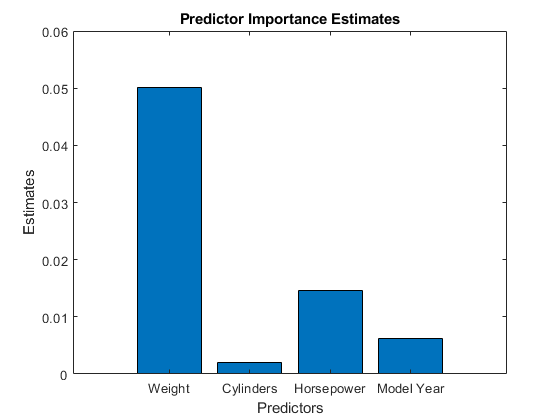
变量重量对最有影响力MPG.根据预测的重要性。PDP的重量也表明,MPG.高度依赖于重量. 这个variable气瓶影响最小MPG.根据预测的重要性。PDP的气瓶也表明,MPG.取决于气瓶.
从图中提取部分依赖估计
训练支持向量机(万博1manbetxSVM)回归模型使用Carsmall.数据集,并为两个预测变量创建PDP。然后,从输出中提取部分依赖估计值绘图竞争依赖性.或者,您可以通过使用来获得部分依赖值部分竞争函数。
加载Carsmall.数据集。
负载Carsmall.
指定重量那气瓶那取代,马力为预测变量(Tbl)。
台=表(重量、汽缸、排量、马力);
使用SVM回归模型使用Tbl和响应变量MPG..使用具有自动内核刻度的高斯内核功能。
mdl = fitrsvm(tbl,mpg,'responsebame'那'mpg'那......'pationoricalpricictors'那“汽缸”那'标准化',真的,......'骨箱'那“高斯”那'kernelscale'那'汽车');
创建一个PDP,可视化预测响应的部分依赖(MPG.)在预测器变量上重量和气瓶. 指定要计算其部分相关性的查询点重量通过使用'querypoints'名称-值对的论点。您不能指定'querypoints'价值气瓶因为它是一个分类变量。绘图竞争依赖性使用所有分类值。
Pt = Linspace(min(重量),最大(重量),50)';AX = PlotPartialDependence(MDL,{“重量”那“汽缸”},'querypoints',{pt,[]});查看(140,30)%修改视角
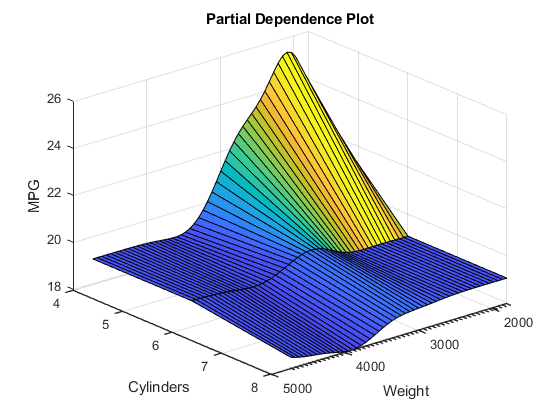
PDP显示了两者之间的相互作用效应重量和气瓶. 这个P.artial dependence ofMPG.在重量根据价值而变化气瓶.
提取估计的部分依赖MPG.在重量和气瓶. 这个XData那ydata.,Zdata.价值斧子。Children分别是x轴值(第一个选定的预测值)、y轴值(第二个选定的预测值)和z轴值(对应的部分相关性值)。
xval = ax.Children.XData;yval = ax.Children.YData;zval = ax.Children.ZData;
或者,您可以通过使用来获得部分依赖值部分竞争函数。
[PD,X,Y] = PartialDependence(MDL,{“重量”那“汽缸”},'querypoints',{pt,[]});
pd包含查询点的部分依赖值X和y.
如果您指定“条件”作为“绝对”那绘图竞争依赖性创建包括PDP,散点图和一组冰块的图。ax.Children (1)和ax.Children (2)分别对应于PDP和散点图。剩余的元素斧子。Children对应ICE图。的XData和ydata.价值ax.Children(我)分别是x轴值(选定的预测值)和y轴值(相应的部分相关性值)。
输入参数
输出参数
更多关于
算法
绘图竞争依赖性用A.预测功能预测响应或分数。绘图竞争依赖性选择适当的预测根据函数Mdl和跑步预测有其默认设置。有关每个人的详细信息预测函数,见预测以下两个表中的功能。如果Mdl是一种基于树的模型(不包括树木的升级的集成)和“条件”是'没有任何',然后绘图竞争依赖性使用加权遍历算法而不是预测函数。有关详细信息,请参见加权遍历算法.
回归模型对象
| 模型类型 | 完整或紧凑的回归模型对象 | 预测响应的功能 |
|---|---|---|
| 决策树集成的Bootstrap聚合 | CompactTreeBagger. |
预测 |
| 决策树集成的Bootstrap聚合 | TreeBagger |
预测 |
| 回归模型集成 | RegressionEnsemble那回归释迦缩短那CompactRegressionEnsemble |
预测 |
| 高斯内核回归模型使用随机特征扩展 | 回归科内尔 |
预测 |
| 高斯过程回归 | 回归方程那CompactregressionGP. |
预测 |
| 广义线性混合效应模型 | GeneralizeLmixedModel. |
预测 |
| 广义线性模型 | GeneralizedLinearModel那紧致广义线性模型 |
预测 |
| 线性混合效应模型 | linearmixedmodel. |
预测 |
| 线性回归 | linearmodel.那紧凑线性模型 |
预测 |
| 线性回归用于高维数据 | 回归线性 |
预测 |
| 非线性回归 | NonLinearModel |
预测 |
| 回归树 | 回归树那Compactregressiontree. |
预测 |
| 万博1manbetx支持向量机回归 | 回归vm.那压缩回归 |
预测 |
分类模型对象
| 模型类型 | 完整或紧凑分类模型对象 | 预测标签和分数的功能 |
|---|---|---|
| 判别分析分类器 | 分类Discriminant.那CompactClassificationDiscriminant. |
预测 |
| 支持向量机或其他分类器的多类模型万博1manbetx | ClassificationECOC那CompactClassificationECOC |
预测 |
| 学习者的集体融合 | 分类符号那压缩分类插入码那分类BaggedAssemble |
预测 |
| 高斯核分类模型使用随机特征展开 | 分类核 |
预测 |
| K.最近的邻居分类器 | ClassificationKnn. |
预测 |
| 线性分类模型 | 分类线性 |
预测 |
| 多类朴素贝叶斯模型 | 分类朴素贝叶斯那CompactClassificationNaiveBayes |
预测 |
| 万博1manbetx支持向量机器分类器进行单级和二进制分类 | 分类VM.那CompactClassificationSVM |
预测 |
| 用于多类分类的二叉决策树 | 分类树那CompactClassificationTree. |
预测 |
| 袋装决策树的合奏 | TreeBagger那CompactTreeBagger. |
预测 |
替代功能
部分竞争计算不可视化的部分依赖性。该函数可以在一次函数调用中计算两个变量和多个类的部分依赖关系。
参考
[2] Goldstein,Alex,Adam Kapelner,Justin Bleich和Emil Pitkin。“偷看黑匣子里面:用个人有条件期望的情节可视化统计学习。”中国计算与图形统计学报24日,没有。1(2015年1月2日):44-65。
[3] Hastie,Trevor,Robert Tibshirani和Jerome Friedman。统计学习的要素。纽约,纽约:施普林格纽约,2001。
扩展能力
您还可以从以下列表中选择一个网站:
