预测
预测标签高斯核分类模型
描述
例子
预测训练集标签
预测使用二进制内核分类模型训练集的标签,并显示所得到的分类的混淆矩阵。
加载电离层数据集。该数据集具有34个预测和雷达回波351个二进制应答,要么坏('B')或良好('G')。
加载电离层
培养一个二进制内核分类模型,识别是否该雷达回波是坏的('B')或良好('G')。
RNG('默认')%用于重现MDL = fitckernel(X,Y);
MDL是ClassificationKernel模型。
预测训练集,或resubstitution,标签。
标记=预测(MDL,X);
构造一个混淆矩阵。
ConfusionTrain = confusionchart(Y,标签);

该模型misclassifies一个雷达回波为每个类。
预计测试组标签
预测使用二进制内核分类模型测试设置的标签,并显示所得到的分类的混淆矩阵。
加载电离层数据集。该数据集具有34个预测和雷达回波351个二进制应答,要么坏('B')或良好('G')。
加载电离层
分区中的数据集分成训练和测试集。指定测试组15%的保留样本。
RNG('默认')%用于重现分区= cvpartition(Y,'坚持',0.15);trainingInds =训练(分区);对于训练集%指标testInds =试验(分区);对于测试集%指数
训练使用训练集的二进制内核分类模型。一个好的做法是定义类的顺序。
MDL = fitckernel(X(trainingInds,:),Y(trainingInds),“类名”{'B','G'});
预测训练集标签和测试集的标签。
labelTrain =预测(MDL,X(trainingInds,:));labelTest =预测(MDL,X(testInds,:));
构建训练集的混淆矩阵。
ConfusionTrain = confusionchart(Y(trainingInds),labelTrain);

该模型misclassifies只有一个雷达回波为每个类。
构建用于测试集混淆矩阵。
ConfusionTest = confusionchart(Y(testInds),labelTest);

该模型misclassifies一个坏的雷达回波做一个好的回报,五个好雷达回波为糟糕的回报。
估计后验概率类
为测试组估计后验类概率,并且通过绘制一个接收器操作特性(ROC)曲线确定模型的质量。核心分类模型返回只有回归学习者的后验概率。
加载电离层数据集。该数据集具有34个预测和雷达回波351个二进制应答,要么坏('B')或良好('G')。
加载电离层
分区中的数据集分成训练和测试集。指定测试组30%的保留样本。
RNG('默认')%用于重现分区= cvpartition(Y,'坚持',0.30);trainingInds =训练(分区);对于训练集%指标testInds =试验(分区);对于测试集%指数
培养一个二进制内核分类模型。适合logistic回归学习者。
MDL = fitckernel(X(trainingInds,:),Y(trainingInds),...“类名”{'B','G'},'学习者',“物流”);
预测测试集的后验概率类。
[〜,后] =预测(MDL,X(testInds,:));
因为MDL具有一个正则化强度,输出后是具有两列的矩阵和行等于测试设定观测值的数目。柱一世包含的后验概率Mdl.ClassNames(I)给定一个特定的观察。
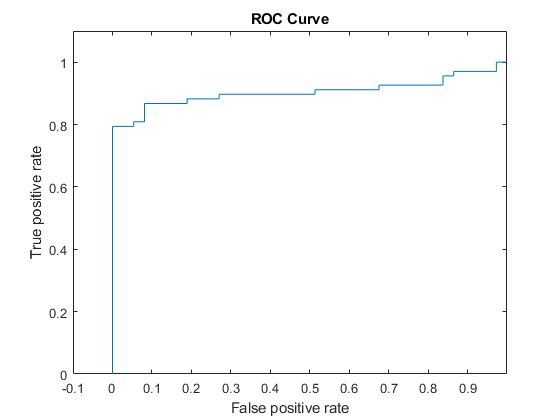
获取虚假和真实的阳性率,曲线(AUC)下估计的区域。指定第二类是积极类。
[FPR,TPR,〜,AUC] = perfcurve(Y(testInds),后(:,2),Mdl.ClassNames(2));AUC
AUC = 0.9042
该AUC接近1,这表明该模型预测标签良好。
绘制ROC曲线。
数字;情节(FPR,TPR)H = GCA;h.XLim(1)= -0.1;h.YLim(2)= 1.1;xlabel(“假阳性率”)ylabel(“真阳性率”)标题(“ROC曲线”)
输入参数
输出参数
更多关于
扩展功能
介绍了在R2017b
您还可以选择从下面的列表中的网站:
