灌注
接收器操作特性(ROC)曲线或分类器输出的其他性能曲线
句法
描述
例子
绘制ROC曲线进行Logistic回归分类
加载示例数据。
加载fisheriris
只使用前两个特性作为预测变量。定义一个二元分类问题,仅使用与品种versicolor和virginica对应的测量值。
pred =量(51:结束,1:2);
定义二进制响应变量。
resp =(1:100)'> 50;% vericcolor = 0, virginica = 1
拟合逻辑回归模型。
mdl = fitglm (pred职责,“分布”,“二”,“链接”,分对数的);
计算ROC曲线。使用逻辑回归模型的概率估计作为分数。
成绩= mdl.Fitted.Probability;(X, Y, T, AUC) = perfcurve(物种(51:,:),分数,'virginica');
灌注存储数组中的阈值T.
显示曲线下的面积。
AUC
AUC = 0.7918
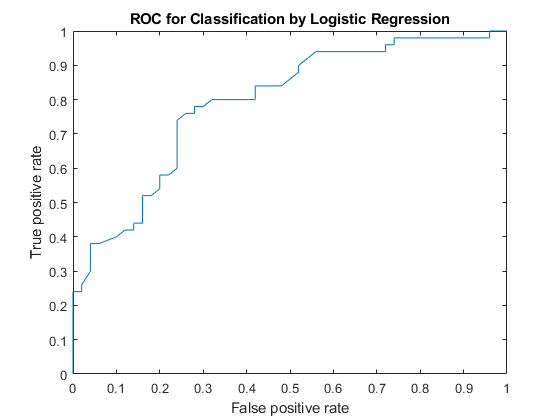
曲线下的面积是0.7918。最大AUC为1,对应一个完美分类器。AUC值越大表示分类器性能越好。
绘制ROC曲线。
情节(X, Y)包含(的假阳性率) ylabel ('真正的阳性率')标题(“ROC的分类Logistic回归”)
使用ROC曲线比较分类方法
加载示例数据。
加载电离层
X是一个351x34的预测值实值矩阵。Y是类标签的字符数组:“b”因为雷达信号不好‘g’良好的雷达返回。
重新格式化响应以适应逻辑回归。使用预测变量3到34。
resp = strcmp (Y,“b”);% rep = 1,如果Y = 'b',如果Y = 'g',则返回0pred = X (: 34);
拟合逻辑回归模型来估计雷达返回差的后验概率。
mdl = fitglm (pred职责,“分布”,“二”,“链接”,分对数的);score_log = mdl.Fitted.Probability;%概率估计
使用分数的概率计算标准的ROC曲线。
[xlog,ylog,tlog,auclog] = perfcurve(resp,score_log,“真正的”);
在同一样本数据上训练SVM分类器。标准化数据。
mdlSVM = fitcsvm (pred职责,'标准化',真正的);
计算后验概率(分数)。
mdlsvm = fitposterior(mdlsvm);[〜,score_svm] = ResubPredict(MDLSVM);
第二列score_svm包含错误的雷达回波的后验概率。
使用支持向量机模型的分数计算标准ROC曲线。
[Xsvm, Ysvm Tsvm AUCsvm] = perfcurve(职责,score_svm (:, mdlSVM.ClassNames),“真正的”);
在同一样本数据上拟合朴素贝叶斯分类器。
mdlNB = fitcnb (pred、职责);
计算后验概率(分数)。
[〜,score_nb] = resubPredict(mdlNB);
使用朴素贝叶斯分类的分数计算标准ROC曲线。
[xnb,ynb,tnb,aucnb] = perfcurve(resp,score_nb(:,mdlnb.classnames),“真正的”);
在同一个图上绘制ROC曲线。
情节(Xlog Ylog)在情节(Xsvm Ysvm)情节(Xnb Ynb)传说(逻辑回归的,“万博1manbetx支持向量机”,“天真的贝叶斯,“位置”,“最佳”)包含(的假阳性率);ylabel ('真正的阳性率');标题(用于Logistic回归、支持向量机和朴素贝叶斯分类的ROC曲线)举行离开

尽管SVM更高的门槛产生更好的ROC值,回归平常更好地区别于好的坏的雷达回波是。对于朴素贝叶斯ROC曲线是通常比其他两个ROC曲线,其指示样品中的性能比其它两种分类方法更差低。
比较所有三个分类器的曲线下的区域。
AUClog
AUClog = 0.9659
AUCsvm
AUCsvm = 0.9489
AUCnb
AUCnb = 0.9393
Logistic回归的AUC值最高,朴素贝叶斯的AUC值最低。这一结果表明,logistic回归对该样本数据具有更好的样本内平均性能。
确定自定义内核函数的参数值
这个例子展示了如何使用ROC曲线在分类器中为自定义核函数确定更好的参数值。
在单位圆内生成一组随机点。
rng (1);重复性的%n = 100;%每象限的点数r1 =√兰特(2 * n, 1));%随机半径t1 =[π/ 2 *兰德(n, 1);(π/ 2 *兰德(n - 1) +π)];% Q1和Q3的随机角度X1 = [r1.*cos(t1) r1.*sin(t1)];% Polar-to-Cartesian转换r2 =√兰特(2 * n, 1));t2 =[π/ 2 *兰德(n, 1) +π/ 2;(π/ 2 *兰德(n, 1) -π/ 2)];%随机的角度为Q2和Q4X2 = [R2 * COS(T2)R2 * SIN(T2)。。];
定义预测变量。在第一和第三象限的标记点属于正类,而在第二和第四象限的标记点属于负类。
pred = [X1;X2);resp = 1 (4 * n, 1);rep (2*n + 1:end) = -1; / /结束%的标签
创建函数mysigmoid.m,它接受特征空间中的两个矩阵作为输入,并使用s形核将其转换为Gram矩阵。
函数G = mysigmoid (U, V)斜率伽马和拦截c%sigmoid内核函数γ= 1;c = 1;n = U*V' + c;结束
使用s形核函数训练SVM分类器。将数据标准化是一个很好的做法。
SVMModel1 = fitcsvm (pred职责,“KernelFunction”,“mysigmoid”,...'标准化',真正的);SVMModel1 = fitPosterior (SVMModel1);[~, scores1] = resubPredict (SVMModel1);
放伽马= 0.5;之内mysigmoid.m并保存为mysigmoid2.m.并使用调整后的s形核训练SVM分类器。
函数G = mysigmoid2(U,V)斜率伽马和拦截c%sigmoid内核函数伽马= 0.5;c = 1;n = U*V' + c;结束
SVMModel2 = fitcsvm (pred职责,“KernelFunction”,“mysigmoid2”,...'标准化',真正的);SVMModel2 = fitPosterior (SVMModel2);[~, scores2] = resubPredict (SVMModel2);
计算两种模型的ROC曲线和曲线下面积(AUC)。
~ (x1, y1, auc1] = perfcurve(职责,scores1 (:, 2), 1);[x2, y2, ~, auc2] = perfcurve(职责,scores2 (:, 2), 1);
绘制ROC曲线。
绘图(X1,Y1)保持在图(x2,y2)保持离开传奇(“γ= 1”,'伽玛= 0.5',“位置”,“本身”);Xlabel(的假阳性率);ylabel ('真正的阳性率');标题('通过SVM进行分类的ROC');
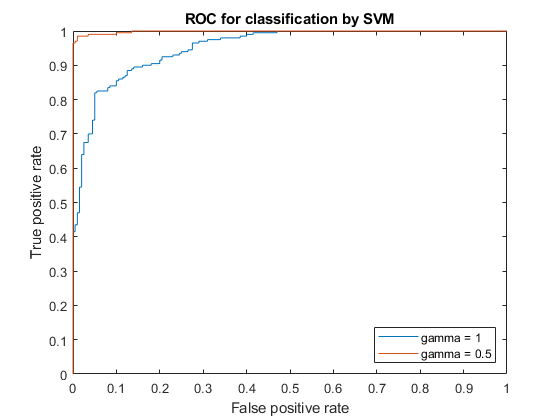
使用伽马参数设置为0.5的内核函数提供更好的样本结果。
比较AUC措施。
auc1 auc2
Auc1 = 0.9518 auc2 = 0.9985
gamma设置为0.5的曲线下面积比gamma设置为1的曲线下面积高。这也证实了gamma参数值为0.5会产生更好的结果。对于这两个gamma参数值的分类性能的视觉比较,请参见使用自定义内核列车SVM分类器.
绘制分类树的ROC曲线
加载示例数据。
加载fisheriris
列向量,物种,由三种不同种类的鸢尾花组成:蔷薇花(setosa)、花斑花(versicolor)、小virginia。双矩阵测定由花上的四种测量值组成:萼片长度,萼片宽度,花瓣长度和花瓣宽度。所有测量单位都是厘米。
以萼片长度和宽度作为预测变量,训练分类树。指定类名是一个很好的实践。
模型= fitctree(量(:,1:2),物种,...“类名”,{'setosa',“多色的”,'virginica'});
根据树预测物种的类标签和分数模型.
[~,分数]= resubPredict(模型);
分数是一个观察(数据矩阵中的一行)属于一个类的后验概率。的列分数对应于由指定的类“类名”.第一列对应setosa,第二列对应versicolor,第三列对应virginica。
给定真实的类别标签,计算观测属于versicolor的预测的ROC曲线物种.也计算最佳工作点和y负子类的值。返回负类的名称。
因为这是一个多字符问题,你不能仅仅是供应(得分:2)作为输入,灌注.这样做不会放弃灌注关于两个负类(setosa和virginica)的分数的足够信息。这个问题不像二元分类问题,在二元分类中,知道一个类的分数就足以决定另一个类的分数。因此,你必须提供灌注这个函数将两个负类的分数考虑在内。其中一个函数是
.
diffscore =分数(:,2) - 最大(评分(:,1),评分(:,3));[X,Y,T,〜,OPTROCPT,suby,子名] = perfcurve(物种,diffscore,“多色的”);
X,默认为假阳性率(辐射或1-特异性)和Y,默认为真实阳性率(召回率或灵敏度)。正class的标签是多色的.因为负类没有定义,灌注假设不属于正类的观察结果属于一类。函数接受它作为负类。
OPTROCPT
Optrocpt =1×20.1000 0.8000.
suby
suby =12×200 0.1800 0.1800 0.4800 0.4800 0.5800 0.5800 0.6200 0.8000 0.8000 0.8800 0.8800 0.9200 0.9200 0.9200 0.9600 0.9600 0.9800 0.9800⋮
subnames
subnames =1 x2单元格{' setosa} {' virginica '}
绘制ROC曲线和ROC曲线上的最佳操作点。
绘图(x,y)持有在情节(OPTROCPT (1) OPTROCPT (2),'ro')包含(的假阳性率) ylabel ('真正的阳性率')标题(“分类树分类的ROC曲线”)举行离开
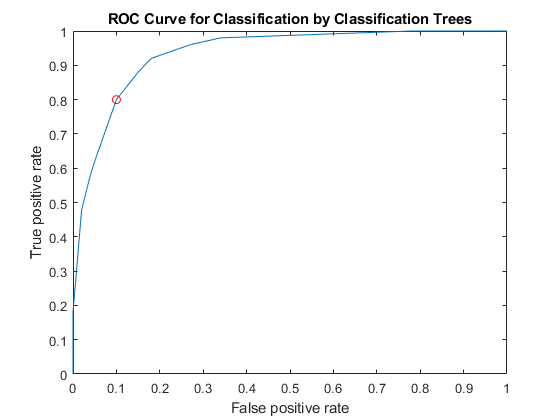
找出与最佳工作点对应的阈值。
T ((X = = OPTROCPT (1) & (Y = = OPTROCPT (2)))
ans = 0.2857
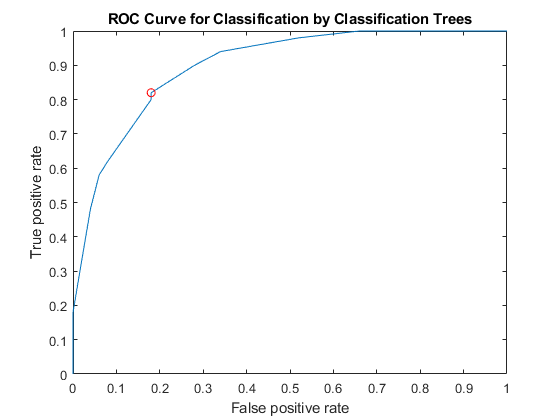
指定virginica为负类,计算并绘制ROC曲线多色的.
同样,你必须提供灌注与一个函数,在负类的得分因素。一个函数来使用的一个例子是
.
Diffscore = score(:,2) - score(:,3);[X, Y, ~, ~, OPTROCPT] = perfcurve(物种,diffscore,“多色的”,...“negClass”,'virginica');OPTROCPT
Optrocpt =1×20.1800 - 0.8200
人物,情节(X, Y)在情节(OPTROCPT (1) OPTROCPT (2),'ro')包含(的假阳性率) ylabel ('真正的阳性率')标题(“分类树分类的ROC曲线”)举行离开
计算ROC曲线的点向置信区间
加载示例数据。
加载fisheriris
列向量物种由三个不同品种的花菖蒲:setosa,云芝,弗吉尼亚。双矩阵测定由花上的四种测量值组成:萼片长度,萼片宽度,花瓣长度和花瓣宽度。所有测量单位都是厘米。
只使用前两个特性作为预测变量。定义一个二元问题,只使用对应于花斑和弗吉尼亚物种的测量值。
pred =量(51:结束,1:2);
定义二进制响应变量。
resp =(1:100)'> 50;% vericcolor = 0, virginica = 1
拟合逻辑回归模型。
mdl = fitglm (pred职责,“分布”,“二”,“链接”,分对数的);
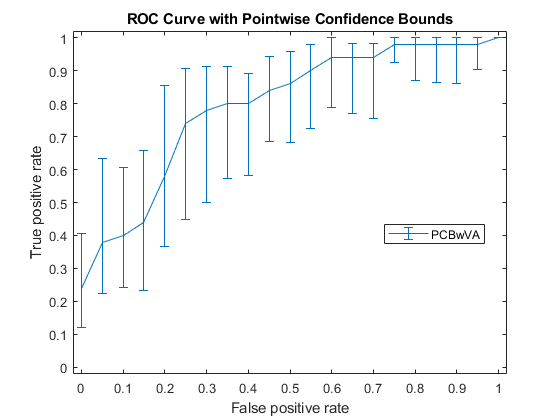
通过垂直平均(VA)和bootstrap抽样计算真阳性率(TPR)的点态置信区间。
[X, Y, T] = perfcurve(物种(51:,:),mdl.Fitted.Probability,...'virginica',“NBoot”, 1000,'xvals'[0:0.05:1]);
“NBoot”,1000年将引导副本的数量设置为1000。“XVals”、“所有”提示灌注返回X,Y, 和T值的所有分数,并平均Y值(真阳性率)X值(假阳性率)使用垂直平均。如果没有指定XVals, 然后灌注默认情况下使用阈值平均计算置信边界。
绘制点态置信区间。
errorbar(X,Y(:,1),Y(:,1)-Y(:,2),Y(:,3)-Y(:,1));xlim ([-0.02, 1.02]);ylim ([-0.02, 1.02]);Xlabel(的假阳性率) ylabel ('真正的阳性率')标题(“具有点态置信界限的ROC曲线”)传说(“PCBwVA”,“位置”,“最佳”)
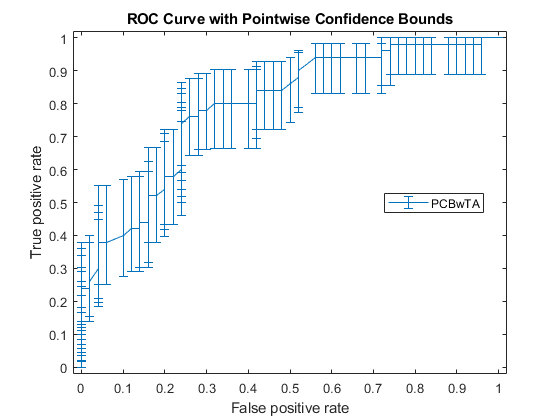
可能并不总是能够控制假阳性率(FPR, theX在该示例中的值)。所以,你可能要计算的真阳性率(TPR)的门槛平均逐点置信区间。
(X1, Y1, T1) = perfcurve(物种(51:,:),mdl.Fitted.Probability,...'virginica',“NBoot”,1000);
如果你设置“TVals”来“所有”,或者您没有指定“TVals”或'Xvals', 然后灌注返回X,Y, 和T的值,并计算逐点置信边界X和Y使用阈值平均值。
画出置信限。
图()errorbar (X1 (: 1), Y1(: 1),日元(:1)日元(:,2),日元(:,3)日元(:1));xlim ([-0.02, 1.02]);ylim ([-0.02, 1.02]);Xlabel(的假阳性率) ylabel ('真正的阳性率')标题(“具有点态置信界限的ROC曲线”)传说(“PCBwTA”,“位置”,“最佳”)
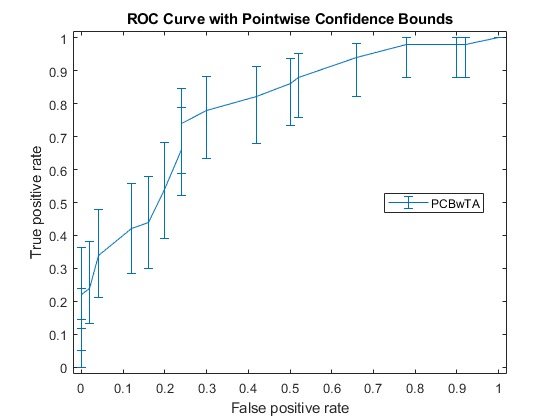
指定要固定的阈值并计算ROC曲线。然后画出曲线。
(X1, Y1, T1) = perfcurve(物种(51:,:),mdl.Fitted.Probability,...'virginica',“NBoot”, 1000,“TVals”, 0:0.05:1);图()errorbar (X1 (: 1), Y1(: 1),日元(:1)日元(:,2),日元(:,3)日元(:1));xlim ([-0.02, 1.02]);ylim ([-0.02, 1.02]);Xlabel(的假阳性率) ylabel ('真正的阳性率')标题(“具有点态置信界限的ROC曲线”)传说(“PCBwTA”,“位置”,“最佳”)
输入参数
输出参数
算法
参考文献
[1] t·福塞特。“ROC图:对研究者的注释和实用考虑”,2004。
Zweig, M.和G. Campbell。受试者工作特征(ROC)图:临床医学的基本评价工具中国。化学.1993, 39/4, 561-577页。
[3] Davis, J.和M. Goadrich。精度查全率与ROC曲线的关系ICML '06论文集, 2006,第233-240页。
莫斯科维茨和佩佩。“量化和比较连续预后因素对二元预后的预测准确性。”生物统计学, 2004, 5,页113-127。
黄勇,M. Pepe,冯志峰。"评估连续标记的预测性"华盛顿生物统计学论文系列,2006,250-261。
[6]布里格斯,W.,和R. Zaretzki。“该技能情节:图形技术评估连续诊断测试。”生物识别技术, 2008, 63,页250 - 261。
[7] r .赌博。使用ROC凸包方法进行代价敏感分类器选择SAS研究所.
扩展功能
你也可以从以下列表中选择一个网站:
