fitrtree
拟合二叉决策树进行回归
语法
描述
树= fitrtree (资源描述,ResponseVarName)资源描述而输出(响应)包含在资源描述。ResponseVarName.返回的树是二叉树,其中每个分支节点是根据列的值分割的资源描述.
例子
构造回归树
加载样例数据。
负载carsmall
使用样本数据构造一个回归树。响应变量是每加仑英里数,MPG。
tree = fitrtree([重量,气缸],MPG,...“CategoricalPredictors”2,“MinParentSize”, 20岁,...“PredictorNames”, {' W ',“C”})
tree = RegressionTree PredictorNames: {'W' 'C'} ResponseName: 'Y' CategoricalPredictors: 2 ResponseTransform: 'none' NumObservations: 94属性,方法
预测4000磅重的4缸、6缸和8缸汽车的里程。
MPG4Kpred = predict(tree,[4000 4;4000 6;4000 8])
MPG4Kpred =3×119.2778 19.2778 14.3889
控制回归树深度
fitrtree默认情况下生长深度决策树。您可以种植较浅的树,以减少模型复杂性或计算时间。要控制树木的深度,请使用“MaxNumSplits”,“MinLeafSize”,或“MinParentSize”名称-值对参数。
加载carsmall数据集。考虑位移,马力,重量作为反应的预测因素英里/加仑.
负载carsmallX =[排量马力重量];
用于增长回归树的树深度控制器的默认值是:
N - 1为MaxNumSplits.n是训练样本量。1为MinLeafSize.10为MinParentSize.
对于大的训练样本量,这些默认值往往生长得很深。
使用用于树深度控制的默认值训练回归树。使用10倍交叉验证对模型进行交叉验证。
rng (1);%用于再现性MdlDefault = fitrtree(X,MPG,“CrossVal”,“上”);
绘制树上施加的分裂数量的直方图。分割的数量比叶结点的数量少1。还有,看看其中一棵树。
numBranches = @(x)sum(x. isbranch);mdldefaultnumsplitting = cellfun(numBranches, MdlDefault.Trained);图;直方图(mdlDefaultNumSplits)

视图(MdlDefault。训练有素的{1},“模式”,“图”)

平均分裂次数在14到15次之间。
假设您想要一个回归树,它不像使用默认分割数训练的回归树那么复杂(深)。训练另一棵回归树,但将最大分割数设置为7,这大约是默认回归树中平均分割数的一半。使用10倍交叉验证对模型进行交叉验证。
Mdl7 = fitrtree(X,MPG,“MaxNumSplits”7“CrossVal”,“上”);视图(Mdl7。Trained{1},“模式”,“图”)

比较模型的交叉验证均方误差(mse)。
mseDefault = kfoldLoss(MdlDefault)
mseDefault = 25.7383
mse7 = kfoldLoss(Mdl7)
Mse7 = 26.5748
Mdl7的复杂程度要低得多,性能只比MdlDefault.
优化回归树
自动使用超参数优化fitrtree.
加载carsmall数据集。
负载carsmall
使用重量而且马力作为预测因素英里/加仑.通过使用自动超参数优化,找到最小化5倍交叉验证损失的超参数。
为了重现性,设置随机种子并使用“expected-improvement-plus”采集功能。
X =[重量,马力];Y = mpg;rng默认的Mdl = fitrtree(X,Y,“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,...“expected-improvement-plus”))
|======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 最好1 | | 3.2818 | 0.15504 | 3.2818 | 3.2818 | 28 |
| 2 |接受| 3.4183 | 0.039073 | 3.2818 | 3.2888 | 1 |
| 3 | Best | 3.1491 | 0.064001 | 3.1491 | 3.166 | 4 |
| 4 | Best | 2.9885 | 0.044758 | 2.9885 | 2.9885 | 9 |
| 5 |接受| 2.9978 | 0.062209 | 2.9885 | 2.9885 | 7 |
| 6 |接受| 3.0203 | 0.059873 | 2.9885 | 3.0013 | 8 |
| 7 |接受| 2.9885 | 0.038612 | 2.9885 | 2.9981 | 9 |
| 8 | Best | 2.9589 | 0.033799 | 2.9589 | 2.985 | 10 |
| 9 |接受| 3.0459 | 0.044544 | 2.9589 | 2.9895 | 12 |
| 10 |接受| 4.1881 | 0.047524 | 2.9589 | 2.9594 | 50 |
| 11 |接受| 3.4182 | 0.034722 | 2.9589 | 2.9594 | 2 |
| 12 |接受| 3.0376 | 0.034222 | 2.9589 | 2.9592 | 6 |
| 13 |接受| 3.1453 | 0.032823 | 2.9589 | 2.9856 | 19 |
| 14 |接受| 2.9589 | 0.033597 | 2.9589 | 2.9591 | 10 |
| 15 |接受| 2.9589 | 0.034081 | 2.9589 | 2.959 | 10 |
| 16 |接受| 2.9589 | 0.03319 | 2.9589 | 2.959 | 10 |
| 17 |接受| 3.3055 | 0.034701 | 2.9589 | 2.959 | 3 |
| 18 |接受| 3.4577 | 0.033698 | 2.9589 | 2.9589 | 37 |
| 19 |接受| 3.1584 | 0.033677 | 2.9589 | 2.9589 | 15 |
| 20 |接受| 3.107 | 0.034012 | 2.9589 | 2.9589 | 5 |
|======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 21日|接受| 3.0398 | 0.033158 | 2.9589 | 2.9589 | 23 |
| 22 |接受| 3.3226 | 0.036408 | 2.9589 | 2.9589 | 32 |
| 23 |接受| 3.1883 | 0.033603 | 2.9589 | 2.9589 | 17 |
| 24 |接受| 4.1881 | 0.03244 | 2.9589 | 2.9589 | 43 |
| 25 |接受| 3.0123 | 0.033589 | 2.9589 | 2.9589 | 11 |
| 26 |接受| 3.0932 | 0.042035 | 2.9589 | 2.9589 | 21 |
| 27 |接受| 3.078 | 0.033253 | 2.9589 | 2.9589 | 13 |
| 28 |接受| 3.2818 | 0.033183 | 2.9589 | 2.9589 | 25 |
| 29 |接受| 3.0992 | 0.033187 | 2.9589 | 2.9589 | 14 |
| 30 |接受| 3.4361 | 0.033507 | 2.9589 | 2.9589 | 34 |


__________________________________________________________ 优化完成。最大目标达到30个。总函数计算:30总运行时间:22.0354秒。总目标函数评估时间:1.2725最佳观测可行点:MinLeafSize ___________ 10观测目标函数值= 2.9589估计目标函数值= 2.9589估计函数评估时间= 0.033799最佳估计可行点(根据模型):MinLeafSize ___________ 10估计目标函数值= 2.9589估计函数评估时间= 0.039529
Mdl = RegressionTree ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' NumObservations: 94 HyperparameterOptimizationResults: [1×1 BayesianOptimization] Properties, Methods
无偏预测器重要性估计
加载carsmall数据集。考虑一个模型,该模型根据汽车的加速度、气缸数、发动机排量、马力、制造商、车型年份和重量来预测汽车的平均燃油经济性。考虑气缸,制造行业,Model_Year作为分类变量。
负载carsmall圆柱=分类(圆柱);Mfg = categorical(cellstr(Mfg));Model_Year = categorical(Model_Year);X =表(加速度,气缸,排量,马力,制造,...Model_Year、重量、MPG);
显示类别变量中表示的类别数量。
numCylinders = number (categories(Cylinders))
numCylinders = 3
numMfg = nummel(类别(Mfg))
numMfg = 28
numModelYear = nummel(类别(Model_Year))
numModelYear = 3
因为只有三个类别气缸而且Model_Year,标准CART,预测器拆分算法更倾向于在这两个变量上拆分一个连续预测器。
使用整个数据集训练回归树。要生长无偏树,请指定用于分割预测器的曲率测试。因为数据中有缺失的值,所以指定代理分割的使用。
Mdl = fitrtree(X,“英里”,“PredictorSelection”,“弯曲”,“代孕”,“上”);
通过将每个预测器上的分裂导致的风险变化相加并除以分支节点的数量来估计预测器的重要性值。用柱状图比较估算值。
imp = predictorImportance(Mdl);图;酒吧(imp);标题(“预测者重要性估计”);ylabel (“估计”);包含(“预测”);H = gca;h.XTickLabel = mld . predictornames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
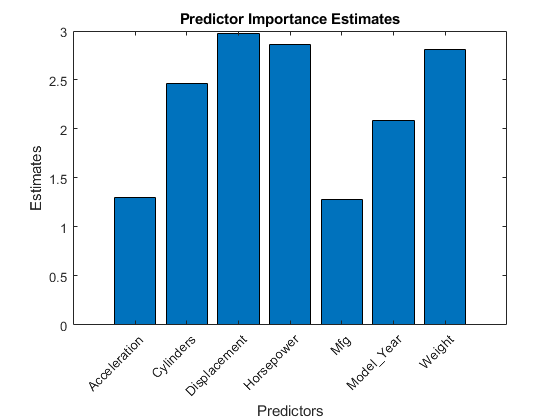
在这种情况下,位移是最重要的预测因素,其次是马力.
控制高阵列的最大树深度
fitrtree默认情况下生长深度决策树。建立一个较浅的树,需要更少的通过一个高数组。使用“MaxDepth”名称-值对参数来控制最大树深度。
在高数组上执行计算时,MATLAB®使用并行池(如果有并行计算工具箱™,则默认为并行池)或本地MATLAB会话。如果要在具有并行计算工具箱时使用本地MATLAB会话运行示例,可以使用mapreduce函数。
加载carsmall数据集。考虑位移,马力,重量作为反应的预测因素英里/加仑.
负载carsmallX =[排量马力重量];
转换内存中的数组X而且英里/加仑到高数组。
tx =高(X);
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数:6)。
ty = tall(MPG);
使用所有的观察数据建立一个回归树。让树生长到最大可能的深度。
为了重现性,使用设置随机数生成器的种子rng而且tallrng.根据工作人员的数量和tall数组的执行环境,结果可能有所不同。详细信息请参见控制代码运行的位置(MATLAB)。
rng (“默认”) tallrng (“默认”) Mdl = fitrtree(tx,ty);
评估高表达式使用并行池“当地”:——通过1 2:在3.3秒完成,通过2 2:在1秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:——通过1 6:在1.4秒完成,通过2 6:在0.41秒完成,通过3 6:在2.3秒完成,通过4 6:在3.6秒完成,通过5 6:在1.5秒完成,通过6 6:在2.9秒完成评估在14秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.45秒完成,通过2 7:在0.36秒完成,通过3 7:在1.2秒完成,通过4 7:在2.5秒完成,通过5 7:在0.85秒完成,通过6 7:在1.4秒完成,通过7 7:在2.2秒完成评估在10秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.45秒完成,通过2 7:在0.36秒完成,通过3 7:在1.1秒完成,通过4 7:在2.6秒完成,通过5 7:在1秒完成,通过6 7:在1.5秒完成,通过7 7:在3.2秒完成评估在12秒完成评估高表达使用并行池“当地”:——通过1 7:在0.43秒完成,通过2 7:在0.38秒完成,通过3 7:在1.6秒完成,通过4 7:在2.6秒完成,通过5 7:完成0.89秒-通过6 7:在1.2秒完成,通过7 7:在2.3秒完成评估在11秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.47秒完成,通过2 7:在0.38秒完成,通过3 7:在1.1秒完成,通过4 7:在2秒完成,通过5 7:在0.76秒完成,通过6 7:在1.2秒完成,通过7 7:在2.4秒完成评估在9.5秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.42秒完成,通过2 7:在0.33秒完成,通过3 7:在1.2秒完成,通过4 7:在2.2秒完成,通过5 7:在0.82秒完成,通过6 7:在1.3秒完成,通过7 7:在2.2秒完成评估在9.7秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.49秒完成,通过2 7:在0.36秒完成,通过3 7:在1.1秒完成,通过4 7:在2.8秒完成,通过5 7:在1.2秒完成,通过6 7:在1.1秒完成,通过7 7:在2.3秒完成评估在10秒完成评估高表达使用并行池“当地”:——通过1 7:在0.5秒完成,通过2 7:在0.34秒完成,通过3 7:在1.1秒完成,通过4 7:在1.8秒完成,通过5 7:在0.75秒内完成-通过7次中的第6次:在1.1秒内完成-通过7次中的第7次:在1.8秒内完成评估在8.5秒内完成
查看已训练的树Mdl.
视图(Mdl,“模式”,“图”)

Mdl树有深度吗8.
估计样本内均方误差。
MSE_Mdl =收集(丢失(Mdl,tx,ty))
使用并行池“本地”评估tall表达式:-通过1 / 1:在3.1秒内完成评估在3.7秒内完成
MSE_Mdl = 4.9078
使用所有的观察数据建立一个回归树。通过指定最大树深度来限制树深度4.
Mdl2 = fitrtree(tx,ty,“MaxDepth”4);
评估高表达式使用并行池“当地”:——通过1 2:在0.38秒完成,通过2 2:在0.35秒完成评估在1.2秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.42秒完成,通过2 7:在0.35秒完成,通过3 7:在1.2秒完成,通过4 7:在1.9秒完成,通过5 7:在0.73秒完成,通过6 7:在1.2秒完成,通过7 7:在2.1秒完成评估在8.9秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.44秒完成,通过2 7:在0.39秒完成,通过3 7:在1.1秒完成,通过4 7:在2.1秒完成,通过5 7:在0.74秒完成,通过6 7:在1.1秒完成,通过7 7:在2.7秒完成评估在9.7秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.46秒完成,通过2 7:在0.37秒完成,通过3 7:在1.1秒完成,通过4 7:在1.9秒完成,通过5 7:在0.79秒完成,通过6 7:在1.1秒完成,通过7 7:在2.3秒完成评估在9.1秒完成评估高表达使用并行池“当地”:——通过1 7:在0.43秒完成,通过2 7:在0.41秒完成,通过3 7:在1.1秒完成,通过4 7:在1.9秒完成,通过5 7:在0.72秒内完成-通过7次中的第6次:在1秒内完成-通过7次中的第7次:在2.2秒内完成评估在8.9秒内完成
查看已训练的树Mdl2.
视图(Mdl2,“模式”,“图”)

估计样本内均方误差。
MSE_Mdl2 =收集(丢失(Mdl2,tx,ty))
使用并行池“本地”评估tall表达式:-通过1 / 1:在0.86秒内完成评估,在1.3秒内完成
MSE_Mdl2 = 9.3903
Mdl2深度为4且样本内均方误差高于的均方误差的较不复杂的树吗Mdl.
优化高阵列上的回归树
使用高数组自动优化回归树的超参数。示例数据集是carsmall数据集。本示例将数据集转换为一个高数组,并使用它来运行优化过程。
在高数组上执行计算时,MATLAB®使用并行池(如果有并行计算工具箱™,则默认为并行池)或本地MATLAB会话。如果要在具有并行计算工具箱时使用本地MATLAB会话运行示例,可以使用mapreduce函数。
加载carsmall数据集。考虑位移,马力,重量作为反应的预测因素英里/加仑.
负载carsmallX =[排量马力重量];
转换内存中的数组X而且英里/加仑到高数组。
tx =高(X);ty = tall(MPG);
方法自动优化超参数“OptimizeHyperparameters”名称-值对参数。找到最优“MinLeafSize”使拒绝交叉验证损失最小化的值。(指定“汽车”使用“MinLeafSize”)。为了重现性,使用“expected-improvement-plus”采集函数和设置随机数的种子发生器使用rng而且tallrng.根据工作人员的数量和tall数组的执行环境,结果可能有所不同。详细信息请参见控制代码运行的位置(MATLAB)。
rng (“默认”) tallrng (“默认”) [Mdl,FitInfo,HyperparameterOptimizationResults] = fitrtree(tx,ty,...“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”结构(“坚持”, 0.3,...“AcquisitionFunctionName”,“expected-improvement-plus”))
使用并行池“本地”评估高表达式:-通过1:0%完成评估0%完成
-通过1对1:在1.1秒完成评估在1.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.72秒完成——通过2 4:在1.7秒完成,通过3 4:在2.7秒完成,通过4 4:在2.1秒完成评估在8.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.2秒完成,通过3 4:在2.4秒完成,通过4 4:在1.9秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.52秒完成,通过2 4:在1.2秒完成,通过3 4:在2.6秒完成,通过4 4:在2秒完成评估在7.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.3秒完成,通过3 4:在2.5秒完成,通过4 4:在1.8秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.2秒完成,通过3 4:在2.3秒完成,通过4 4:在1.7秒完成评估在6.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在2.2秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:通过1对1:在1秒完成评估在1.3秒完成 |======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 最好1 | | 3.2007 | 57.801 | 3.2007 | 3.2007 | 2 |
评估高表达式使用并行池“当地”:通过1对1:在0.47秒完成评估在0.77秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.3秒完成,通过3 4:在3.2秒完成,通过4 4:在2.1秒完成评估在7.8秒完成评估高表达式使用并行池“当地”:-通过1的1:完成在0.73秒评估完成在0.99秒| 2 |错误| NaN | 12.911 | NaN | 3.2007 | 46 |
评估高表达式使用并行池“当地”:通过1对1:在0.47秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在2.3秒完成,通过4 4:在2秒完成评估在6.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:完成1.3秒-通过3 4:在2.3秒完成,通过4 4:在1.8秒完成评估在6.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:在2.2秒完成,通过4 4:在1.9秒完成评估在6.5秒完成评估高表达式使用并行池“当地”:-通过1的1:0.68秒完成评估0.96秒完成| 3 |最佳| 3.1876 | 28.817 | 3.1876 | 3.1884 | 18 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在2秒内完成-通过4 / 4:在1.5秒内完成评估在5.9秒内完成评估使用并行池“本地”的高表达式:-通过1 / 1:在0.68秒内完成评估在0.94秒内完成| 4 |最佳| 2.9048 | 34.714 | 2.9048 | 2.9537 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.72秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.7秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:-通过1的1:0.66秒完成评估0.93秒完成| 5 |接受| 3.2895 | 27.092 | 2.9048 | 2.9048 | 15 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:完成1.2秒-通过3 4:在2.3秒完成,通过4 4:在2秒完成评估在6.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在2.1秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.6秒内完成评估在6秒内完成评估使用并行池“本地”:-通过1 / 1:在0.66秒内完成评估在0.93秒内完成| 6 |接受| 3.1641 | 36.435 | 2.9048 | 3.1493 | 5 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.4秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.1秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.6秒内完成评估在6.3秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.66秒内完成评估在0.93秒内完成| 7 |接受| 2.9048 | 35.665 | 2.9048 | 2.9048 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.75秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.3秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.52秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.3秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.7秒内完成评估在6.5秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.76秒内完成评估在1.1秒内完成| 8 |接受| 2.9522 | 35.826 | 2.9048 | 2.9048 | 7 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.54秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.6秒内完成评估在6.2秒内完成评估使用并行池“local”来评估高表达式:-通过1 / 1:在0.65秒内完成评估在0.93秒内完成| 9 |接受| 2.9985 | 35.62 | 2.9048 | 2.9048 | 8 |
评估高表达式使用并行池“当地”:通过1对1:在0.5秒完成评估在0.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:完成1.3秒-通过3 4:在2.4秒完成,通过4 4:在1.7秒完成评估在6.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.2秒内完成-通过4 / 4:在1.5秒内完成评估在6.1秒内完成评估使用并行池“local”来评估高表达式:-通过1 / 1:在0.78秒内完成评估在1.1秒内完成| 10 |接受| 3.0185 | 36.083 | 2.9048 | 2.9048 | 10 |
评估高表达式使用并行池“当地”:通过1对1:在0.53秒完成评估在0.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:完成1.1秒-通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.57秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:-通过1的1:0.72秒完成评估0.99秒完成| 11 |接受| 3.2895 | 27.296 | 2.9048 | 2.9048 | 14 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.75秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.2秒内完成-通过4 / 4:在1.6秒内完成评估在6.4秒内完成评估使用并行池“local”来评估高表达式:-通过1 / 1:在0.73秒内完成评估在1秒内完成| 12 |接受| 3.4798 | 19.544 | 2.9048 | 2.9049 | 31 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.7秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:完成1.1秒-通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.57秒完成,通过2 4:在1.4秒内完成-通过3 / 4:在2.4秒内完成-通过4 / 4:在1.6秒内完成评估在7秒内完成评估使用并行池“local”来评估高表达式:-通过1 / 1:在0.81秒内完成评估在1.1秒内完成| 13 |接受| 3.2248 | 51.715 | 2.9048 | 2.9048 | 1 |
评估高表达式使用并行池“当地”:通过1对1:在0.73秒完成评估在1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.57秒完成,通过2 4:在1.3秒完成,通过3 4:在2.2秒完成,通过4 4:在1.6秒完成评估在6.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:完成1.2秒-通过3 4:在2.2秒完成,通过4 4:在1.6秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.52秒完成,通过2 4:在1.3秒完成,通过3 4:完成2秒-通过4 4:在2.2秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:-通过1的1:0.66秒完成评估0.92秒完成| 14 |接受| 3.1498 | 44.861 | 2.9048 | 2.9048 | 3 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.52秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.53秒完成,通过2 4:完成1.3秒-通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.57秒完成,通过2 4:在1.3秒完成,通过3 4:在2.3秒完成,通过4 4:在2.1秒完成评估在7.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.3秒内完成-通过3 / 4:在2.2秒内完成-通过4 / 4:在1.6秒内完成评估在6.5秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.68秒内完成评估在0.95秒内完成| 15 |接受| 2.9048 | 36.927 | 2.9048 | 2.9048 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.1秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:完成1.1秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.7秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.2秒内完成-通过4 / 4:在1.6秒内完成评估在6.3秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.67秒内完成评估在0.94秒内完成| 16 |接受| 2.9048 | 35.562 | 2.9048 | 2.9048 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.75秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2秒内完成-通过4 / 4:在1.6秒内完成评估在6秒内完成评估使用并行池“本地”来评估高表达式:-通过1 / 1:在0.66秒内完成评估在0.93秒内完成| 17 |接受| 3.1847 | 18.834 | 2.9048 | 2.9048 | 23 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.2秒完成,通过3 4:在2.2秒完成,通过4 4:在1.6秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.3秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.7秒内完成评估在6.3秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.7秒内完成评估在0.97秒内完成| 18 |接受| 3.1817 | 35.269 | 2.9048 | 2.9048 | 4 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.3秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:-通过1的1:完成在0.66秒评估完成在0.92秒| 19 |错误| NaN | 11.194 | 2.9048 | 2.9048 | 38 |
评估高表达式使用并行池“当地”:通过1对1:在0.47秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.5秒内完成评估在6.1秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.68秒内完成评估在0.95秒内完成| 20 |接受| 3.0628 | 34.846 | 2.9048 | 2.9048 | 12 |
评估高表达式使用并行池“当地”:通过1对1:在0.54秒完成评估在0.86秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.4秒完成,通过3 4:在2.1秒完成,通过4 4:在1.5秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.5秒内完成-通过3 / 4:在2.7秒内完成-通过4 / 4:在1.7秒内完成评估在7.1秒内完成评估使用并行池“本地”:-通过1 / 1:在0.65秒内完成评估在0.91秒内完成|======================================================================================| | Iter | Eval |目标:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 21日|接受| 3.1847 | 20.6 | 2.9048 | 2.9048 | | 27岁
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.53秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:在2.2秒完成,通过4 4:在1.5秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在2秒内完成-通过4 / 4:在1.7秒内完成评估在6.1秒内完成评估使用并行池“local”的高表达式:-通过1 / 1:在0.68秒内完成评估在0.96秒内完成| 22 |接受| 3.0185 | 35.551 | 2.9048 | 2.9048 | 9 |
评估高表达式使用并行池“当地”:通过1对1:在0.53秒完成评估在0.83秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在2.1秒完成,通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.52秒完成,通过2 4:在1.3秒完成,通过3 4:在2.1秒完成,通过4 4:在1.5秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.69秒完成评估在0.96秒完成| 23 |接受| 3.0749 | 27.387 | 2.9048 | 2.9048 | 20 |
评估高表达式使用并行池“当地”:通过1对1:在0.51秒完成评估在0.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.2秒完成,通过3 4:在2.2秒完成,通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.3秒完成,通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒内完成-通过4中的3:在2.1秒内完成-通过4中的4:在1.6秒内完成评估在6.1秒内完成评估使用并行池“local”来评估高表达式:-通过1中的1:在0.64秒内完成评估在0.91秒内完成| 24 |接受| 3.0628 | 35.456 | 2.9048 | 2.9048 | 11 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:-通过1的1:完成耗时0.66秒评估耗时0.93秒| 25 |错误| NaN | 10.961 | 2.9048 | 2.9048 | 34 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:在2.2秒完成,通过4 4:在1.7秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.53秒完成,通过2 4:在1.4秒内完成-通过3 / 4:在2.2秒内完成-通过4 / 4:在1.6秒内完成评估在6.5秒内完成评估使用并行池“local”来评估高表达式:-通过1 / 1:在0.75秒内完成评估在1秒内完成| 26 |接受| 3.1847 | 19.822 | 2.9048 | 2.9048 | 25 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:完成1.2秒-通过3 4:在2.1秒完成,通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:-通过1的1:0.66秒完成评估0.92秒完成| 27 |接受| 3.2895 | 26.734 | 2.9048 | 2.9048 | 16 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在2.1秒完成,通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:完成1.3秒-通过3 4:在2.2秒完成,通过4 4:在1.7秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:-通过1的1:0.65秒完成评估0.92秒完成| 28 |接受| 3.2135 | 27.121 | 2.9048 | 2.9048 | 13 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2秒内完成-通过4 / 4:在1.5秒内完成评估在6秒内完成评估使用并行池“本地”:-通过1 / 1:在0.65秒内完成评估在0.91秒内完成| 29 |接受| 3.1847 | 18.825 | 2.9048 | 2.9048 | 21 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.75秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.2秒内完成-通过3 / 4:在2.1秒内完成-通过4 / 4:在1.6秒内完成评估在6.1秒内完成评估使用并行池“local”来评估高表达式:-通过1 / 1:在0.66秒内完成评估在0.93秒内完成| 30 |接受| 3.1827 | 19.18 | 2.9048 | 2.9122 | 29 |


__________________________________________________________ 优化完成。最大目标达到30个。总函数计算:30总运行时间:921.4644秒。总目标函数评估时间:898.6512最佳观测可行点:MinLeafSize ___________ 6观测目标函数值= 2.9048估计目标函数值= 2.9122函数评估时间= 34.7142最佳估计可行点(根据模型):MinLeafSize ___________ 6估计目标函数值= 2.9122估计函数评估时间= 35.77使用并行池“本地”评估高表达式:-通过1 / 2:完成0.25秒-通过2 2:在0.26秒完成评估在0.8秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.29秒完成,通过2 7:在0.25秒完成,通过3 7:在0.82秒完成,通过4 7:在1.5秒完成,通过5 7:在0.52秒完成,通过6 7:在0.82秒完成,通过7 7:在1.5秒完成评估在6.4秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.28秒完成,通过2 7:在0.25秒完成,通过3 7:在0.76秒完成,通过4 7:在1.4秒完成,通过5 7:在0.48秒完成,通过6 7:在0.77秒完成,通过7 7:在1.4秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.3秒完成,通过2 7:在0.27秒完成,通过3 7:在0.8秒完成,通过4 7:在1.4秒完成,通过5 7:在0.52秒完成,通过6 7:在0.75秒完成,通过7 7:在1.5秒完成评估在6.3秒完成评估高表达使用并行池“当地”:——通过1 7:在0.3秒完成,通过2 7:在0.25秒完成,通过3 7:在0.78秒完成,通过4 7:在1.4秒完成,通过5 7:在0.51秒完成,通过6 7:在0.94秒完成,通过7 7:在1.7秒完成评估在6.7秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.28秒完成,通过2 7:在0.26秒完成,通过3 7:在0.75秒完成,通过4 7:在1.4秒完成,通过5 7:在0.49秒完成,通过6 7:在0.78秒完成,通过7 7:在1.4秒完成评估在6.1秒完成
Mdl = classreg.learning.regr.CompactRegressionTree ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none'属性,方法
FitInfo =结构,不带字段。
HyperparameterOptimizationResults = BayesianOptimization with properties: ObjectiveFcn: @createObjFcn/tallObjFcn variabledescription: [3×1 optimizableVariable] Options: [1×1 struct] MinObjective: 2.9048 XAtMinObjective: [1×1 table] minestimatedobjobjective: 2.9122 xatminestimatedobjobjective: [1×1 table] numobjectiveevalues: 30 TotalElapsedTime: 921.4644 NextPoint: [1×1 table] XTrace: [30×1 table] ObjectiveTrace: [30×1 double] ConstraintsTrace: [] UserDataTrace:{30×1 cell} ObjectiveEvaluationTimeTrace: [30×1 double] IterationTimeTrace: [30×1 double] ErrorTrace: [30×1 double]可行性跟踪:[30×1 logical]可行性概率跟踪:[30×1 double] IndexOfMinimumTrace: [30×1 double] objectivminimumtrace: [30×1 double] estimatedobjectivminimumtrace: [30×1 double]
输入参数
输出参数
更多关于
提示
算法
参考文献
布莱曼,L.弗里德曼,R.奥尔申和C.斯通。分类与回归树.佛罗里达州博卡拉顿:CRC出版社,1984年。
[2] Loh, W.Y.,“无偏变量选择和交互检测的回归树”。Statistica中央研究院, Vol. 12, 2002, pp. 361-386。
[3]罗永安、施永信。分类树的分割选择方法Statistica中央研究院, Vol. 7, 1997, pp. 815-840。
扩展功能
在R2014a中引入
您也可以从以下列表中选择一个网站:
