oobPermutedPredictorImportance
通过禁止禁止造影的释放对回归树的随机森林的禁令预测重点估计
描述
偶尔= OobperMutedPredictorimportance(Mdl)Mdl。Mdlmust be a回归BaggedEnsemble模型对象。
Input Arguments
输出参数
例子
估计预测因子的重要性
加载Carsmall.数据集。考虑一种模型,该模型预测汽车的平均燃料经济性,仪式,气缸数量,发动机位移,马力,制造商,模型年和重量。考虑气瓶,MFG., andmodel_year.as categorical variables.
loadCarsmall.气瓶= categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg,......model_year,重量,mpg);
您可以使用整个数据集培训500个回归树的随机森林。
Mdl = fitrensemble(X,“英里”,'方法','袋','numlearnicalnycle',500);
fitrensemble使用默认模板树对象Templatetree()as a weak learner when'方法'is'袋'。在此示例中,为了再现性,请指定'可重复',真实创建树模板对象时,然后将对象用作弱的学习者。
RNG('默认')重复性的%t = templateTree('可重复',真正);% For reproducibiliy of random predictor selectionsMdl = fitrensemble(X,“英里”,'方法','袋','numlearnicalnycle',500,“学习者”,t);
Mdl是A.回归BaggedEnsemble模型。
通过禁用外袋观察来估算预测的重要措施。使用条形图比较估计值。
偶尔= OobperMutedPredictorimportance(Mdl); figure; bar(imp); title('不禁止允许的预测标志重要估计');ylabel('Estimates');xlabel('预测者');h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter ='none';

偶尔是一个1比7的预测重要性估计矢量。更大的值表示对预测产生更大影响的预测因子。在这种情况下,Weight是最重要的预测因素,其次是model_year.。
Unbiased Estimates of Predictor Importance Using Parallel Computing
加载Carsmall.数据集。考虑一种模型,该模型预测汽车的平均燃料经济性,仪式,气缸数量,发动机位移,马力,制造商,模型年和重量。考虑气瓶,MFG., andmodel_year.as categorical variables.
loadCarsmall.气瓶= categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg,......model_year,重量,mpg);
Display the number of categories represented in the categorical variables.
numCylinders = numel(categories(Cylinders))
numcylinders = 3
numMfg = numel(categories(Mfg))
numMfg = 28
nummodelyear = numel(类别(model_year))
numModelYear = 3
因为只有3个类别气瓶和model_year.,标准推车,预测算法更喜欢在这两个变量上分割连续的预测器。
使用整个数据集培训500个回归树的随机森林。为了种植无偏的树木,请指定用于分裂预测器的曲率测试的使用。由于数据中存在缺少值,因此指定代理分割的使用。要重现随机预测器选择,请使用随机数发生器的种子rng和specify'可重复',真实。
RNG('默认');重复性的%t = templateTree('PredictorSelection','curvature','代理','on',......'可重复',真正);随机预测器选择的再现性的%Mdl = fitrensemble(X,“英里”,'方法','袋','numlearnicalnycle',500,......“学习者”,t);
通过禁用外袋观察来估算预测的重要措施。并行执行计算。
选项= statset('UseParallel',真正);Imp = OobperMutedPredictorimportance(MDL,'选项',选择);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
使用条形图比较估计值。
figure; bar(imp); title('不禁止允许的预测标志重要估计');ylabel('Estimates');xlabel('预测者');h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter ='none';
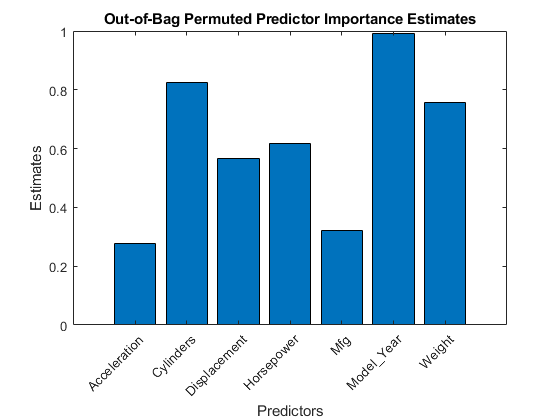
在这种情况下,model_year.是最重要的预测因素,其次是气瓶。将这些结果与结果进行比较估计预测因子的重要性。
More About
提示
在使用随机森林时使用fitrensemble:
Standard CART tends to select split predictors containing many distinct values, e.g., continuous variables, over those containing few distinct values, e.g., categorical variables[3]。如果预测器数据集是异构的,或者如果存在与其他变量相对较少的不同值的预测器,则考虑指定曲率或交互测试。
Trees grown using standard CART are not sensitive to predictor variable interactions. Also, such trees are less likely to identify important variables in the presence of many irrelevant predictors than the application of the interaction test. Therefore, to account for predictor interactions and identify importance variables in the presence of many irrelevant variables, specify the interaction test[2]。
如果培训数据包括许多预测因子并且您想要分析预测的重要性,则指定
'numvariablestosample'of theTemplatetree.功能'all'对于合奏的树学习者。否则,软件可能无法选择一些预测器,低估了他们的重要性。
有关更多详细信息,请参阅Templatetree.和选择分割预测器选择技术。
参考资料
[1] Breiman,L.,J.Friedman,R. Olshen和C. Stone。Classification and Regression Trees。Boca Raton, FL: CRC Press, 1984.
[2] LOH,W.Y.“具有无偏的变量选择和相互作用检测的回归树。”STATISTICA SINICA.,卷。12, 2002, pp. 361–386.
[3] Loh, W.Y. and Y.S. Shih. “Split Selection Methods for Classification Trees.”STATISTICA SINICA.,卷。7,1997,第815-840页。
扩展能力
See Also
You can also select a web site from the following list:
Americas
- América拉丁(Español)
- Canada(英语)
- United States(英语)
