预测
使用分类树预测标签
描述
输入参数
输出参数
例子
使用分类树预测标签
在培训之外的数据集中检查几行的预测。
装载Fisher的Iris数据集。
加载fisheriris
将数据划分为训练集(50%)和验证集(50%)。
1) n =大小(量;rng (1)重复性的%idxTrn = false (n, 1);idxTrn (randsample (n,圆(0.5 * n))) = true;%训练集合逻辑索引idxVal = idxTrn == false;%验证集合逻辑指数
使用训练集生成分类树。
Mdl = fitctree(量(idxTrn:),物种(idxTrn));
预测验证数据的标签。计算错误分类的观测数据。
标签=预测(Mdl量(idxVal:));标签(randsample(元素个数(标签),5))%显示几个预测标签
ans =.5x1细胞{'setosa'} {'setosa'} {'setosa'} {'virginica'} {'versicolor'}
nummisclass = sum(〜strcmp(标签,物种(Idxval)))))
numMisclass = 3
该软件错误分配了三种样本的观察。
使用分类树估算类后验概率
装载Fisher的Iris数据集。
加载fisheriris
将数据划分为训练集(50%)和验证集(50%)。
1) n =大小(量;rng (1)重复性的%idxTrn = false (n, 1);idxTrn (randsample (n,圆(0.5 * n))) = true;%训练集合逻辑索引idxVal = idxTrn == false;%验证集合逻辑指数
使用训练集生成一个分类树,然后查看它。
Mdl = fitctree(量(idxTrn:),物种(idxTrn));视图(Mdl,'模式'那“图”)

生成的树有四个级别。
使用将子树修剪到1和3级的子树估计测试集的后验概率。
[~,后]=预测(Mdl量(idxVal:)“子树”3 [1]);Mdl。ClassNames
ans =.3 x1细胞{'setosa'} {'versicolor'} {'virginica'}
后(randsample(大小(后,1),5),:,:),...%显示几个后部概率
ANS = ANS(:,:,
的元素后面是课后概率:
行对应于验证集中的观察。
中列出的类对应列
Mdl。ClassNames.页面对应于子树。
被修剪到级别1的子树比被修剪到级别3的子树(即根节点)更确定其预测。
更多关于
分数(树)
对于树木,
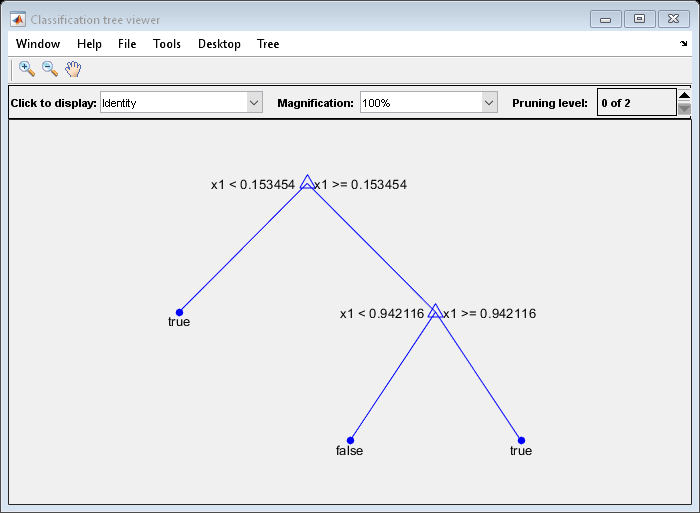
例如,考虑对预测器进行分类X作为真正的当X<0.15或X>0.95,X是假的。
生成100个随机点并对它们进行分类:
rng (0,'twister')重复性的%X =兰德(100 1);Y = (abs(X - 0.55) > .4);树= fitctree (X, Y);视图(树,'模式'那“图”)
修剪树:
tree1 =修剪(树,“水平”,1);查看(树1,'模式'那“图”)
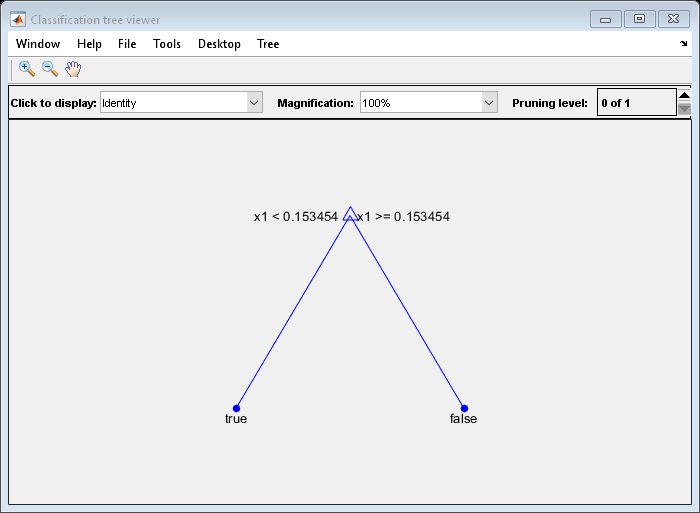
修剪后的树正确地将小于0.15的观测结果分类为真正的.它还正确地将观测值从。15到。94分类为错误的.然而,它错误地将大于。94的观测结果归类为错误的.因此,观察的分数大于.15的分数应为约0.05 /.85 = .06真正的,约为.8/.85=。94年错误的.
的前10行计算预测得分X:
[~,分数]=预测(tree1 X (1:10));(分数X (1:10)):
ans =.10×3.0.9059 0.0941 0.8147 0.9059 0.0941 0.9058 0 1.0000 0.1270 0.9059 0.0941 0.9134 0.9059 0.0941 0.6324 0 1.0000 0.0975 0.9059 0.0941 0.2785 0.9059 0.0941 0.5469 0.9059 0.0941 0.9575 0.9059 0.0941 0.9649
的确,每一种价值X(最右边的列)小于0.15的关联得分(左边和中间的列)0.和1,而另一个值X有相关的分数0.91和0.09.(得分的区别0.09而不是预期的06)是由于统计上的波动:有8.观察X范围内(.95,1)而不是预期的5.观察。
算法
预测的分支生成预测Mdl直到到达一个叶节点或缺失的值。如果预测到达一个叶节点,它返回该节点的分类。
如果预测到达具有预测器缺失值的节点,其行为取决于设置的代理名称 - 值对时fitctree结构体Mdl.
代理='离开'(默认)预测返回到达该节点的训练样本数量最大的标签。代理='上'-预测在节点上使用最佳代理分割。如果所有代理分割变量为正关联的预测测量人失踪, 预测返回到达该节点的训练样本数量最大的标签。有关定义,请参阅预测措施.
扩展功能
你也可以从以下列表中选择一个网站:
