失利
分类错误
句法
描述
大号=损失(树,TBL,ResponseVarName)树分类数据TBL, 什么时候TBL.ResponseVarName包含真正的分类。
当计算的损失,失利标准化在类概率ÿ以用于培训类的概率,存储在先财产树。
注意
失利回报SE和进一步输出只有当LossFun名称 - 值对是默认'classiferror'。
输入参数
输出参数
例子
计算在样品分类错误
计算为在resubstituted分类错误电离层数据集。
加载电离层树= fitctree(X,Y);L =损失(树,X,Y)
L = 0.0114
检查分类错误每个子树
未修剪决策树倾向于过度拟合。到平衡模型的复杂性和外的样本演奏的一种方法是修剪树(或限制其生长),使得样本内和外的样品性能是令人满意的。
加载费舍尔的虹膜数据集。将数据划分为训练(50%)和验证(50%)集。
加载fisheririsN =尺寸(MEAS,1);RNG(1)%用于重现idxTrn =假(N,1);idxTrn(randsample(N,圆形(0.5 * N)))= TRUE;%培训组逻辑指数idxVal = idxTrn == FALSE;%验证组逻辑指数
生成,使用训练集的分类树。
MDL = fitctree(MEAS(idxTrn,:),物种(idxTrn));
查看分类树。
视图(MDL,'模式','图形');
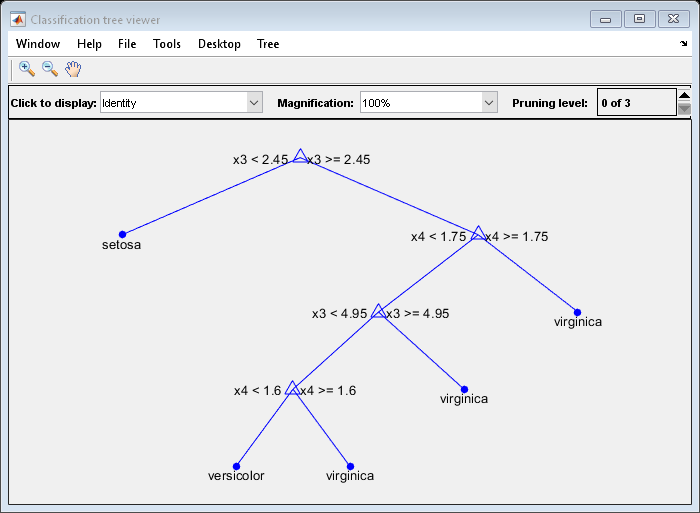
分类树有四个修剪水平。Level 0是满的,未修剪的树(如图显示)。级别3仅仅是根节点(即,没有裂痕)。
检查不包括最高级别的每个子树(或修剪电平)的训练样本分类误差。
M = MAX(Mdl.PruneList) - 1;trnLoss = resubLoss(MDL,“子树”,0:米)
trnLoss =3×10.0267 0.0533 0.3067
有关训练的观察2.7%的满,未修剪的树misclassifies。
树修剪水平1 misclassifies有关训练观察的5.3%。
树修剪到2级(即,残端)有关训练观测30.6%misclassifies。
检查每个级别不包括最高级别的验证样本分类错误。
valLoss =损失(MDL,MEAS(idxVal,:),物种(idxVal),“子树”,0:米)
valLoss =3×10.0369 0.0237 0.3067
有关验证观察的3.7%的满,未修剪的树misclassifies。
树修剪水平1 misclassifies有关验证意见的2.4%。
树修剪到2级(即,残端)有关验证观测30.7%misclassifies。
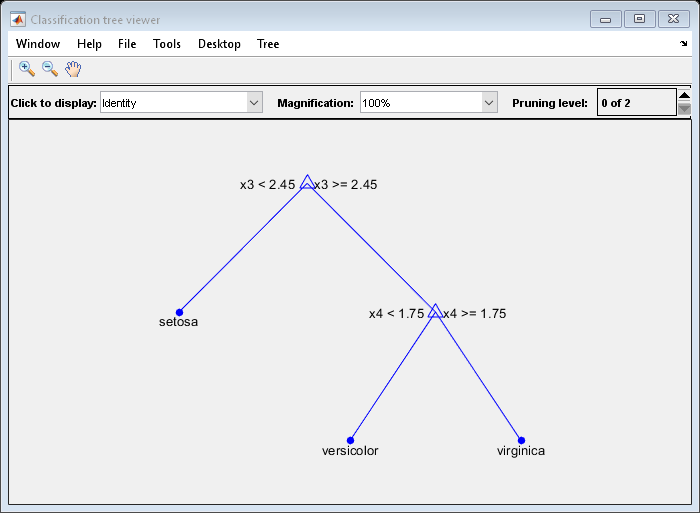
为了平衡模型的复杂性和外的样品性能,可以考虑修剪MDL比1平。
pruneMdl =剪枝(MDL,'水平',1);视图(pruneMdl,'模式','图形')
更多关于
分类损失
分类损失测量功能分类模型的预测不准确。当你比较同类型的众多车型中的损失,更低的损耗表示更好的预测模型。
请考虑以下情形。
大号是加权平均分类损失。
ñ是样本大小。
对于二元分类:
ÿĴ是所观察到的类的标签。软件代码作为-1或1,分别表示负的或正的类。
F(<Ë米Class="varname">XĴ)是原始分类评分观察(行)<Ë米Class="varname">Ĵ预测数据<Ë米Class="varname">X。
米Ĵ=<Ë米Class="varname">ÿĴF(<Ë米Class="varname">XĴ)是分类评分观察分类<Ë米Class="varname">Ĵ成对应于类<Ë米Class="varname">ÿĴ。为正值<Ë米Class="varname">米Ĵ表明正确分类,也没有太多的平均损失作出贡献。的负值<Ë米Class="varname">米Ĵ表明不正确的分类和平均损失显著贡献。
对于算法,支持多类分类(即,万博1manbetx<Ë米Class="varname">ķ≥3):
ÿĴ*是的向量<Ë米Class="varname">ķ- 1个零,1中的位置对应于所述真实的,观察到的类<Ë米Class="varname">ÿĴ。举例来说,如果真类的第二观察是第三类和<Ë米Class="varname">ķ= 4,然后<Ë米Class="varname">ÿ*2= [0 0 1 0]'。类的顺序对应于订单
类名输入模型的属性。F(<Ë米Class="varname">XĴ)是长度<Ë米Class="varname">ķ级得分进行观察的矢量<Ë米Class="varname">Ĵ预测数据<Ë米Class="varname">X。分数的顺序对应于类的顺序
类名输入模型的属性。米Ĵ=<Ë米Class="varname">ÿĴ*“<Ë米Class="varname">F(<Ë米Class="varname">XĴ)。因此,<Ë米Class="varname">米Ĵ是标分类评分模型预测为真,观察到的类。
观察权重<Ë米Class="varname">Ĵ是<Ë米Class="varname">w ^Ĵ。让他们总结到相应的现有类概率软件标准化观察权重。该软件还规范了先验概率,使他们和为1。因此,
鉴于这种情况下,下表描述了支持的损失的功能,你可以通过使用指定万博1manbetx'LossFun'名称 - 值对的参数。
| 损失函数 | 的价值LossFun |
方程 |
|---|---|---|
| 二项式越轨 | 'binodeviance' |
|
| 指数损失 | “指数” |
|
| 分类错误 | 'classiferror' |
它是错误分类的观察,其中的加权分数 是对应于具有最大后验概率的类的类的标签。<Ë米Class="varname">一世{<Ë米Class="varname">X}是指示符函数。 |
| 铰链损失 | '合页' |
|
| Logit模型损失 | 'Logit模型' |
|
| 最低的成本 | 'mincost' |
最小成本。该软件计算使用此过程的观测加权最小代价<Ë米Class="varname">Ĵ= 1,...,<Ë米Class="varname">ñ。
加权平均,最小成本损失是
|
| 二次损失 | “二次” |
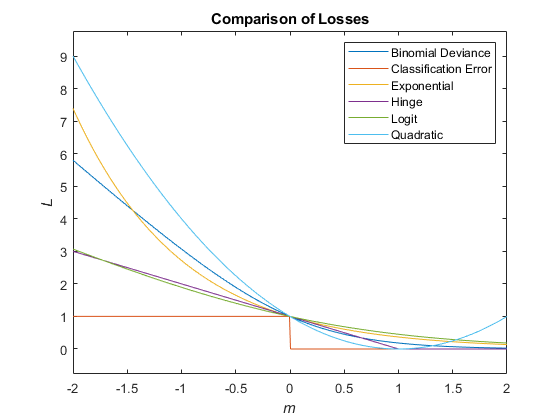
该图比较了损失功能(除了'mincost')为一个以上的观察<Ë米Class="varname">米。一些功能被归一化到穿过[0,1]。
得分(树)
对于绿树成荫,<Ë米Class="firstterm">得分叶节点的分类的是在该节点分类的后验概率。在节点分类的后验概率是训练序列的数目铅与分类该节点,通过训练序列的铅的数量,以该节点划分。
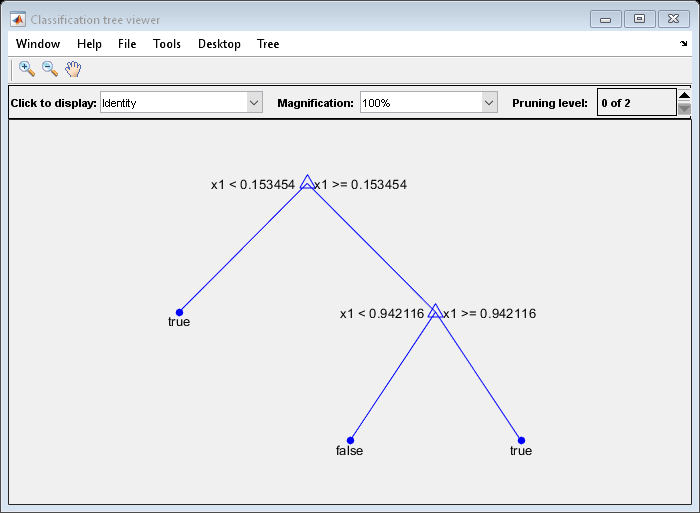
例如,考虑分类的预测X如真正什么时候X<0.15要么X>0.95和X是假的,否则。
生成100个随机点,它们归类:
RNG(0,“扭腰”)%,持续重现X =兰特(100,1);Y =(ABS(X - 0.55)> 0.4);树= fitctree(X,Y);视图(树,'模式','图形')
修剪树:
树1 =剪枝(树,'水平',1);视图(树1,'模式','图形')
该修剪树正确分类是小于0.15的意见真正。它还正确分类,从0.15到0.94的意见假。但是,它错误地归类是大于0.94的意见假。因此,该分数是大于0.15应为约0.05 / 0.85 = 0.06的观测真正和约0.8 / 0.85 = 0.94对假。
计算预测得分前10行的X:
[〜,得分=预测(树1,X(1:10));[得分X(1:10,:)]
ANS =10×30.9059 0.0941 0.8147 0.9059 0.0941 0.9058 1.0000 0 0.1270 0.9059 0.0941 0.9134 0.9059 0.0941 0.6324 1.0000 0 0.0975 0.9059 0.0941 0.2785 0.9059 0.0941 0.5469 0.9059 0.0941 0.9575 0.9059 0.0941 0.9649
事实上,每一个值X(最右列),其小于0.15具有相关联的得分(左边和中间列)0和1,而其它值X有相关的分数0.91和0.09。所不同的(得分0.09而不是预期的0.06)是由于统计波动:有8在观察X在范围内(.95,1)而不是预期的五观察结果。
扩展功能
您还可以选择从下面的列表中的网站:
