ClassificationTree类
二进制决策树多类分类
描述
一个ClassificationTree对象表示与分类二元分割决策树。这个类的一个对象可以预测使用新的数据响应预测方法。该对象包含用于训练的数据,所以它也可以计算resubstitution预测。
施工
创建一个ClassificationTree通过使用对象fitctree。
属性
|
宾边缘为数字预测,指定为的单元阵列p数值向量,其中p是预测的数目。每个向量包括用于数字预测的bin边缘。因为该软件不斌分类预测单元阵列的分类预测中的元素是空的。 该软件只装仓如果指定的数值预测 您可以复制离散化的预测数据 X = mdl.X;%预测数据Xbinned =零(大小(X));边缘= mdl.BinEdges;%查找分级预测的指标。idxNumeric =找到(〜cellfun(@的isEmpty,边缘));如果iscolumn(idxNumeric)idxNumeric = idxNumeric';结束对于j = idxNumeric X = X(:,J);%x转换为数组,如果x是一个表。如果istable(X)X = table2array(X);端%基团X到箱中,通过使用
Xbinned包含二进制位索引,取值范围为1到箱柜的数目,对于数值预测因子。Xbinned值分类预测是0。如果X包含为NaNs,则相应Xbinned值为NaN秒。 |
|
分类预测指标,指定为正整数的向量。 |
|
一个ñ-by-2细胞阵列,其中ñ是分类拆分的在数 |
|
一个ñ含有子节点的号码中的每个节点-by-2阵列 |
|
一个ñ-通过-ķ类计数的数组中的节点 |
|
在元素列表 |
|
一个ñ-通过-ķ类概率的数组中的节点 |
|
方阵,其中, |
|
一个ñ-by-2的类别的单元阵列用于在分支
|
|
一个ñ在用作切点的值的矢量 - 元素
|
|
一个ñ- 元素单元阵列指示在每个节点切割类型
|
|
一个ñ变量的名称 - 元素单元阵列用于在每个节点的分支
|
|
一个ñ为变量数字索引的阵列 - 元素用于在每个节点的分支 |
|
扩展预测器的名称,存储作为字符向量的单元阵列。 如果编码分类变量,那么该模型的用途 |
|
超参数的交叉验证优化的说明中,存储为
|
|
一个ñ- 元素逻辑载体,其是 |
|
在训练中使用的参数 |
|
观察在训练数据数量,数字标。 |
|
一个ñ与最可能的类的名称 - 元素单元阵列中的每个节点 |
|
一个ñ节点中的错误 - 元素矢量 |
|
一个ñ节点中的概率的矢量 - 元素 |
|
一个ñ节点的树,其中的风险 - 元素矢量ñ是节点的数量。每个节点的风险是该节点通过节点概率加权杂质(基尼系数或偏离)的度量。如果树是由两分成长,对每个节点的风险为零。 |
|
一个ñ的节点中的尺寸的 - 元素矢量 |
|
节点的数量 |
|
一个ñ含父节点的数目中的每个节点 - 元素矢量 |
|
包含预测器的名称,在该命令字符向量的单元阵列它们出现在 |
|
用于每个类别的先验概率的数值向量。的元素的顺序 |
|
数值向量与每修剪水平一种元素。如果修剪水平范围从0到中号, 然后 |
|
一个ñ具有在每个节点中的修剪水平 - 元素数值向量 |
|
指定响应变量的名称(A字符向量 |
|
一个ñ指示 - 元素逻辑矢量其中原始预测数据的行( |
|
用于转化预测分类评分,或字符向量表示功能句柄内置变换函数。
要更改分数转换功能,例如,
|
|
一个ñ类别 - 元素单元阵列用于替代分裂 |
|
一个ñ数字切分配 - 元素单元阵列用于替代分裂 |
|
一个ñ的数值组成 - 元素单元阵列用于替代分裂 |
|
一个ñ- 元素单元阵列指示在每个节点类型替代拆分的 |
|
一个ñ变量的名称 - 元素单元阵列中的每个节点用于替代拆分 |
|
一个ñ的关联的预测措施 - 元素单元阵列用于替代分裂 |
|
缩放 |
|
预测值的矩阵或表。的每一列 |
|
甲分类阵列,字符向量,字符数组,逻辑载体或数值向量的单元阵列。每行 |
方法
| 紧凑 | 紧凑树 |
| crossval | 交叉验证决策树 |
| cvloss | 通过交叉验证分类错误 |
| 修剪 | 通过修剪产生分级子树的序列 |
| resubEdge | 通过resubstitution分级刃 |
| resubLoss | 通过resubstitution分类错误 |
| resubMargin | 分类利润率由resubstitution |
| resubPredict | 预测分类树resubstitution标签 |
继承的方法
| 边缘 | 分级刃 |
| 失利 | 分类错误 |
| 余量 | 分类利润率 |
| 预测 | 预测使用分类树的标签 |
| predictorImportance | 预测的重要性估计分类树 |
| surrogateAssociation | 在分类树替代拆分协会的预测均值衡量 |
| 视图 | 查看分类树 |
复制语义
值。要了解值类如何影响复制操作,请参阅复制对象(MATLAB)。
例子
长分类树
使用长分类树电离层数据集。
加载电离层TC = fitctree(X,Y)
TC = ClassificationTree ResponseName: 'Y' CategoricalPredictors:[]类名:{ 'B' 的 'g'} ScoreTransform: '无' NumObservations:351的属性,方法
控制树的深度
您可以控制使用的树的深度MaxNumSplits,MinLeafSize, 要么MinParentSize名称 - 值对的参数。fitctree默认情况下,长深决策树。您可以种植树木较浅降低模型的复杂性和计算时间。
加载电离层数据集。
加载电离层
树的深度控制器,用于不断增长的分类树的默认值是:
N - 1对于MaxNumSplits。ñ是训练样本的大小。1对于MinLeafSize。10对于MinParentSize。
这些默认值倾向于增长深树木大量训练样本的大小。
使用默认值,树的深度控制训练的分类树。交叉验证使用模型10倍交叉验证。
RNG(1);%用于重现MdlDefault = fitctree(X,Y,'CrossVal','上');
画上的树木实行拆分的数量的直方图。另外,查看树木之一。
numBranches = @(x)的总和(x.IsBranch);mdlDefaultNumSplits = cellfun(numBranches,MdlDefault.Trained);数字;直方图(mdlDefaultNumSplits)

视图(MdlDefault.Trained {1},'模式','图形')
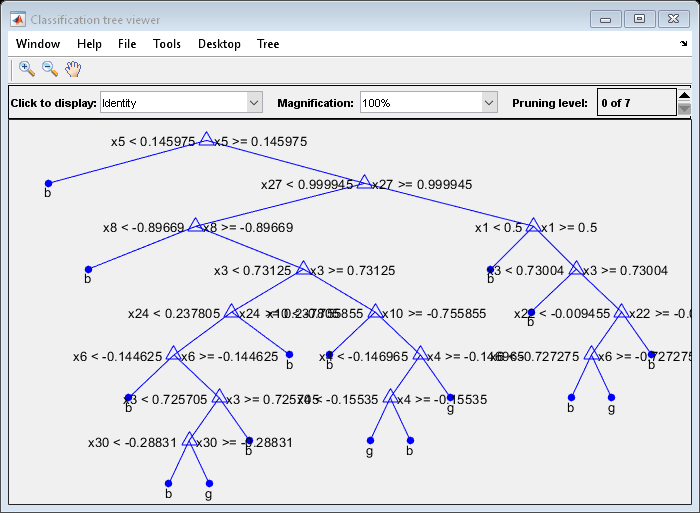
分裂的平均数量约为15。
假设你想要一个分类树,是不是那样复杂(深)为那些使用分裂的默认数量培训。火车另一分类树,而是设置拆分的7的最大数量,大约是从默认分类树分割一半的平均数。交叉验证使用模型10倍交叉验证。
Mdl7 = fitctree(X,Y,'MaxNumSplits',7,'CrossVal','上');视图(Mdl7.Trained {1},'模式','图形')

比较模型的交叉验证分类错误。
classErrorDefault = kfoldLoss(MdlDefault)
classErrorDefault = 0.1140
classError7 = kfoldLoss(Mdl7)
classError7 = 0.1254
Mdl7是执行更复杂,只比稍差MdlDefault。
更多关于
参考
[1] Breiman,L.,J。弗里德曼,R. Olshen,和C.石。分类和回归树。佛罗里达州Boca Raton:CRC出版社,1984年。
扩展功能
介绍了在R2011a
您还可以选择从下面的列表中的网站:
