预测GYdF4y2Ba
使用多类纠错输出码(ECOC)模型对观测进行分类GYdF4y2Ba
语法GYdF4y2Ba
描述GYdF4y2Ba
标签GYdF4y2Ba=预测(GYdF4y2BaMdlGYdF4y2Ba,GYdF4y2BaXGYdF4y2Ba)GYdF4y2Ba标签GYdF4y2Ba)用于表或矩阵中的预测数据GYdF4y2BaXGYdF4y2Ba,基于训练有素的多款误差校正输出代码(ECOC)模型GYdF4y2BaMdlGYdF4y2Ba.经过训练的ECOC模型可以是完整的,也可以是紧凑的。GYdF4y2Ba
标签GYdF4y2Ba=预测(GYdF4y2BaMdlGYdF4y2Ba,GYdF4y2BaXGYdF4y2Ba,GYdF4y2Ba名称、值GYdF4y2Ba)GYdF4y2Ba
[GYdF4y2Ba使用前面语法中的任何输入参数组合,并额外返回:GYdF4y2Ba标签GYdF4y2Ba,GYdF4y2BaNegLossGYdF4y2Ba,GYdF4y2BaPBSCore.GYdF4y2Ba]=预测(GYdF4y2Ba___GYdF4y2Ba)GYdF4y2Ba
一组负平均值GYdF4y2Ba二进制损失GYdF4y2Ba(GYdF4y2Ba
NegLossGYdF4y2Ba).对于每一个GYdF4y2BaXGYdF4y2Ba,GYdF4y2Ba预测GYdF4y2Ba指定产生最大负平均二进制损失(或,等价地,最小平均二进制损失)的类的标签。GYdF4y2Ba一系列积极级别的分数(GYdF4y2Ba
PBSCore.GYdF4y2Ba)对于每个二进制学习者分类的观察结果。GYdF4y2Ba
[GYdF4y2Ba另外,返回观测值的后验类别概率估计值(GYdF4y2Ba标签GYdF4y2Ba,GYdF4y2BaNegLossGYdF4y2Ba,GYdF4y2BaPBSCore.GYdF4y2Ba,GYdF4y2Ba后GYdF4y2Ba]=预测(GYdF4y2Ba___GYdF4y2Ba)GYdF4y2Ba后GYdF4y2Ba).GYdF4y2Ba
要获得后验类别概率,必须设置GYdF4y2Ba“是的,没错GYdF4y2Ba在培训ECOC模型时,使用GYdF4y2BafitcecocGYdF4y2Ba.否则,GYdF4y2Ba预测GYdF4y2Ba抛出一个错误。GYdF4y2Ba
例子GYdF4y2Ba
使用Ecoc模型预测培训数据的测试样本标签GYdF4y2Ba
载入费雪的虹膜数据集。指定预测器数据GYdF4y2BaXGYdF4y2Ba,响应数据GYdF4y2BaYGYdF4y2Ba,以及课程的顺序GYdF4y2BaYGYdF4y2Ba.GYdF4y2Ba
负载GYdF4y2Ba鱼腥草GYdF4y2BaX=meas;Y=categorical(物种);classOrder=unique(Y);rng (1);GYdF4y2Ba%为了再现性GYdF4y2Ba
使用支持向量机二分类器训练ECOC模型。指定30%的拒绝样本,使用SVM模板标准化预测器,并指定类顺序。GYdF4y2Ba
t=模板SVM(GYdF4y2Ba“标准化”GYdF4y2Ba,对);PMdl=fitcecoc(X,Y,GYdF4y2Ba'坚持'GYdF4y2Ba,0.30,GYdF4y2Ba“学习者”GYdF4y2BaTGYdF4y2Ba“类名”GYdF4y2Ba, classOrder);Mdl = PMdl.Trained {1};GYdF4y2Ba%抽取训练的紧凑分类器GYdF4y2Ba
PMdlGYdF4y2Ba是A.GYdF4y2Ba分类分区GYdF4y2Ba模型。它具有GYdF4y2Ba训练有素GYdF4y2Ba,一个1 × 1单元数组,其中包含GYdF4y2BaCompactClassificationECOCGYdF4y2Ba软件使用训练集进行训练的模型。GYdF4y2Ba
预测样品标签。打印真实标签和预测标签的随机子集。GYdF4y2Ba
testInds=测试(PMdl.Partition);GYdF4y2Ba%提取测试指标GYdF4y2BaXTest = X (testInds:);欧美= Y (testInds:);标签=预测(Mdl XTest);idx = randsample (sum (testInds), 10);表(欧美(idx),标签(idx),GYdF4y2Ba...GYdF4y2Ba“VariableNames”GYdF4y2Ba,{GYdF4y2Ba“TrueLabels”GYdF4y2Ba,GYdF4y2Ba“PredictedLabels”GYdF4y2Ba})GYdF4y2Ba
ans=GYdF4y2Ba10×2表GYdF4y2Ba真实标签预测标签__________ _______________ setosa setosa versicolor vericolor vericolor setosa setosa setosa setosa setosaGYdF4y2Ba
MdlGYdF4y2Ba使用索引正确标记除一个试样观察值外的所有观察值GYdF4y2Baidx.GYdF4y2Ba.GYdF4y2Ba
用自定义二元损耗函数预测ECOC模型的试样标签GYdF4y2Ba
载入费雪的虹膜数据集。指定预测器数据GYdF4y2BaXGYdF4y2Ba,响应数据GYdF4y2BaYGYdF4y2Ba,以及课程的顺序GYdF4y2BaYGYdF4y2Ba.GYdF4y2Ba
负载GYdF4y2Ba鱼腥草GYdF4y2BaX=meas;Y=categorical(物种);classOrder=unique(Y);GYdF4y2Ba%阶级秩序GYdF4y2Barng (1);GYdF4y2Ba%为了再现性GYdF4y2Ba
使用SVM二元分类器训练ECOC模型,并指定30%的保持样本。使用SVM模板标准化预测值,并指定类顺序。GYdF4y2Ba
t=模板SVM(GYdF4y2Ba“标准化”GYdF4y2Ba,对);PMdl=fitcecoc(X,Y,GYdF4y2Ba'坚持'GYdF4y2Ba,0.30,GYdF4y2Ba“学习者”GYdF4y2BaTGYdF4y2Ba“类名”GYdF4y2Ba, classOrder);Mdl = PMdl.Trained {1};GYdF4y2Ba%抽取训练的紧凑分类器GYdF4y2Ba
PMdlGYdF4y2Ba是A.GYdF4y2Ba分类分区GYdF4y2Ba模型。它具有GYdF4y2Ba训练有素GYdF4y2Ba,一个1 × 1单元数组,其中包含GYdF4y2BaCompactClassificationECOCGYdF4y2Ba软件使用训练集进行训练的模型。GYdF4y2Ba
支持向量机的分数被标记为从观测到决策边界的距离。因此,GYdF4y2Ba 域。创建一个自定义二进制损耗函数,执行以下操作:GYdF4y2Ba
映射编码设计矩阵(GYdF4y2BaMGYdF4y2Ba)和正向分类得分(GYdF4y2BasGYdF4y2Ba)对于每个学习者对每个观察的二进制损失。GYdF4y2Ba
使用线性的损失。GYdF4y2Ba
使用中位数汇总二元学习者损失。GYdF4y2Ba
您可以为二进制丢失功能创建一个单独的函数,然后将其保存在Matlab®路径上。或者,您可以指定匿名二进制丢失功能。在这种情况下,创建功能句柄(GYdF4y2BaCustomBl.GYdF4y2Ba)一个匿名二进制丢失函数。GYdF4y2Ba
CustomBl = @(m,s)纳米媒体(1 - bsxfun(@ times,m,s),2)/ 2;GYdF4y2Ba
预测测试样本标签并估计每个类的中位数二进制损失。为随机的10个测试样本观察结果打印每个类的负二进制损失的中位数。GYdF4y2Ba
testInds=测试(PMdl.Partition);GYdF4y2Ba%提取测试指标GYdF4y2BaXTest = X (testInds:);欧美= Y (testInds:);[标签,NegLoss] =预测(Mdl XTest,GYdF4y2Ba'二元乐'GYdF4y2Ba,海关;idx=随机样本(总和(测试数),10);类顺序GYdF4y2Ba
classOrder =GYdF4y2Ba3x1分类GYdF4y2Basetosa杂色的virginicaGYdF4y2Ba
表(欧美(idx),标签(idx) NegLoss (idx:)GYdF4y2Ba“VariableNames”GYdF4y2Ba,GYdF4y2Ba...GYdF4y2Ba{GYdF4y2Ba“TrueLabel”GYdF4y2Ba,GYdF4y2Ba“PredictedLabel”GYdF4y2Ba,GYdF4y2Ba“负损失”GYdF4y2Ba})GYdF4y2Ba
ans=GYdF4y2Ba10×3表GYdF4y2BaTrueLabel PredictedLabel NegLoss ________________________ __________________________________ setosa versicolor 0.18578 1.9878 -3.6736 versicolor virginica -1.3316 -0.12355 -0.044843 setosa versicolor 0.13896 1.926 -3.565 virginica -1.5132 -0.38271 0.39588 versicolor versicolor 0.87218 0.74736 -1.3752 setosa versicolor 0.48406 1.9977维珍-1.5788 -0.83318 0.91194 setosa versicolor 0.51021 2.1212 -4.1314 setosa versicolor 0.36128 2.0596 -3.9209GYdF4y2Ba
列的顺序对应于元素GYdF4y2BaclassOrderGYdF4y2Ba. 软件根据最大否定损失预测标签。结果表明,线性损失的中位数可能不如其他损失。GYdF4y2Ba
使用ECOC分类器估计后验概率GYdF4y2Ba
使用SVM二元学习器训练ECOC分类器。首先预测训练样本标签和类后验概率。然后预测网格中每个点的最大类后验概率。将结果可视化。GYdF4y2Ba
加载Fisher的虹膜数据集。指定花瓣尺寸作为预测值,指定物种名称作为响应。GYdF4y2Ba
负载GYdF4y2Ba鱼腥草GYdF4y2BaX=MEA(:,3:4);Y=物种;rng(1);GYdF4y2Ba%为了再现性GYdF4y2Ba
创建一个SVM模板。标准化预测值,并指定高斯核。GYdF4y2Ba
t=模板SVM(GYdF4y2Ba“标准化”GYdF4y2Ba,真的,GYdF4y2Ba“KernelFunction”GYdF4y2Ba,GYdF4y2Ba“高斯”GYdF4y2Ba);GYdF4y2Ba
TGYdF4y2Ba是一个SVM模板。它的大多数属性都是空的。当软件训练ECOC分类器时,它会将适用的属性设置为默认值。GYdF4y2Ba
使用SVM模板训练ECOC分类器。将分类分数转换为类后验概率(由GYdF4y2Ba预测GYdF4y2Ba或GYdF4y2Ba再预测GYdF4y2Ba)使用GYdF4y2Ba“菲特莱斯特”GYdF4y2Ba名称-值对参数。使用该规定类订单GYdF4y2Ba“类名”GYdF4y2Ba名称-值对参数。通过使用培训期间显示诊断消息GYdF4y2Ba'verbose'GYdF4y2Ba名称-值对参数。GYdF4y2Ba
Mdl = fitcecoc (X, Y,GYdF4y2Ba“学习者”GYdF4y2BaTGYdF4y2Ba“菲特莱斯特”GYdF4y2Ba,真的,GYdF4y2Ba...GYdF4y2Ba“类名”GYdF4y2Ba,{GYdF4y2Ba“塞托萨”GYdF4y2Ba,GYdF4y2Ba“多色的”GYdF4y2Ba,GYdF4y2Ba“维吉尼亚”GYdF4y2Ba},GYdF4y2Ba...GYdF4y2Ba'verbose'GYdF4y2Ba,2);GYdF4y2Ba
训练二元学习者1(SVM),从3个二元学习者中选出50个消极观察值和50个积极观察值。负类指数:2个正类指数:1个拟合学习者1的后验概率(SVM)。训练二元学习者2(SVM),其中3个有50个负面观察和50个正面观察。负类指数:3个正类指数:1为学习者2拟合后验概率(SVM)。训练二元学习者3(SVM),共有50个负面观察值和50个正面观察值。负类指数:3个正类指数:2个拟合学习者3的后验概率(SVM)。GYdF4y2Ba
MdlGYdF4y2Ba是A.GYdF4y2BaClassificationECOCGYdF4y2Ba模型相同的SVM模板适用于每个二进制学习器,但您可以通过传入模板的单元向量来调整每个二进制学习器的选项。GYdF4y2Ba
预测训练样本标签和类后验概率。在计算标签和类别后验概率期间,使用GYdF4y2Ba'verbose'GYdF4y2Ba名称-值对参数。GYdF4y2Ba
[标签,~,~,后]= resubPredict (Mdl,GYdF4y2Ba'verbose'GYdF4y2Ba1);GYdF4y2Ba
对所有学习者的预测都进行了计算。计算了所有观测的损失。计算后验概率…GYdF4y2Ba
Mdl。B我naryLoss
ans =“二次”GYdF4y2Ba
该软件将观察结果分配给产生最小平均二进制损失的班级。由于所有二进制学习器都在计算后验概率,因此二进制损失函数为GYdF4y2Ba二次的GYdF4y2Ba.GYdF4y2Ba
显示一组随机的结果。GYdF4y2Ba
idx = randsample(size(x,1),10,1);mdl.classnames.GYdF4y2Ba
ans=GYdF4y2Ba3 x1细胞GYdF4y2Ba{'setosa'} {'versicolor'} {'virginica'}GYdF4y2Ba
表(Y(idx),标签(idx),后部(idx,:),GYdF4y2Ba...GYdF4y2Ba“VariableNames”GYdF4y2Ba,{GYdF4y2Ba“TrueLabel”GYdF4y2Ba,GYdF4y2Ba“PredLabel”GYdF4y2Ba,GYdF4y2Ba“后部”GYdF4y2Ba})GYdF4y2Ba
ans=GYdF4y2Ba10×3表GYdF4y2Ba“UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU017065 0.018261 0.96467{'virginica'}{'virginica'}0.014946 0.015854 0.9692{'versicolor'}{'versicolor'}{'versicolor'}2.2197e-14 0.87318 0.12682{'setosa'}0.999 0.00025091 0.0007464{'versicolor'}{'virginica'}2.2195e-14 0.059423 0.94058{'versicolor'}{'versicolor'}2.2194e-14 0.97002 0.029983{'setosa'}{'setosa'}0.999 0.00024989 0.00074741{'versicolor'}{'versicolor'}0.0085637 0.98259 0.0088481{'setosa'{'setosa'}0.000710GYdF4y2Ba
的列GYdF4y2Ba后GYdF4y2Ba对应于的类序GYdF4y2Bamdl.classnames.GYdF4y2Ba.GYdF4y2Ba
在观测的预测器空间中定义一个网格值。预测网格中每个实例的后验概率。GYdF4y2Ba
xMax = max (X);xMin = min (X);x1Pts = linspace (xMin (1) xMax (1));xMax x2Pts = linspace (xMin (2), (2));[x1Grid, x2Grid] = meshgrid (x1Pts x2Pts);[~, ~, ~, PosteriorRegion] =预测(Mdl, [x1Grid (:), x2Grid (:)));GYdF4y2Ba
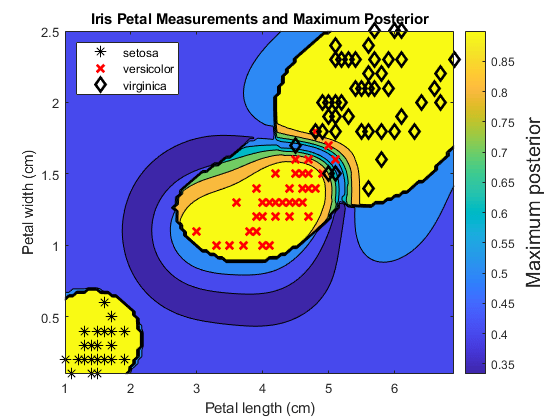
对于网格上的每个坐标,绘制所有类别中的最大类别后验概率。GYdF4y2Ba
contourf (x1Grid x2Grid,GYdF4y2Ba...GYdF4y2Ba重塑(Max(Postiorregion,[],2),尺寸(x1grid,1),尺寸(x1grid,2)));h =彩色杆;h.ylabel.string =.GYdF4y2Ba最大后验的GYdF4y2Ba; h、 YLabel.FontSize=15;持有GYdF4y2Ba在GYdF4y2Bagh=gscatter(X(:,1),X(:,2),Y,GYdF4y2Ba“krk”GYdF4y2Ba,GYdF4y2Ba“*xd”GYdF4y2Ba8);gh(2)。L我neWidth = 2; gh(3).LineWidth = 2; title(“虹膜瓣测量和最大后角”GYdF4y2Ba)包含(GYdF4y2Ba“花瓣长度(厘米)”GYdF4y2Ba) ylabel (GYdF4y2Ba“花瓣宽度(cm)”GYdF4y2Ba)轴GYdF4y2Ba牢固的GYdF4y2Ba传奇(gh,GYdF4y2Ba“位置”GYdF4y2Ba,GYdF4y2Ba“西北”GYdF4y2Ba)举行GYdF4y2Ba从GYdF4y2Ba
使用并行计算估计检验样本后验概率GYdF4y2Ba
训练一个多类ECOC模型,并使用并行计算估计后验概率。GYdF4y2Ba
加载GYdF4y2Ba心律失常GYdF4y2Ba数据集。检查响应数据GYdF4y2BaYGYdF4y2Ba,并确定类的数量。GYdF4y2Ba
负载GYdF4y2Ba心律失常GYdF4y2BaY =分类(Y);汇总(Y)GYdF4y2Ba
价值计数百分比124554.20%2449.73%3153.32%4153.32%5132.88%6255.53%730.66%820.44%991.99%1050111.06%1440.88%1551.11%16224.87%GYdF4y2Ba
K =元素个数(独特(Y));GYdF4y2Ba
在数据中没有表示几个类,并且许多其他类具有低相对频率。GYdF4y2Ba
指定使用VeandBoost方法和50个弱分类树学习者的集合学习模板。GYdF4y2Ba
t=模板集成(GYdF4y2Ba“绅士之声”GYdF4y2Ba, 50岁,GYdF4y2Ba'树'GYdF4y2Ba);GYdF4y2Ba
TGYdF4y2Ba是模板对象。它的大部分属性是空的(GYdF4y2Ba[]GYdF4y2Ba)。软件在培训期间对所有空属性使用默认值。GYdF4y2Ba
因为响应变量包含许多类,所以指定稀疏的随机编码设计。GYdF4y2Ba
rng (1);GYdF4y2Ba%为了再现性GYdF4y2Ba编码= designecoc (K,GYdF4y2Ba“斯巴瑟兰多姆”GYdF4y2Ba);GYdF4y2Ba
使用并行计算训练ECOC模型。指定15%的坚持样本,并拟合后验概率。GYdF4y2Ba
pool=parpool;GYdF4y2Ba%调用工人GYdF4y2Ba
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。GYdF4y2Ba
选项=statset(GYdF4y2Ba“UseParallel”GYdF4y2Ba,对);PMdl=fitcecoc(X,Y,GYdF4y2Ba“学习者”GYdF4y2BaTGYdF4y2Ba'选项'GYdF4y2Ba,选项,GYdF4y2Ba“编码”GYdF4y2Ba、编码、GYdF4y2Ba...GYdF4y2Ba“菲特莱斯特”GYdF4y2Ba,真的,GYdF4y2Ba'坚持'GYdF4y2Ba,0.15);Mdl = PMdl.Trained {1};GYdF4y2Ba%抽取训练的紧凑分类器GYdF4y2Ba
PMdlGYdF4y2Ba是A.GYdF4y2Ba分类分区GYdF4y2Ba模型。它具有GYdF4y2Ba训练有素GYdF4y2Ba,一个1 × 1单元数组,其中包含GYdF4y2BaCompactClassificationECOCGYdF4y2Ba软件使用训练集进行训练的模型。GYdF4y2Ba
该池调用六个工作线程,尽管工作线程的数量可能因系统而异。GYdF4y2Ba
估计后验概率,并显示被归类为不具有心律失常(1)的后验概率(给定随机测试样本观察的数据)。GYdF4y2Ba
testInds=测试(PMdl.Partition);GYdF4y2Ba%提取测试指标GYdF4y2BaXTest = X (testInds:);欧美= Y (testInds:);[~, ~, ~,后]=预测(Mdl XTest,GYdF4y2Ba'选项'GYdF4y2Ba、选择);idx = randsample (sum (testInds), 10);表(idx,欧美(idx)、后(idx, 1),GYdF4y2Ba...GYdF4y2Ba“VariableNames”GYdF4y2Ba,{GYdF4y2Ba“TestSampleIndex”GYdF4y2Ba,GYdF4y2Ba“TrueLabel”GYdF4y2Ba,GYdF4y2Ba“后心律失常”GYdF4y2Ba})GYdF4y2Ba
ans=GYdF4y2Ba10×3表GYdF4y2BaTestSampleIndex TrueLabel posteriorno心律失常_______________ _________ _____________________ 11 6 0.60631 41 4 0.23674 512 0.13802 33 10 0.43831 12 1 0.94332 8 1 0.97278 37 1 0.62807 24 10 0.96876 56 16 0.29375 30 1 0.64512GYdF4y2Ba
输入参数GYdF4y2Ba
输出参数GYdF4y2Ba
更多关于GYdF4y2Ba
算法GYdF4y2Ba
工具书类GYdF4y2Ba
[1] Allwein,E.,R.Schapire和Y.Singer,“将多类减少为二类:保证金分类的统一方法。”GYdF4y2Ba机器学习研究杂志GYdF4y2Ba.卷。1,2000,pp。113-141。GYdF4y2Ba
[2] Dieterich,T.和G.Bakiri。“通过纠错输出代码解决多类学习问题。”GYdF4y2Ba人工智能研究杂志GYdF4y2Ba.卷。2,1995,第263-286页。GYdF4y2Ba
Pujol, S. Escalera, S. O. Pujol, P. Radeva。《论三元纠错输出码的译码过程》。GYdF4y2Ba模式分析与机器智能学报GYdF4y2Ba.2010年第32卷第7期120-134页。GYdF4y2Ba
[4] Escalera,S.,O. Pujol和P. Radeva。“用于纠错输出代码稀疏设计的三元代码的可分离。”GYdF4y2Ba模式识别GYdF4y2Ba第30卷,2009年第3期,第285-297页。GYdF4y2Ba
[5] 黑斯蒂、T.和R.蒂布什拉尼。“按成对耦合进行分类。”GYdF4y2Ba统计年鉴GYdF4y2Ba.1998年第26卷第2期第451-471页。GYdF4y2Ba
[6] Wu,T. F.,C. J. Lin和R. Weng。“通过成对耦合对多级分类的概率估计。”GYdF4y2Ba机器学习研究杂志GYdF4y2Ba.卷。5,2004,PP。975-1005。GYdF4y2Ba
[7] 通过耦合概率估计将多类还原为二进制GYdF4y2BaNIPS 2001:神经信息处理系统进展会议录14GYdF4y2Ba,2001,pp。1041-1048。GYdF4y2Ba
扩展能力GYdF4y2Ba
另见GYdF4y2Ba
ClassificationECOCGYdF4y2Ba|GYdF4y2BaCompactClassificationECOCGYdF4y2Ba|GYdF4y2BafitcecocGYdF4y2Ba|GYdF4y2Ba损失GYdF4y2Ba|GYdF4y2BaquadprogGYdF4y2Ba|GYdF4y2Ba再预测GYdF4y2Ba|GYdF4y2Ba斯塔塞特GYdF4y2Ba
介绍了R2014bGYdF4y2Ba
选择网站GYdF4y2Ba
选择一个网站,以便在可用的地方进行翻译的内容,并查看本地活动和优惠。根据您的位置,我们建议您选择:GYdF4y2Ba.GYdF4y2Ba
选择GYdF4y2Ba网站GYdF4y2Ba你也可以从以下列表中选择一个网站:GYdF4y2Ba
美洲GYdF4y2Ba
- 拉丁美洲美洲GYdF4y2Ba(西班牙语)GYdF4y2Ba
- 加拿大GYdF4y2Ba(英文)GYdF4y2Ba
- 美国GYdF4y2Ba(英文)GYdF4y2Ba
欧洲GYdF4y2Ba
- 比利时GYdF4y2Ba(英文)GYdF4y2Ba
- 丹麦GYdF4y2Ba(英文)GYdF4y2Ba
- 德国GYdF4y2Ba(德语)GYdF4y2Ba
- 埃斯帕尼亚GYdF4y2Ba(西班牙语)GYdF4y2Ba
- 芬兰GYdF4y2Ba(英文)GYdF4y2Ba
- 法国GYdF4y2Ba(法语)GYdF4y2Ba
- 爱尔兰GYdF4y2Ba(英文)GYdF4y2Ba
- 意大利GYdF4y2Ba(意大利语)GYdF4y2Ba
- 卢森堡GYdF4y2Ba(英文)GYdF4y2Ba
- 荷兰GYdF4y2Ba(英文)GYdF4y2Ba
- 挪威GYdF4y2Ba(英文)GYdF4y2Ba
- ÖsterreichGYdF4y2Ba(德语)GYdF4y2Ba
- 葡萄牙GYdF4y2Ba(英文)GYdF4y2Ba
- 瑞典GYdF4y2Ba(英文)GYdF4y2Ba
- 瑞士GYdF4y2Ba
- 大不列颠联合王国GYdF4y2Ba(英文)GYdF4y2Ba
亚太地区GYdF4y2Ba
- 澳大利亚GYdF4y2Ba(英文)GYdF4y2Ba
- 印度GYdF4y2Ba(英文)GYdF4y2Ba
- 新西兰GYdF4y2Ba(英文)GYdF4y2Ba
- 中国人GYdF4y2Ba
- 日本GYdF4y2Ba(日本语)GYdF4y2Ba
- 한국GYdF4y2Ba(한국어)GYdF4y2Ba
