预测
预测标签线性分类模型
描述
输入参数
输出参数
例子
预计培训,样品标签
加载NLP的数据集。
加载nlpdata
X是预测数据的稀疏矩阵,并且ÿ是类别标签的分类矢量。有超过两个班中的数据。
该模型应标识在网页中的字数是否来自统计和机器学习工具箱™文档。因此,识别标签对应于统计和机器学习工具箱™文档网页。
Ystats = Y ==“统计”;
使用整个数据集,可识别的文档网页中的字数是否来自统计和机器学习工具箱™文档训练二元线性分类模型。
RNG(1);%用于重现MDL = fitclinear(X,Ystats);
MDL是ClassificationLinear模型。
预测训练样本,或resubstitution,标签。
标记=预测(MDL,X);
因为在一个正则强MDL,标签与长度是列向量等于观测值的数目。
构造一个混淆矩阵。
ConfusionTrain = confusionchart(Ystats,标签);

该模型misclassifies只有一个“统计”文档页面为统计和机器学习工具箱文档之外。
预测试验样品标签
加载NLP数据集和它进行预处理,如预计培训,样品标签。移调预测数据矩阵。
加载nlpdataYstats = Y ==“统计”;X = X';
培养出二元线性分类模型,它可以识别在文档网页中的字数是否来自统计和机器学习工具箱™文档。指定要持币观察的30%。优化利用SpaRSA目标函数。
RNG(1)%用于重现CVMdl = fitclinear(X,Ystats,“求解”,'sparsa','坚持',0.30,...'ObservationsIn','列');MDL = CVMdl.Trained {1};
CVMdl是ClassificationPartitionedLinear模型。它包含属性熟练,这是一个1×1单元阵列保持ClassificationLinear模型,使用软件中的训练集训练。
提取分区定义的训练和测试数据。
trainIdx =训练(CVMdl.Partition);testIdx =试验(CVMdl.Partition);
预测训练 - 和测试样品标签。
labelTrain =预测(MDL,X(:,trainIdx),'ObservationsIn','列');labelTest =预测(MDL,X(:,testIdx),'ObservationsIn','列');
因为在一个正则强MDL,labelTrain和labelTest与长度列向量分别等于训练和测试的观测数量,。
构建用于训练数据的混淆矩阵。
ConfusionTrain = confusionchart(Ystats(trainIdx),labelTrain);

该模型misclassifies只有三个文档页面为统计和机器学习工具箱文档之外。
构建用于测试数据的混淆矩阵。
ConfusionTest = confusionchart(Ystats(testIdx),labelTest);
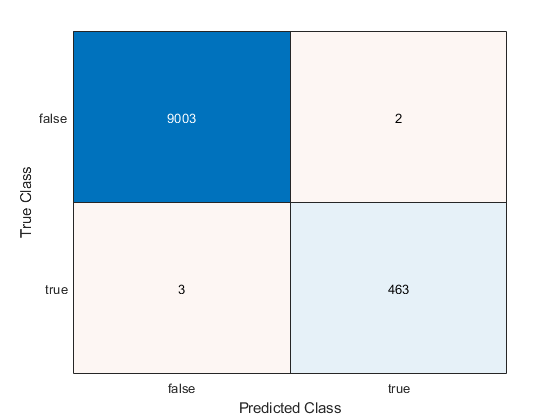
该模型misclassifies 3个文档页面为统计和机器学习工具箱外,和两页为内部。
估计后验概率类
估计测试样品,后级的概率,和通过绘制ROC曲线确定模型的质量。线性分类模型返回只有回归学习者的后验概率。
加载NLP数据集和它进行预处理,如预测试验样品标签。
加载nlpdataYstats = Y ==“统计”;X = X';
随机指定30%的保留样本将数据划分为训练集和测试集。识别测试设定指标。
CVP = cvpartition(Ystats,'坚持',0.30);idxTest =试验(CVP);
培养出二元线性分类模型。飞度回归学习者使用SpaRSA。持币观望的测试集,指定分区模型。
CVMdl = fitclinear(X,Ystats,'ObservationsIn','列','CVPartition',CVP,...'学习者',“物流”,“求解”,'sparsa');MDL = CVMdl.Trained {1};
MDL是ClassificationLinear模型中使用的分区指定的训练集训练的CVP只要。
预测测试样品后验概率类。
[〜,后] =预测(MDL,X(:,idxTest),'ObservationsIn','列');
因为在一个正则强MDL,后是具有2列的矩阵和行等于测试设定观测值的数目。柱一世包含的后验概率Mdl.ClassNames(I)给定一个特定的观察。
获取虚假和真实的阳性率,并估计AUC。指定第二类是积极类。
[FPR,TPR,〜,AUC] = perfcurve(Ystats(idxTest),后(:,2),Mdl.ClassNames(2));AUC
AUC = 0.9986
该AUC是1,这表明预测以及模型。
绘制ROC曲线。
数字;情节(FPR,TPR)H = GCA;h.XLim(1)= -0.1;h.YLim(2)= 1.1;xlabel(“假阳性率”)ylabel(“真阳性率”)标题(“ROC曲线”)

ROC曲线和AUC表明,该模型几乎完全分类测试样品的观察。
查找使用AUC好套索处罚
要确定使用逻辑回归学习者线性分类模型良好的套索刑罚强度,比较AUC的测试样本值。
加载NLP的数据集。预处理的数据作为预测试验样品标签。
加载nlpdataYstats = Y ==“统计”;X = X';
创建数据分区,指定要抵抗的观察的10%。提取测试样本指数。
RNG(10);%用于重现分区= cvpartition(Ystats,'坚持',0.10);testIdx =试验(分区);XTEST = X(:,testIdx);N =总和(testIdx)
N = 3157
YTest = Ystats(testIdx);
有测试样品中的3157周的观察。
创建从一组11对数间隔的正规化优势 通过 。
波长= LOGSPACE(-6,-0.5,11);
火车二进制使用每个正规化的优势,线性分类模型。优化利用SpaRSA目标函数。降低目标函数的梯度公差1E-8。
CVMdl = fitclinear(X,Ystats,'ObservationsIn','列',...'CVPartition',划分,'学习者',“物流”,“求解”,'sparsa',...“正规化”,'套索',“拉姆达”,λ,'GradientTolerance',1E-8)
CVMdl = classreg.learning.partition.ClassificationPartitionedLinear CrossValidatedModel: '线性' ResponseName: 'Y' NumObservations:31572 KFold:1个分区:[1x1的cvpartition]类名:[0 1] ScoreTransform: '无' 的属性,方法
提取训练的线性分类模型。
Mdl1 = CVMdl.Trained {1}
Mdl1 = ClassificationLinear ResponseName: 'Y' 的类名:[0 1] ScoreTransform: '分对数' 贝塔:[34023x11双]偏压:[1x11双] LAMBDA:[1x11双]学习者: '物流' 的属性,方法
MDL是ClassificationLinear模型对象。因为LAMBDA是正规化的优势序列,你能想到的MDL作为11款车型,一个在每个正规化强度LAMBDA。
估计测试样品的预测的标签和后级的概率。
[标号,后] =预测(Mdl1,XTEST,'ObservationsIn','列');Mdl1.ClassNames;后(3,1,5)
ANS = 1.0000
标签是预测标签的3157×11矩阵。每列对应于所述模型的预测的标签训练有素使用相应的正则化强度。后是后验概率类的3157×2×11矩阵。列对应的类和页面对应正规化的优势。例如,后(3,1,5)表示的后验概率,所述第一类(标签0)由模型使用分配给观测3拉姆达(5)作为正规化强度是1.0000。
对于每个模型,计算出AUC。指定第二类为正类。
AUC = 1:numel(LAMBDA);预分配%对于J = 1:numel(LAMBDA)[〜,〜,〜,AUC(J)] = perfcurve(YTest,后(:,2,J),Mdl1.ClassNames(2));结束
值越大,LAMBDA导致预测变量稀疏,这是一个分类的优良品质。对于每一个正规化的强度,使用整个数据集和相同的选项,当你训练模型的训练线性分类模型。确定每个模型的非零系数的数量。
MDL = fitclinear(X,Ystats,'ObservationsIn','列',...'学习者',“物流”,“求解”,'sparsa',“正规化”,'套索',...“拉姆达”,λ,'GradientTolerance',1E-8);numNZCoeff =总和(Mdl.Beta〜= 0);
在同一图中,画出测试样品错误率以及对于每个正则化强度的非零系数的频率。绘制对数刻度的所有变量。
数字;并[h,HL1,HL2] = plotyy(日志10(LAMBDA),日志10(AUC),...日志10(LAMBDA),日志10(numNZCoeff + 1));hL1.Marker ='O';hL2.Marker ='O';ylabel(H(1),'LOG_ {10} AUC')ylabel(H(2),“LOG_ {10}的非零系数频率”)xlabel('LOG_ {10} LAMBDA')标题(“试验采样统计信息”)保持离

选择正规化强度指数是平衡预测变量的稀疏性和高AUC。在这种情况下,之间的值 至 应该足够了。
idxFinal = 9;
从模型MDL与所选择的正则化强度。
MdlFinal = selectModels(MDL,idxFinal);
MdlFinal是ClassificationLinear建模含有一个正则化强度。为了估计新的观察标签,合格MdlFinal和新数据预测。
更多关于
扩展功能
介绍了在R2016a
您还可以选择从下面的列表中的网站:
