主要内容
使内核分布对象适合于数据
这个例子展示了如何将核概率分布对象拟合到样本数据。
步骤1。加载示例数据。
加载示例数据。
负载carsmall;
这个数据包括每加仑行驶的英里数(英里/加仑)按原产国分类的不同汽车制造商和型号的测量值(起源)、模型年(一年)和其他车辆特性。
步骤2。适合内核分布对象。
使用fitdist将核概率分布对象拟合为每加仑英里数(英里/加仑)所有汽车的数据。
pd = fitdist(英里/加仑,“内核”)
pd = KernelDistribution Kernel = normal Bandwidth = 4.11428 万博1manbetxSupport = unbounded
这将创建一个概率。KernelDistribution对象。默认情况下,fitdist使用一个正常的核平滑函数,并选择一个最佳带宽来估计正常的密度,除非你另有规定。您可以访问关于适合度的信息,并使用相关的对象函数执行进一步的计算。
步骤3。计算描述性统计。
计算拟合核分布的平均值、中值和标准偏差。
m =意味着(pd)
m = 23.7181
地中海=值(pd)
地中海= 23.4841
s =性病(pd)
s = 8.9896.
步骤4。计算和绘制pdf。
计算并绘制拟合内核分布的PDF。
图x = 0:1:60;x y = pdf (pd);情节(x, y,“线宽”2)标题(英里每加仑的)包含(“英里”)
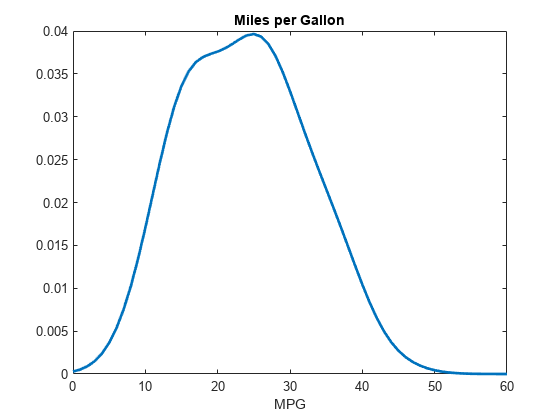
图中显示了内核发行版的pdf文件英里/加仑所有车型的数据。它的分布是平滑和相当对称的,尽管它有轻微的倾斜和较重的右尾巴。
第5步。生成随机数。
从拟合内核分布生成随机数的向量。
rng ('默认')%的再现性r =随机(pd, 1000, (1);图嘘(r);集(get (gca),“孩子”),“FaceColor”,(。8。8 1]);持有在y = y * 5000;%缩放pdf覆盖直方图情节(x, y,“线宽”2)标题(“由分布产生的随机数”)举行从
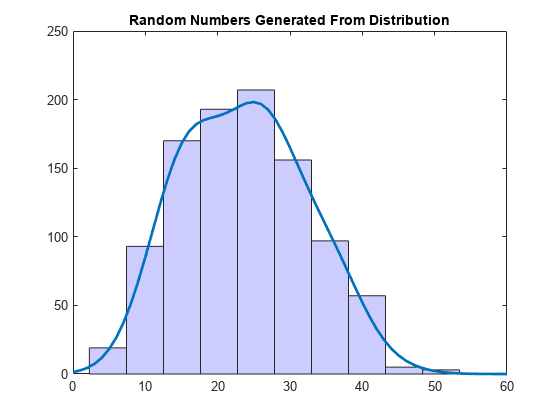
直方图的形状与pdf图相似,因为从非参数核分布生成的随机数与样本数据吻合。
另请参阅
fitdist|KernelDistribution|ksdensity
相关话题
你也可以从以下列表中选择一个网站:
