Fitdist.
适合数据的概率分布对象
句法
描述
例子
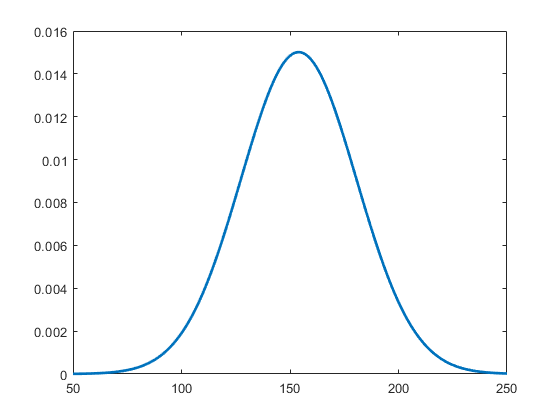
适合数据的正态分布
加载示例数据。创建一个包含患者权重数据的向量。
加载医院x = hospital.Weight;
通过拟合数据来创建一个正态分布对象。
pd = fitdist (x,'普通的')
正态分布mu = 154 [148.728, 159.272] sigma = 26.5714 [23.3299, 30.8674]
参数估计旁边的区间是分布参数的95%置信区间。
绘制分布图的pdf。
x_values = 50:1:250;y = pdf (pd, x_values);情节(x_values y“线宽”, 2)
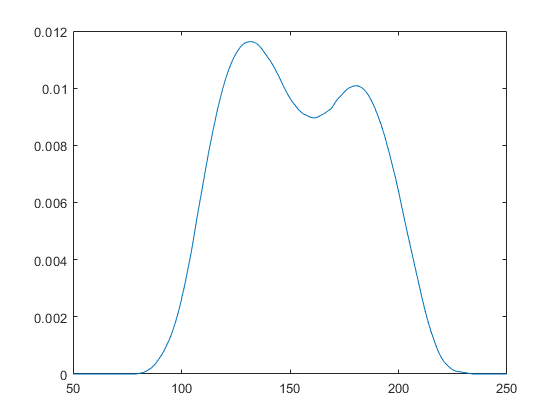
将内核分布适合于数据
加载示例数据。创建一个包含患者权重数据的向量。
加载医院x = hospital.Weight;
通过将内核分布对象与数据拟合来创建内核分布对象。使用epannichikov核函数。
pd = fitdist (x,'核心'那'核心'那“埃帕内切尼科夫”)
pd = KernelDistribution Kernel = epanechnikov Bandwidth = 14.3792 万博1manbetxSupport = unbounded
绘制分布图的pdf。
x_values = 50:1:250;y = pdf (pd, x_values);情节(x_values, y)
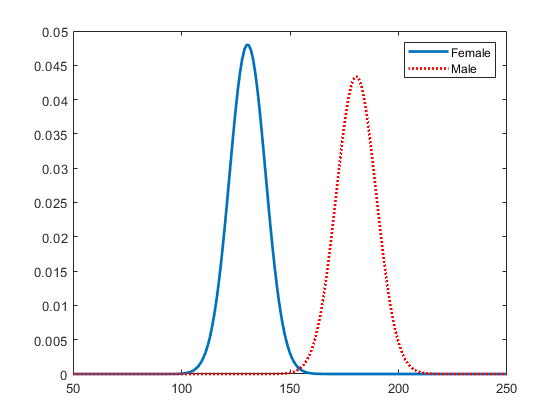
适合分组数据的正常分布
加载示例数据。创建一个包含患者权重数据的向量。
加载医院x = hospital.Weight;
通过将它们拟合到数据来创建正常分布对象,由患者性别分组。
性别=医院.Sex;[pdca,gn,gl] = fitdist(x,'普通的'那'经过'、性别)
pdca =1×2个单元阵列{1x1 prob.normaldistribution} {1x1 prob.normaldistribution}
gn =2 x1细胞{'女人男人' }
德国劳埃德船级社=2 x1细胞{'女人男人' }
细胞阵列pdca包含两个概率分布对象,每个性别组都是一个。细胞阵列GN.包含两个组标签。细胞阵列GL.包含两个组级别。
查看单元格数组中的每个分布pdca为了比较平均值,μ和标准偏差,Sigma.,按患者性别分组。
女= pdca {1}%女性的分布
正态分布mu = 130.472 [128.183, 132.76] sigma = 8.30339 [6.96947, 10.2736]
男性= PDCA {2}%男性分布情况
正态分布mu = 180.532 [177.833, 183.231] sigma = 9.19322 [7.63933, 11.5466]
计算每个分发版的pdf。
x_值=50:1:250;femalepdf=pdf(女性,x_值);malepdf=pdf(男性,x_值);
绘制PDF,以便按性别直观比较体重分布。
图绘制(x_values femalepdf,“线宽”,2)持有在情节(x_values malepdf,“颜色”那'r'那“线条样式”那“:”那“线宽”,2)传奇(GN,“位置”那“东北”)举行从
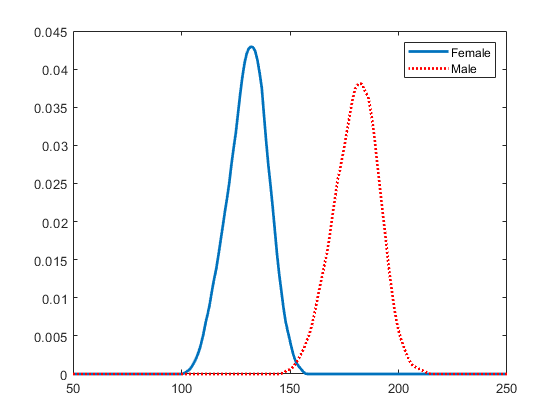
将内核分发拟合到分组数据
加载示例数据。创建一个包含患者权重数据的向量。
加载医院x = hospital.Weight;
通过将它们与数据进行拟合,创建内核分布对象,并按患者性别分组。使用三角核函数。
性别=医院.Sex;[pdca,gn,gl] = fitdist(x,'核心'那'经过'、性别、'核心'那'三角形');
查看单元格数组中的每个分布pdca查看每种性别的内核发行版。
女= pdca {1}%女性的分布
女性= kerneldistribution kernel =三角带宽= 4.25894支持=无限制万博1manbetx
男性= PDCA {2}%男性分布情况
男性=内核分布内核=三角形带宽=5.08961支持=无限万博1manbetx
计算每个分发版的pdf。
x_值=50:1:250;femalepdf=pdf(女性,x_值);malepdf=pdf(男性,x_值);
绘制PDF,以便按性别直观比较体重分布。
图绘制(x_values femalepdf,“线宽”,2)持有在情节(x_values malepdf,“颜色”那'r'那“线条样式”那“:”那“线宽”,2)传奇(GN,“位置”那“东北”)举行从
输入参数
输出参数
算法
这Fitdist.函数使用极大似然估计拟合大多数分布。两个例外是正态分布和对数正态分布与未删失数据。
对于非截尾数正态分布,参数的估计值是方差无偏估计的平方根。
对于非截尾对数正态分布,参数的估计值为数据对数方差的无偏估计的平方根。
选择功能
工具书类
约翰逊,n.l., S. Kotz和N. Balakrishnan。连续单变量分布.第1卷,霍博肯,新泽西州:Wiley-Interscience, 1993。
约翰逊,n.l., S. Kotz和N. Balakrishnan。连续单变量分布.卷。2,Hoboken,NJ:Wiley-Interscience,1994。
鲍曼,A. W.和阿扎里尼。应用平滑技术进行数据分析. 纽约:牛津大学出版社,1997。
扩展功能
你也可以从以下列表中选择一个网站:
