FSCCHI2.
使用Chi-Square测试进行分类的单变量特征排名
句法
描述
idx.= fscchi2(TBL.那responsevarname.)TBL.包含预测变量和响应变量,以及responsevarname.是响应变量的名称TBL.。函数返回idx.,其中包含通过预测的重要性排序的预测器指数,意思IDX(1)是最重要的预测指标的指数。您可以使用idx.选择分类问题的重要预测因子。
例子
矩阵中的排名预测器
在数字矩阵中排名预测器,并创建预测值重视分数的条形图。
加载样本数据。
加载电离层
电离层包含预测变量(X)和一个响应变量(y)。
使用Chi-Square测试等待预测器。
[Idx,scores] = fscchi2(x,y);
价值得分是否定的日志P.- 值。如果一个P.-Value小于EPS(0),那么相应的分数值是INF.。在创建条形图之前,请确定是否得分包括INF.价值观。
查找(ISINF(分数))
ans = 1x0空双排向量
得分不包括INF.价值观。如果得分包括INF.值,可以替换INF.在为可视化目的创建条形图之前,通过一个大数字号码。有关详细信息,请参阅桌子中的排名预测器。
创建一个预测标志重要评分的条形图。
BAR(分数(IDX))XLABEL('预测的排名')ylabel('预测重点评分')
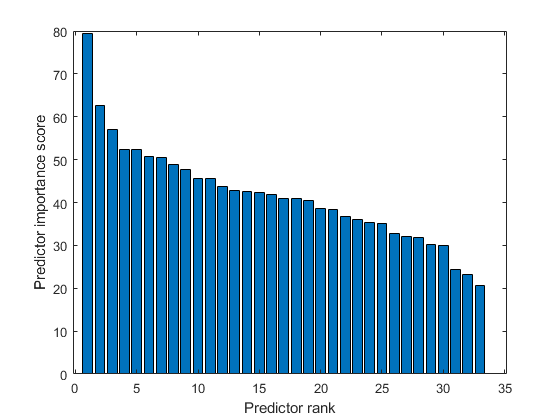
选择前五大最重要的预测因子。找到这些预测器的列X。
IDX(1:5)
ans =.1×55 7 3 8 6
第五列X是最重要的预测因子y。
桌子中的排名预测器
排名在表中的预测器,并创建一个预测的标准重要性分数的条形图。
如果您的数据在表格中FSCCHI2.在表中排列变量的子集,然后函数仅使用子集索引变量。因此,良好的做法是移动你不想排名在表格的末尾的预测器。移动响应变量和观察权重向量。然后,输出参数的索引与表的索引一致。
加载人口普查1994数据集。
加载人口普查1994.
桌子AdultData.在人口普查1994.包含来自美国人口普查局的人口统计数据,以预测个人每年赚超过50,000美元。显示表的前三行。
头(AdultData,3)
ans =.3×15表年龄workClass fnlwgt教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY工资___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______ 39国政务77516个学士13未婚ADM-文书不在位家庭白人男性2174 0 40美国联合国<= 50K 50自我emp-not-Inc 83311学士学位13结婚 - Civ-Spouse exec-Manigher丈夫白色男0 0 1 13美国<= 50K 38私人2.1565E + 05 HS-GRAD 9离婚处理人员 - 清洁剂Not-In-Family White Male 0 0 0 40美国<= 50K
在表格中AdultData.,第三列fnlwgt.是样品的重量,以及最后一列薪水是响应变量。移动fnlwgt.至左侧薪水通过使用搬运活动功能。
AdultData = MoveVars(AdultData,'fnlwgt'那'前'那'薪水');头(AdultData,3)
ans =.3×15表年龄workClass教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY fnlwgt工资___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______ 39国政务学士13未婚ADM-文书不在位家庭白人男性21740 40美国77516 <= 50K 50自我Emp-Not Inc学士13结婚 - Civ-Spouse Exec-Manager Justric Males 0 0 1 13美国83311 <= 50K 38私人HS-Grad 9离婚处理器 - 清洁剂Not-In-Family White Male 0 0 0 40美国2.1565E + 05 <= 50K
排名预测因子AdultData.。指定列薪水作为响应变量,并指定列fnlwgt.作为观察权重。
[Idx,scores] = fscchi2(amertandata,'薪水'那'重量'那'fnlwgt');
价值得分是否定的日志P.- 值。如果一个P.-Value小于EPS(0),那么相应的分数值是INF.。在创建条形图之前,请确定是否得分包括INF.价值观。
idxinf = find(isinf(scores))
Idxinf =.1×81 3 4 5 6 7 10 12
得分包括八个INF.价值观。
创建一个预测标志重要分数的条形图。使用预测的名称X-axis刻度标签。
图栏(分数(IDX))XLabel('预测的排名')ylabel('预测重点评分')XTicklabels(Strrep(Adjordata.properties.variablenames(Idx),'_'那'\ _'))xtickangle(45)
这酒吧功能不会为此提供任何条形INF.价值观。为了INF.值,具有与最大有限分数相同的绘图栏。
抓住上BAR(分数(IDX(长度(idxinf)+1))*(长度(idxinf),1))图例('有限分数'那'INF分数') 抓住离开
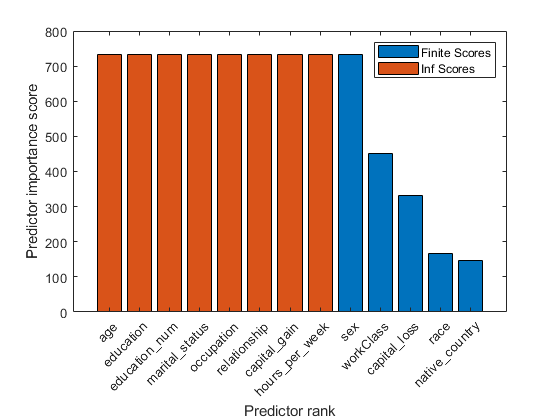
条形图显示使用不同颜色的有限分数和INF分数。
输入参数
输出参数
算法
您还可以从以下列表中选择一个网站:
