fsrnca
使用回归邻里成分分析的特征选择
描述
例子
检测数据的相关功能使用NCA的回归
生成,响应变量取决于3日,9日,15日和预测数据的玩具。
RNG(0,“扭腰”);%用于重现N = 100;X =兰特(N,20);Y = 1 + X(:,3)* 5 + SIN(X(:,9)./ X(:,15)+ 0.25 * randn(N,1));
适合回归邻里成分分析模型。
MDL = fsrnca(X,Y,“放牧”1,“拉姆达”,0.5 / N);
ø求解= LBFGS,HessianHistorySize = 15,LineSearchMethod = weakwolfe | ==================================================================================================== ||ITER |FUN VALUE |NORM GRAD |NORM STEP |CURV |GAMMA |ALPHA |接受| |====================================================================================================| | 0 | 1.636932e+00 | 3.688e-01 | 0.000e+00 | | 1.627e+00 | 0.000e+00 | YES | | 1 | 8.304833e-01 | 1.083e-01 | 2.449e+00 | OK | 9.194e+00 | 4.000e+00 | YES | | 2 | 7.548105e-01 | 1.341e-02 | 1.164e+00 | OK | 1.095e+01 | 1.000e+00 | YES | | 3 | 7.346997e-01 | 9.752e-03 | 6.383e-01 | OK | 2.979e+01 | 1.000e+00 | YES | | 4 | 7.053407e-01 | 1.605e-02 | 1.712e+00 | OK | 5.809e+01 | 1.000e+00 | YES | | 5 | 6.970502e-01 | 9.106e-03 | 8.818e-01 | OK | 6.223e+01 | 1.000e+00 | YES | | 6 | 6.952347e-01 | 5.522e-03 | 6.382e-01 | OK | 3.280e+01 | 1.000e+00 | YES | | 7 | 6.946302e-01 | 9.102e-04 | 1.952e-01 | OK | 3.380e+01 | 1.000e+00 | YES | | 8 | 6.945037e-01 | 6.557e-04 | 9.942e-02 | OK | 8.490e+01 | 1.000e+00 | YES | | 9 | 6.943908e-01 | 1.997e-04 | 1.756e-01 | OK | 1.124e+02 | 1.000e+00 | YES | | 10 | 6.943785e-01 | 3.478e-04 | 7.755e-02 | OK | 7.621e+01 | 1.000e+00 | YES | | 11 | 6.943728e-01 | 1.428e-04 | 3.416e-02 | OK | 3.649e+01 | 1.000e+00 | YES | | 12 | 6.943711e-01 | 1.128e-04 | 1.231e-02 | OK | 6.092e+01 | 1.000e+00 | YES | | 13 | 6.943688e-01 | 1.066e-04 | 2.326e-02 | OK | 9.319e+01 | 1.000e+00 | YES | | 14 | 6.943655e-01 | 9.324e-05 | 4.399e-02 | OK | 1.810e+02 | 1.000e+00 | YES | | 15 | 6.943603e-01 | 1.206e-04 | 8.823e-02 | OK | 4.609e+02 | 1.000e+00 | YES | | 16 | 6.943582e-01 | 1.701e-04 | 6.669e-02 | OK | 8.425e+01 | 5.000e-01 | YES | | 17 | 6.943552e-01 | 5.160e-05 | 6.473e-02 | OK | 8.832e+01 | 1.000e+00 | YES | | 18 | 6.943546e-01 | 2.477e-05 | 1.215e-02 | OK | 7.925e+01 | 1.000e+00 | YES | | 19 | 6.943546e-01 | 1.077e-05 | 6.086e-03 | OK | 1.378e+02 | 1.000e+00 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 20 | 6.943545e-01 | 2.260e-05 | 4.071e-03 | OK | 5.856e+01 | 1.000e+00 | YES | | 21 | 6.943545e-01 | 4.250e-06 | 1.109e-03 | OK | 2.964e+01 | 1.000e+00 | YES | | 22 | 6.943545e-01 | 1.916e-06 | 8.356e-04 | OK | 8.649e+01 | 1.000e+00 | YES | | 23 | 6.943545e-01 | 1.083e-06 | 5.270e-04 | OK | 1.168e+02 | 1.000e+00 | YES | | 24 | 6.943545e-01 | 1.791e-06 | 2.673e-04 | OK | 4.016e+01 | 1.000e+00 | YES | | 25 | 6.943545e-01 | 2.596e-07 | 1.111e-04 | OK | 3.154e+01 | 1.000e+00 | YES | Infinity norm of the final gradient = 2.596e-07 Two norm of the final step = 1.111e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 2.596e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
绘制选择的要素。的不相关特征的权重应该是接近于零。
图()图(mdl.FeatureWeights,'RO')网格上xlabel(“特色指标”)ylabel(“特征权重”)
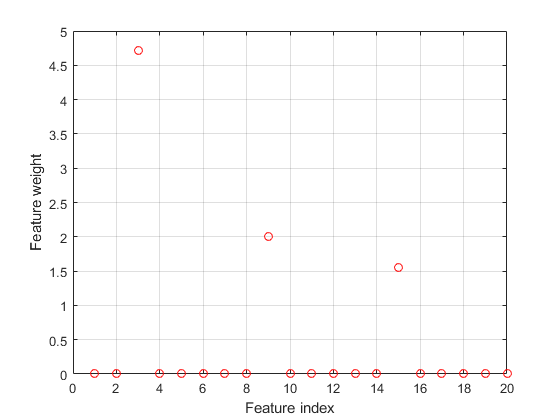
fsrnca正确地检测此响应的相关预测。
调正则化参数在NCA的回归
加载样本数据。
加载robotarm.mat
该robotarm(pumadyn32nm)数据集使用具有7168点训练的观测,并与32个特征[1] [2] 1024个测试观察机器人臂模拟器创建。这是原始数据集的预处理版本。的数据由减去关闭线性回归拟合预处理,随后的所有特征正常化单位方差。
执行邻里成分分析(NCA)特征选择回归与默认 (正则化参数)值。
NCA = fsrnca(Xtrain,ytrain,'使用fitmethod','精确',...“求解”,'lbfgs');
绘制选定的值。
图图(nca.FeatureWeights,'RO')xlabel(“特色指标”)ylabel(“特征权重”)网格上
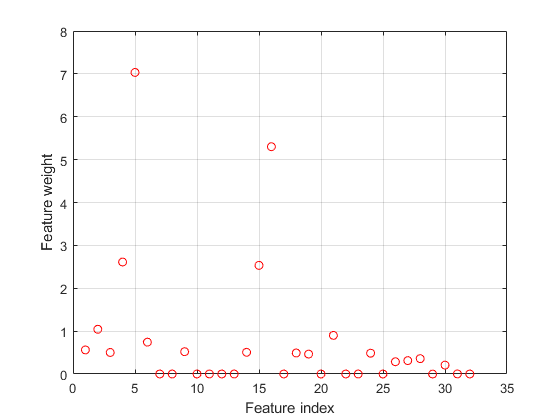
以上的功能权重的一半是非零。计算使用测试通过使用所选择的特征设定为性能的测量的损失。
L =损失(NCA,XTEST,ytest)
L = 0.0837
尝试改善性能。调整调整参数 用于使用特征选择5倍交叉验证。调音 手段找到 值产生最小回归损失。调 使用交叉验证:
1.分区数据成五倍。对于每个倍,cvpartition受让人4/5中的数据作为训练集,并且所述数据作为测试组的1/5。
RNG(1)%用于重现N =长度(ytrain);CVP = cvpartition(长度(ytrain),'kfold',5);numvalidsets = cvp.NumTestSets;
分配
对于搜索值。乘以常数响应值增加了由恒定的因子的损失函数项。因此,包括STD(ytrain)在要素
值平衡违约损失函数('狂',平均绝对偏差)项和目标函数的调整项。在这个例子中,STD(ytrain)因子是一个,因为所加载的样品的数据是原始数据集的预处理版本。
lambdavals = linspace(0,50,20)* STD(ytrain)/ N;
创建一个数组来存储损失值。
lossvals =零(长度(lambdavals),numvalidsets);
2.培养每个NCA模型 值,使用在各个折叠训练集。
3.计算用于使用NCA模型在折叠相应的测试集的回归损失。记录的损耗值。
4.重复此为每个 值和每个折。
对于I = 1:长度(lambdavals)对于K = 1:numvalidsets X = Xtrain(cvp.training(K),:);Y = ytrain(cvp.training(K),:);Xvalid = Xtrain(cvp.test(K),:);yvalid = ytrain(cvp.test(K),:);NCA = fsrnca(X,Y,'使用fitmethod','精确',...“求解”,'minibatch-lbfgs',“拉姆达”,lambdavals(i)中,...'GradientTolerance',1E-4,'IterationLimit',30);lossvals(I,K)=损失(NCA,Xvalid,yvalid,'LossFunction','MSE');结束结束
计算从折叠每个获得的平均损失 值。
meanloss =平均值(lossvals,2);
绘制的平均损失兑 值。
图图(lambdavals,meanloss,“滚装”)xlabel(“拉姆达”)ylabel('损失(MSE)')网格上
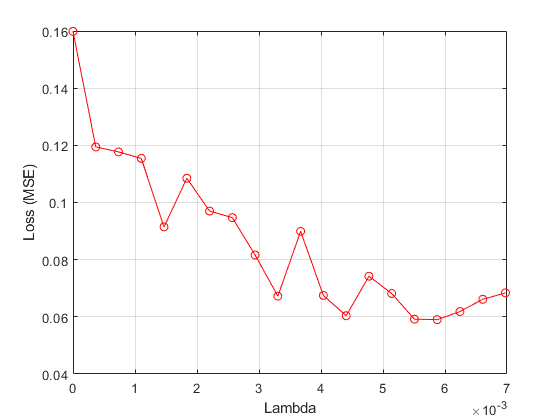
找出 值,使得最小损耗值。
[〜,IDX] =分钟(meanloss)
IDX = 17
bestlambda = lambdavals(IDX)
bestlambda = 0.0059
bestloss = meanloss(IDX)
bestloss = 0.0590
适合使用回归的最佳NCA功能,选择模型 值。
NCA = fsrnca(Xtrain,ytrain,'使用fitmethod','精确',...“求解”,'lbfgs',“拉姆达”,bestlambda);
绘制选择的要素。
图图(nca.FeatureWeights,'RO')xlabel(“特色指标”)ylabel(“特征加权”)网格上

大部分的功能权重为零。fsrnca识别四种最相关的特征。
计算的测试集的损失。
L =损失(NCA,XTEST,ytest)
L = 0.0571
调整调整参数, ,消除更多的不相关特征和改进的性能。
比较NCA和ARD特征选择
此示例使用鲍鱼数据[3][4]从UCI机器学习库[5]。下载数据,并将其与名称保存在当前文件夹'abalone.data'。
将数据存储到一个表。显示前七行。
TBL = readtable('abalone.data','文件类型','文本','ReadVariableNames',假);tbl.Properties.VariableNames = {'性别','长度','直径','高度',...'WWeight','SWeight','VWeight','ShWeight','NoShellRings'};TBL(1:7,:)
ANS =7×9表性别长度直径高度WWeight SWeight VWeight ShWeight NoShellRings _____ ______ ________ ______ _______ _______ ________ ____________ { 'M'} 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15 { 'M'} 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7 { 'F'} 0.530.42 0.135 0.677 0.2565 0.1415 0.21 9 { 'M'} 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10 { 'I'} 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7 { 'I'} 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8 { 'F'} 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20
该数据集有4177个观察。我们的目标是从八个物理测量预测鲍鱼的年龄。最后一个变量,环箍的数量,显示了鲍鱼的年龄。第一预测是分类变量。该表中的最后一个变量是响应变量。
准备预测和响应变量fsrnca。的最后一列TBL包含壳环的数量,这是响应变量。第一个预测变量,性别,是绝对的。您必须创建虚拟变量。
Y = table2array(TBL(:,端));X(:,1:3)= dummyvar(分类(tbl.Sex));X = [X,table2array(TBL(:,2:端-1))];
使用交叉验证四倍调整在NCA模型调整参数。第一个分区的数据划分为四个倍。
RNG('默认')%用于重现N =长度(Y);CVP = cvpartition(N,'kfold',4);numtestsets = cvp.NumTestSets;
cvpartition将数据划分成四个分区(倍)。在各个折叠,数据的大约四分之三被分配作为训练集和四分之一被分配作为测试集合。
生成各种 (正则化参数),用于拟合模型来确定的最佳值 值。创建一个向量来从各装配收集损耗值。
lambdavals = linspace(0,25,20)* STD(Y)/ N;lossvals =零(长度(lambdavals),numtestsets);
的行lossvals对应于
值和列对应于折叠。
使用适合回归模型NCAfsrnca从每个数据倍使用每个
值。计算用于使用来自各个折叠测试数据的每个模型的损失。
对于I = 1:长度(lambdavals)对于K = 1:numtestsets Xtrain = X(cvp.training(K),:);ytrain = Y(cvp.training(K),:);XTEST = X(cvp.test(K),:);ytest = Y(cvp.test(K),:);NCA = fsrnca(Xtrain,ytrain,'使用fitmethod','精确',...“求解”,'lbfgs',“拉姆达”,lambdavals(i)中,“标准化”,真正);lossvals(I,K)=损失(NCA,XTEST,ytest,'LossFunction','MSE');结束结束
计算所述褶皱的平均损失,即,计算的平均值中的第二维lossvals。
meanloss =平均值(lossvals,2);
绘出 值相对于从四个褶皱的平均损失。
图图(lambdavals,meanloss,“滚装”)xlabel(“拉姆达”)ylabel('损失(MSE)')网格上

找出 值最小化均损失。
[〜,IDX] =分钟(meanloss);bestlambda = lambdavals(IDX)
bestlambda = 0.0071
计算最佳的损耗值。
bestloss = meanloss(IDX)
bestloss = 4.7799
适合使用最好上的所有数据的NCA模型 值。
NCA = fsrnca(X,Y,'使用fitmethod','精确',“求解”,'lbfgs',...“放牧”1,“拉姆达”,bestlambda,“标准化”,真正);
ø求解= LBFGS,HessianHistorySize = 15,LineSearchMethod = weakwolfe | ==================================================================================================== ||ITER |FUN VALUE |NORM GRAD |NORM STEP |CURV |GAMMA |ALPHA |接受| |====================================================================================================| | 0 | 2.469168e+00 | 1.266e-01 | 0.000e+00 | | 4.741e+00 | 0.000e+00 | YES | | 1 | 2.375166e+00 | 8.265e-02 | 7.268e-01 | OK | 1.054e+01 | 1.000e+00 | YES | | 2 | 2.293528e+00 | 2.067e-02 | 2.034e+00 | OK | 1.569e+01 | 1.000e+00 | YES | | 3 | 2.286703e+00 | 1.031e-02 | 3.158e-01 | OK | 2.213e+01 | 1.000e+00 | YES | | 4 | 2.279928e+00 | 2.023e-02 | 9.374e-01 | OK | 1.953e+01 | 1.000e+00 | YES | | 5 | 2.276258e+00 | 6.884e-03 | 2.497e-01 | OK | 1.439e+01 | 1.000e+00 | YES | | 6 | 2.274358e+00 | 1.792e-03 | 4.010e-01 | OK | 3.109e+01 | 1.000e+00 | YES | | 7 | 2.274105e+00 | 2.412e-03 | 2.399e-01 | OK | 3.557e+01 | 1.000e+00 | YES | | 8 | 2.274073e+00 | 1.459e-03 | 7.684e-02 | OK | 1.356e+01 | 1.000e+00 | YES | | 9 | 2.274050e+00 | 3.733e-04 | 3.797e-02 | OK | 1.725e+01 | 1.000e+00 | YES | | 10 | 2.274043e+00 | 2.750e-04 | 1.379e-02 | OK | 2.445e+01 | 1.000e+00 | YES | | 11 | 2.274027e+00 | 2.682e-04 | 5.701e-02 | OK | 7.386e+01 | 1.000e+00 | YES | | 12 | 2.274020e+00 | 1.712e-04 | 4.107e-02 | OK | 9.461e+01 | 1.000e+00 | YES | | 13 | 2.274014e+00 | 2.633e-04 | 6.720e-02 | OK | 7.469e+01 | 1.000e+00 | YES | | 14 | 2.274012e+00 | 9.818e-05 | 2.263e-02 | OK | 3.275e+01 | 1.000e+00 | YES | | 15 | 2.274012e+00 | 4.220e-05 | 6.188e-03 | OK | 2.799e+01 | 1.000e+00 | YES | | 16 | 2.274012e+00 | 2.859e-05 | 4.979e-03 | OK | 6.628e+01 | 1.000e+00 | YES | | 17 | 2.274011e+00 | 1.582e-05 | 6.767e-03 | OK | 1.439e+02 | 1.000e+00 | YES | | 18 | 2.274011e+00 | 7.623e-06 | 4.311e-03 | OK | 1.211e+02 | 1.000e+00 | YES | | 19 | 2.274011e+00 | 3.038e-06 | 2.528e-04 | OK | 1.798e+01 | 5.000e-01 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 20 | 2.274011e+00 | 6.710e-07 | 2.325e-04 | OK | 2.721e+01 | 1.000e+00 | YES | Infinity norm of the final gradient = 6.710e-07 Two norm of the final step = 2.325e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 6.710e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
绘制选择的要素。
图图(nca.FeatureWeights,'RO')xlabel(“特色指标”)ylabel(“特征加权”)网格上

不相关的特征具有零个权重。根据该图中,设有1,图3和未被选择9。
适合使用回归量方法的参数估计和所述子集用于预测的完全独立的条件方法高斯过程回归(GPR)模型。使用ARD平方指数核函数,其中个体重量分配给每个预测。规范的预测。
gprMdl = fitrgp(TBL,'NoShellRings','KernelFunction','ardsquaredexponential',...'使用fitmethod','SR','PredictMethod',“同人”,“标准化”,真正)
gprMdl = RegressionGP PredictorNames:{ '性别' '长度' '直径' '身高' 'WWeight' 'SWeight' 'VWeight' 'ShWeight'} ResponseName: 'NoShellRings' CategoricalPredictors:1个ResponseTransform: '无' NumObservations:4177 KernelFunction:'ARDSquaredExponential” KernelInformation:[1×1结构] BasisFunction: '恒' 贝塔:11.4959西格玛:2.0282 PredictorLocation:[10×1双] PredictorScale:[10×1双]阿尔法:[1000×1双] ActiveSetVectors:[1000×10双] PredictMethod: 'FIC' ActiveSetSize:1000使用fitmethod: 'SR' ActiveSetMethod: '随机' IsActiveSetVector:[4177×1逻辑]对数似然:-9.0019e + 03 ActiveSetHistory:[1×1结构] BCDInformation:[]属性,方法
计算上的训练模型训练数据(resubstitution损失)回归损失。
L = resubLoss(gprMdl)
L = 4.0306
用最小的交叉验证损失fsrnca是与使用具有ARD内核GPR模型获得的损失。
输入参数
输出参数
参考
[1] Rasmussen的,C. E.,R. M.尼尔,G. E.欣顿,D.面包车Campand,M. Revow,Z. Ghahramani,R. Kustra,R. Tibshirani。该DELVE手册,1996年,http://mlg.eng.cam.ac.uk/pub/pdf/RasNeaHinetal96.pdf。
[2]多伦多大学计算机科学系。藏坑的数据集。http://www.cs.toronto.edu/~delve/data/datasets.html。
[3]沃里克J.N。,T. L.卖方,S. R.塔尔博特,A. J.考索恩,和W. B.福特。“鲍鱼(鲍种)从北海岸和巴斯海峡的岛屿塔斯马尼亚一,黑蝶鲍鱼(H.杨梅)的人口生物学研究。”海洋渔业部门,技术报告第48号(ISSN 1034-3288),1994年。
[4] S.沃。“扩展和基准级联关系”,博士论文。计算机科学系,塔斯马尼亚州,1995年大学。
[5] Lichman,M. UCI机器学习知识库。尔湾,CA:加州大学信息与计算机科学学院,2013年http://archive.ics.uci.edu/ml。
介绍了在R2016b
您还可以选择从下面的列表中的网站:
