K-均值聚类
本主题介绍K-表示聚类和使用统计和机器学习工具箱的示例™ 功能K均值为数据集找到最佳群集解决方案。
介绍K-均值聚类
K-表示聚类是一种分区方法。这个函数K均值将数据划分为K互斥簇,并返回它分配每个观测到的簇的索引。K均值将数据中的每个观察视为在空间中具有位置的对象。该函数查找一个分区,其中每个群集中的对象彼此尽可能接近,并且尽可能远离其他群集中的对象。您可以选择距离度量配合K均值基于数据的属性。与许多聚类方法一样,K-意味着群集需要您指定群集的数量K在聚类之前。
与分层聚类不同,K-意味着聚类作用于实际观测值,而不是数据中每对观测值之间的差异。此外,K-表示集群创建单一层次的集群,而不是多层层次的集群。因此,K-意味着对于大量数据,聚类通常比分层聚类更适合。
每个集群在一个K表示分区由成员对象和中心(或中心)组成。在每个集群,K均值最小化质心和簇的所有成员对象之间的距离之和。K均值为支持的距离度量以不同的方式计算质心集群。万博1manbetx有关详细信息,请参见“距离”.
可以使用可用的名称-值对参数控制最小化的详细信息K均值;例如,您可以指定群集中心的初始值和算法的最大迭代次数。默认情况下,K均值使用K——+ +算法初始化簇质心,并使用平方欧几里德距离度量确定距离。
表演时K-表示群集,请遵循以下最佳做法:
比较K-意味着为不同的属性值提供聚类解决方万博 尤文图斯案K确定数据的最佳群集数。
通过检查剪影图和剪影值来评估聚类解决方案万博 尤文图斯。你也可以用the
评估聚类函数根据间隙值、剪影值、Davies-Bouldin指数和Cal万博 尤文图斯inski-Harabasz指数等标准来评估聚类解决方案。从随机选择的不同质心复制聚类,返回所有重复中距离总和最小的解。
比较K-表示群集解决方案万博 尤文图斯
这个例子中探索K-表示在四维数据集上进行聚类。该示例显示了如何通过使用轮廓图和值来分析不同结果来确定数据集的正确聚类数K-表示群集解决方案。该示例还显示了如万博 尤文图斯何使用“复制品”名称-值对参数来测试指定数量的可能解决方案,并返回距离总和最低的那个。万博 尤文图斯
加载数据集
加载kmeansdata数据集。
rng (“默认”)%的再现性装载(“kmeansdata.mat”)尺寸(X)
ans =1×2560 4
数据集是四维的,不容易可视化。然而,K均值使您能够调查数据中是否存在组结构。
创建集群并检查分离
使用。将数据集划分为三个集群K——集群。指定城市街区距离度量,并使用默认值K-means++算法的集群中心初始化。使用“显示”名称-值对参数,用于打印解决方案的最终距离和。
[idx3,C,sumdist3]=kmeans(X,3,“距离”,“城市街区”,“显示”,“最后一次”);
重复1、7次迭代,总距离之和= 2459.98。距离的最佳总和= 2459.98
idx3包含群集索引,该索引指示中每一行的群集分配X.要查看最终的星团是否分离得很好,可以创建一个剪影图。
剪影图显示了一个星团中的每个点与相邻星团中的点的距离。这个度量的范围从1(表示距离相邻的集群非常远的点)到0(在一个或另一个集群中不明显的点)到-1(可能分配给错误的集群的点)。轮廓在其第一个输出中返回这些值。
从中创建轮廓图idx3具体说明“城市街区”距离度量表示K-表示聚类是基于绝对差值之和。
[silh3 h] =轮廓(X, idx3“城市街区”);xlabel(“轮廓值”) ylabel (“集群”)
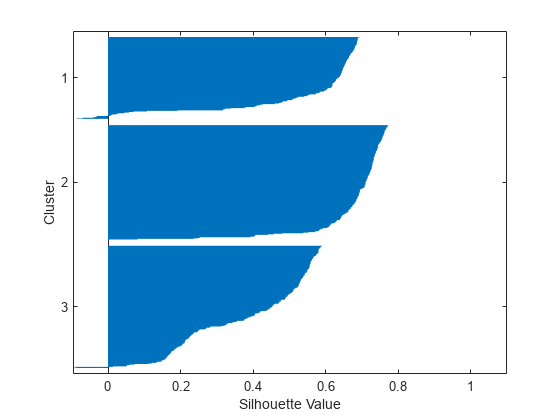
剪影图显示,第2个聚类中的大部分点剪影值较大(大于0.6),说明该聚类与相邻聚类有一定的分离。但是,第三个簇中包含了许多低剪影值的点,而第一个和第三个簇中又包含了一些负剪影值的点,说明这两个簇并没有很好地分离。
看看K均值可以找到更好的数据分组,将集群的数量增加到4个。的方法打印关于每个迭代的信息“显示”名称-值对参数。
idx4=kmeans(X,4,“距离”,“城市街区”,“显示”,“国际热核实验堆”);
iter phase num sum 1 1 560 1792.72 2 1 6 1771.1最佳距离总和= 1771.1
为四个簇创建轮廓图。
[silh4,h]=轮廓(X,idx4,“城市街区”);xlabel(“轮廓值”) ylabel (“集群”)
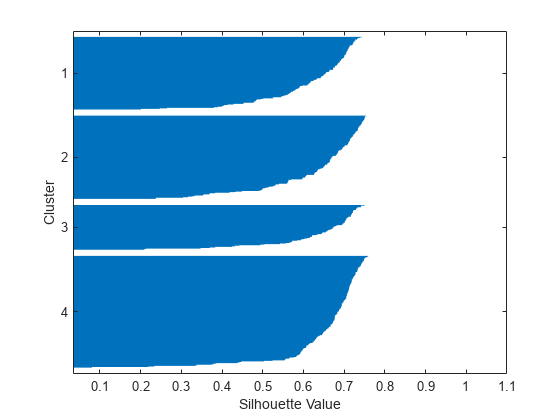
剪影图表明,这四个聚类比前一个解决方案中的三个聚类分离得更好。您可以通过计算两种情况的平均轮廓值,采用更定量的方法来比较两种解决方案。万博 尤文图斯
计算平均轮廓值。
聚类3=平均值(silh3)
聚类3=0.5352
聚类4=平均值(silh4)
cluster4 = 0.6400
四个簇的平均剪影值高于三个簇的平均剪影值。这些值支持剪影图中所示的结万博1manbetx论。
最后,在数据中找到五个集群。创建一个轮廓图,并计算五个集群的平均轮廓值。
idx5 = kmeans (X 5“距离”,“城市街区”,“显示”,“最后一次”);
重复1、7次迭代,总距离之和= 1647.26。距离的最佳总和= 1647.26
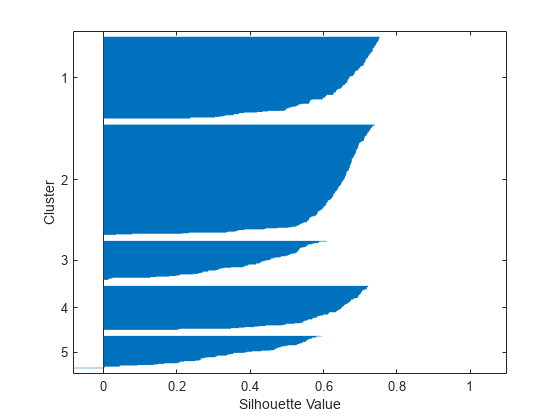
[silh5 h] =轮廓(X, idx5“城市街区”);xlabel(“轮廓值”) ylabel (“集群”)
平均值(silh5)
ans = 0.5721
轮廓图表明,5个簇可能不是正确的簇数,因为两个簇包含的点大多具有较低的轮廓值,而第五个簇包含少数具有负值的点。此外,五个簇的平均轮廓值低于四个簇的值。不知道如何如果数据中有ny簇,那么最好对一系列值进行实验K,集群的数量。
请注意,距离之和随着簇数的增加而减小2459.98到1771.1到1647.26随着集群数量从3个增加到4个,再增加到5个。因此,距离之和对于确定最优簇数并无用处。
避免局部最小值
默认情况下,K均值使用随机选择的一组初始质心位置开始聚类过程。的K均值算法可以收敛到一个局部(非全局)最小值的解;也就是说,K均值可以对数据进行分区,从而将任意一个点移动到不同的簇中会增加距离的总和K均值到达的地点有时取决于起点。因此,对于数据可以存在其他具有较低万博 尤文图斯总距离和的解(局部最小解)。你可以使用“复制品”用于测试不同解决方案的名称-值对参数。当指定多个复制时,万博 尤文图斯K均值对每个重复从随机选取的不同质心开始重复聚类过程,返回所有重复之间距离总和最小的解。
在数据中找到四个集群,并将集群复制五次。另外,指定城市街区距离度量,并使用“显示”名称-值对参数打印每个解决方案的最终距离和。
[idx4, cent4 sumdist] = kmeans (X 4“距离”,“城市街区”,...“显示”,“最后一次”,“复制品”,5);
重复1、2次迭代,总距离之和= 1771.1。重复2、3次迭代,总距离之和= 1771.1。重复3,3次迭代,总距离之和= 1771.1。重复4,6次迭代,总距离之和= 2300.23。重复5次,2次迭代,总距离之和= 1771.1。距离的最佳总和= 1771.1
在复制4中,K均值找到一个局部最小值。因为每次复制都是从随机选择的一组不同的初始质心开始的,K均值有时会找到多个局部极小值。但是,最终的解决方案是K均值Returns是所有复制的距离总和最低的一个。
求由返回的最终解的点到质心距离的簇内和的总和K均值.
金额(sumdist)
ans = 1.7711 e + 03
另见
相关的话题
你也可以从以下列表中选择一个网站:
