主要内容
执行非负矩阵分解
这个例子展示了如何执行非负矩阵分解。
加载样例数据。
负载摩尔X =摩尔(:1:5);rng (“默认”);%的再现性
计算二阶近似X使用乘法更新算法,从5个随机初始值开始W和H。
选择= statset (“麦克斯特”10“显示”,“最后一次”);[W0, H0] = nnmf (X, 2,“复制”5,“选项”选择,“算法”,“乘”);
重复迭代rms resid |delta x| 1 10 358.296 0.00190554 2 10 78.3556 0.000351747 3 10 230.962 0.0172839 4 10 326.347 0.007395552 5 10 361.547 0.00705539最终均方根残差= 78.3556
的“乘”算法对初始值非常敏感,因此在使用时是很好的选择“复制”找到W和H从多个随机的起始值。
现在使用交替最小二乘算法进行因式分解,它收敛更快,更一致。从最初开始,运行100次以上的迭代W0和H0确认以上。
选择= statset (“麦克斯特”, 1000,“显示”,“最后一次”);[W H] = nnmf (X, 2,“w0”W0,“h0”H0,“选项”选择,“算法”,“als”);
rep迭代rms resid |delta x| 1 2 77.5315 0.000830334最终均方根残差= 77.5315
这两列W是转换后的预测器。两排H给出5个预测因子的相对贡献X到预测者W。显示H。
H
H =2×50.0835 0.0190 0.1782 0.0072 0.9802 0.0559 0.0250 0.9969 0.0085 0.0497
第五种预测X(权重0.9802)显著影响第一个预测因子W。第三个预测因素X(权重0.9969)强烈影响第2个预测因子W。
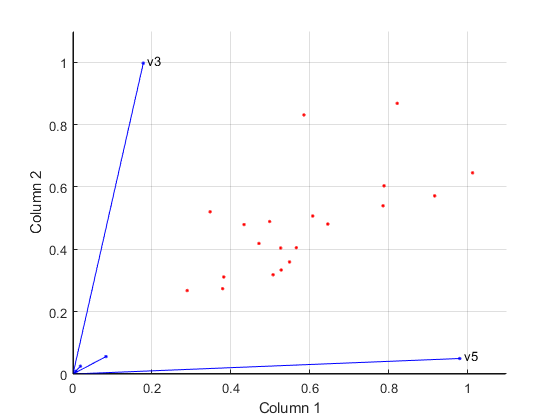
将预测者的相对贡献可视化X与biplot的列空间中显示数据和原始变量W。
biplot (H ',“分数”W,“varlabels”, {'','',v3的,'',“v5”});Axis ([0 1.1 0 1.1]) xlabel(第一列的) ylabel (第2列的)
另请参阅
相关的话题
你也可以从以下列表中选择一个网站:
