nnmf.
Nonnegative matrix factorization
描述
[因素n-通过-mmatrixW,H] = nnmf(A,k)Ainto nonnegative factorsW(n-通过-k)和H(k-通过-m)。分解并不准确;W * H.is a lower-rank approximation toA。因素W和H最小化根均方差异D之间A和W * H.。
d = norm(a - w * h,'fro'/ sqrt(n * m)
分组使用从随机初始值开始的迭代算法W和H。因为根均值均衡D可能具有局部最小值,重复的因素可能会产生不同W和H。Sometimes the algorithm converges to a solution of lower rank thank, which can indicate that the result is not optimal.
例子
Nonnegative Rank-Two Approximation and Biplot
Load the sample data.
loadfisheriris
Compute a nonnegative rank-two approximation of the measurements of the four variables in Fisher's iris data.
RNG(1)重复性的%[w,h] = nnmf(meas,2);H
h =2×4.0.6945 0.2856 0.6220 0.2218 0.8020 0.5683 0.1834 0.0149
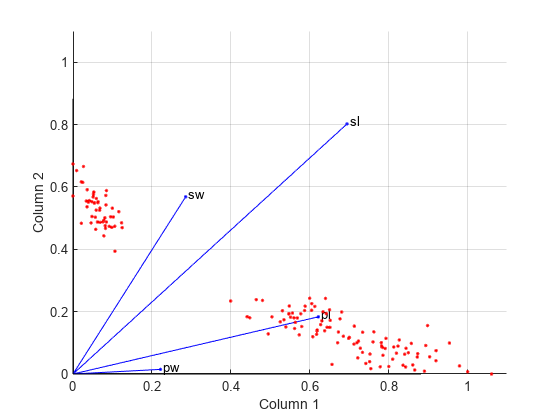
The first and third variables in测定(萼片长度和花瓣长度,分别为0.6945和0.6220)为第一栏提供相对强大的重量W。第一和第二变量测定(萼片长度和萼片宽度,分别为0.8020和0.5683)为第二栏提供相对强的重量W。
创建一个biplot数据和变量测定in the column space ofW。
biplot(H','Scores',w,'VarLabels',{'sl','sw','pl','pw'}); axis([0 1.1 0 1.1]) xlabel('Column 1')ylabel('Column 2')
改变算法
从随机数组开始Xwith rank 20, try a few iterations at several replicates using the multiplicative algorithm.
rng默认重复性的%x = rand(100,20)*兰特(20,50);opt = statset('maxiter',5,'显示','最后');[W0,H0] = nnmf(x,5,'复制'10,......'选项',opt,......'算法',“MULT”);
rep iteration rms resid |delta x| 1 5 0.560887 0.0245182 2 5 0.66418 0.0364471 3 5 0.609125 0.0358355 4 5 0.608894 0.0415491 5 5 0.619291 0.0455135 6 5 0.621549 0.0299965 7 5 0.640549 0.0438758 8 5 0.673015 0.0366856 9 5 0.606835 0.0318931 10 5 0.633526 0.0319591 Final root mean square residual = 0.560887
Continue with more iterations from the best of these results using alternating least squares.
opt = statset('Maxiter',1000,'显示','最后');[w,h] = nnmf(x,5,'w0',W0,'H0',H0,......'选项',opt,......'算法','als');
rep iteration rms resid |delta x| 1 24 0.257336 0.00271859 Final root mean square residual = 0.257336
Input Arguments
输出参数
参考资料
[1] Berry,Michael W.,Murray Browne,Amy N. Langville,V.Paul Pauca和Robert J. Plemons。“近似非环境矩阵分解的算法和应用。”Computational Statistics & Data Analysis52, no. 1 (September 2007): 155–73.https://doi.org/10.1016/j.csda.2006.11.006。
扩展能力
You can also select a web site from the following list:
Americas
- América拉丁(Español)
- Canada(英语)
- United States(英语)
