incrementalLearner
将支持向量机(S万博1manbetxVM)回归模型转化为增量学习模型
描述
IncrementalMdl= incrementalLearner (Mdl)IncrementalMdl,利用传统训练的线性支持向量机模型的超参数和系数进行回归;Mdl。因为它的属性值反映了从中获得的知识Mdl,IncrementalMdl可以根据新的观察结果预测标签,是吗温暖的这意味着它的预测性能会被跟踪。
IncrementalMdl= incrementalLearner (Mdl,名称,值)IncrementalMdl在它的预测性能被跟踪之前。例如,“MetricsWarmupPeriod”,50岁,“MetricsWindowSize”,100指定在跟踪性能指标之前的初始增量训练周期为50个观察值,并指定在更新性能指标之前处理100个观察值。
例子
将传统训练模型转化为增量学习模型
训练支持向量机回归模型fitrsvm,然后将其转化为增量学习算法。
加载和预处理数据
加载2015年纽约市住房数据集。有关数据的更多详细信息,请参见纽约市开放数据。
负载NYCHousing2015
提取响应变量SALEPRICE从桌子上。为了数值稳定性,刻度SALEPRICE通过1 e6。
Y = nyhousing2015 . saleprice /1e6;NYCHousing2015。salesprice = [];
从分类预测器创建虚拟变量矩阵。
猫= [“区”“BUILDINGCLASSCATEGORY”“社区”];dumvarstbl = varfun(@(x)dummyvar(分类(x)), nyhousing2015,…“数据源”, catvars);Dumvarmat = table2array(dumvarstbl);nyhousing2015 (:,catvars) = [];
将表中的所有其他数值变量视为销售价格的线性预测因子。将虚拟变量矩阵连接到预测器数据的其余部分。
idxnum = varfun(@isnumeric,NYCHousing2015,“OutputFormat”,“统一”);X = [dumvarmat NYCHousing2015{:,idxnum}];
训练SVM回归模型
从数据集中随机抽取5000个观测值,拟合SVM回归模型。抛弃支持向量(万博1manbetxα),以便软件使用线性系数(β)进行预测。
N = nummel (Y);N = 5000;rng (1);%为了重现性idx = randsample(N, N);TTMdl = fitrsvm(X(idx,:),Y(idx));TTMdl = discard万博1manbetxSupportVectors(TTMdl)
TTMdl = RegressionSVM responsenname: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' Beta: [312x1 double] Bias: -3.2469e+11 KernelParameters: [1x1 struct] NumObservations: 5000 BoxConstraints: [5000x1 double] ConvergenceInfo: [1x1 struct] I万博1manbetxsSupportVector: [5000x1 logical] Solver: 'SMO'属性,方法
TTMdl是一个RegressionSVM模型对象表示传统训练的SVM回归模型。
转换训练模型
将传统训练的SVM回归模型转化为线性回归模型进行增量学习。
IncrementalMdl =增量学习者(TTMdl)
IncrementalMdl = incrementalRegressionLinear IsWarm: 1 Metrics: [1x2 table] ResponseTransform: 'none' Beta: [312x1 double] Bias: -3.2469e+11 Learner: 'svm' Properties, Methods
IncrementalMdl是一个incrementalRegressionLinear利用支持向量机为增量学习准备模型对象。
的
incrementalLearner通过传递学习系数和其他信息来初始化增量学习器TTMdl从训练数据中提取。IncrementalMdl是温暖的(IsWarm是1),这意味着增量学习函数可以开始跟踪性能指标。的
incrementalLearner函数使用自适应尺度不变求解器训练模型,而fitrsvm训练有素的TTMdl使用SMO求解器。
预测的反应
通过转换传统训练模型创建的增量学习器无需进一步处理即可生成预测。
使用两种模型预测所有观测值的销售价格。
ttyfit = predict(TTMdl,X);ilyfit = predict(IncrementalMdl,X);Compareyfit = norm(ttyfit - ilyfit)
Compareyfit = 0
模型生成的拟合值之差为0。
指定SGD求解器
默认解算器是自适应尺度不变解算器。如果您指定此求解器,则不需要为训练调整任何参数。然而,如果您指定标准SGD或ASGD求解器,您还可以指定一个估计周期,在此期间,增量拟合函数将调整学习率。
加载和洗牌2015年纽约市住房数据集。有关数据的更多详细信息,请参见纽约市开放数据。
负载NYCHousing2015rng (1)%为了重现性n = size(nyhousing2015,1);Shuffidx = randsample(n,n);NYCHousing2015 = NYCHousing2015(shuffidx,:);
提取响应变量SALEPRICE从桌子上。为了数值稳定性,刻度SALEPRICE通过1 e6。
Y = nyhousing2015 . saleprice /1e6;NYCHousing2015。salesprice = [];
从分类预测器创建虚拟变量矩阵。
猫= [“区”“BUILDINGCLASSCATEGORY”“社区”];dumvarstbl = varfun(@(x)dummyvar(分类(x)), nyhousing2015,…“数据源”, catvars);Dumvarmat = table2array(dumvarstbl);nyhousing2015 (:,catvars) = [];
将表中的所有其他数值变量视为销售价格的线性预测因子。将虚拟变量矩阵连接到预测器数据的其余部分。
idxnum = varfun(@isnumeric,NYCHousing2015,“OutputFormat”,“统一”);X = [dumvarmat NYCHousing2015{:,idxnum}];
将数据随机分为5%和95%两组:第一组用于传统训练模型,第二组用于增量学习。
CVP = cvpartition(n,“坚持”, 0.95);Idxtt = training(cvp);Idxil = test(cvp);% 5%为传统培训Xtt = X(idxtt,:);Ytt = Y(idxtt);95%设置为增量学习Xil = X(idxil,:);Yil = Y(idxil);
对5%的数据拟合SVM回归模型。
TTMdl = fitrsvm(Xtt,Ytt);
将传统训练的SVM回归模型转化为线性回归模型进行增量学习。指定标准SGD求解器和的估计周期2 e4观察值(默认为1000当需要一个学习率时)。
增量学习器(增量学习器)“规划求解”,“sgd”,“EstimationPeriod”2 e4);
IncrementalMdl是一个incrementalRegressionLinear模型对象。
将增量模型拟合到其余数据中适合函数。在每次迭代中:
通过一次处理10个观测值来模拟数据流。
用一个新的拟合进入观测值的增量模型覆盖先前的增量模型。
存储学习率和 看看系数和学习率在训练过程中是如何演变的。
%预先配置nil = null (nil);numObsPerChunk = 10;nchunk = floor(nil/numObsPerChunk);learnrate = [IncrementalMdl.LearnRate;0 (nchunk 1)];beta1 = [IncrementalMdl.Beta(1)];0 (nchunk 1)];%增量拟合为j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1);iend = min(nil,numObsPerChunk*j);Idx = ibegin:iend;IncrementalMdl = fit(IncrementalMdl,Xil(idx,:), Xil(idx));bet1 (j + 1) = IncrementalMdl.Beta(1);learnrate(j + 1) = IncrementalMdl.LearnRate;结束
IncrementalMdl是一个incrementalRegressionLinear在流中的所有数据上训练的模型对象。
看看学习速度和 在训练中进化,把它们画在单独的子图上。
Subplot (2,1,1) plot(beta1) hold住在ylabel (“\ beta_1”)参照线(IncrementalMdl。EstimationPeriod/numObsPerChunk,r -。);Subplot (2,1,2) plot(learnrate) ylabel(学习速率的)参照线(IncrementalMdl。EstimationPeriod/numObsPerChunk,r -。);包含(“迭代”)
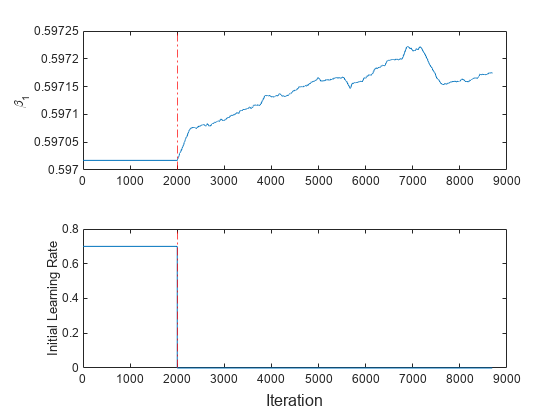
学习率在估计周期后跳转到其自动调整值。
因为适合在估计期间,模型不能与流数据拟合,
对于前2000次迭代(20,000个观察值)是常数。然后,
略有变化适合将模型与10个观测值中的每一个新块相匹配。
配置性能指标选项
使用训练好的SVM回归模型初始化增量学习器。通过指定一个指标预热期来准备增量学习器,在此期间updateMetricsAndFit函数只适合模型。指定500个观测值的度量窗口大小。
加载机械臂数据集。
负载robotarm
有关数据集的详细信息,请输入描述在命令行。
将数据随机分为5%和95%两组:第一组用于传统训练模型,第二组用于增量学习。
N = nummel (ytrain);rng (1)%为了重现性CVP = cvpartition(n,“坚持”, 0.95);Idxtt = training(cvp);Idxil = test(cvp);% 5%为传统培训Xtt = Xtrain(idxtt,:);Ytt = ytrain(idxtt);95%设置为增量学习Xil = Xtrain(idxil,:);Yil = ytrain(idxil);
对第一组进行SVM回归模型拟合。
TTMdl = fitrsvm(Xtt,Ytt);
将传统训练的SVM回归模型转化为线性回归模型进行增量学习。请指定以下内容:
性能指标预热期为2000个观察值。
指标窗口大小为500个观察值。
使用epsilon不敏感损失、MSE和平均绝对误差(MAE)来衡量模型的性能。该软件支持epsilon不万博1manbetx敏感损失和MSE。创建一个匿名函数来测量每个新观测值的绝对误差。创建包含该名称的结构数组
MeanAbsoluteError以及它对应的函数。
Maefcn = @(z,zfit)abs(z - zfit);memetric = struct(“MeanAbsoluteError”, maefcn);增量学习器(增量学习器)“MetricsWarmupPeriod”, 2000,“MetricsWindowSize”, 500,…“指标”, {“epsiloninsensitive”mse的maemetric});
将增量模型拟合到其余数据中updateMetricsAndfit函数。在每次迭代中:
通过一次处理50个观测值来模拟数据流。
用一个新的拟合进入观测值的增量模型覆盖先前的增量模型。
存储估计的系数 ,累积度量,以及窗口度量,以查看它们在增量学习期间是如何演变的。
%预先配置nil = null (nil);numObsPerChunk = 50;nchunk = floor(nil/numObsPerChunk);Ei = array2table(0 (nchunk,2),“VariableNames”, (“累积”“窗口”]);Mse = array2table(0 (nchunk,2),“VariableNames”, (“累积”“窗口”]);Mae = array2table(0 (nchunk,2),“VariableNames”, (“累积”“窗口”]);bet1 = 0 (nchunk,1);%增量拟合为j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1);iend = min(nil,numObsPerChunk*j);Idx = ibegin:iend;IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx));ei{j,:} = IncrementalMdl。指标{“EpsilonInsensitiveLoss”,:};mse{j,:} = IncrementalMdl。指标{“MeanSquaredError”,:};mae{j,:} = IncrementalMdl。指标{“MeanAbsoluteError”,:};bet1 (j + 1) = IncrementalMdl.Beta(10);结束
IncrementalMdl是一个incrementalRegressionLinear在流中的所有数据上训练的模型对象。在增量学习和模型预热过程中,updateMetricsAndFit检查模型对传入观测值的性能,然后将模型拟合到该观测值。
以了解性能指标和 在训练中进化,把它们画在单独的子图上。
图;Subplot (2,2,1) plot(beta1) ylabel(“\ beta_{10}”) xlim([0 nchunk]);参照线(IncrementalMdl。MetricsWarmupPeriod/numObsPerChunk,r -。);包含(“迭代”) subplot(2,2,2) h = plot(ei.Variables);xlim ([0 nchunk]);ylabel (“不敏感损失”)参照线(IncrementalMdl。MetricsWarmupPeriod/numObsPerChunk,r -。);传奇(h, ei.Properties.VariableNames)包含(“迭代”) subplot(2,2,3) h = plot(mse.Variables);xlim ([0 nchunk]);ylabel (MSE的)参照线(IncrementalMdl。MetricsWarmupPeriod/numObsPerChunk,r -。);传奇(h, mse.Properties.VariableNames)包含(“迭代”) subplot(2,2,4) h = plot(mae.Variables);xlim ([0 nchunk]);ylabel (“美”)参照线(IncrementalMdl。MetricsWarmupPeriod/numObsPerChunk,r -。);传奇(h, mae.Properties.VariableNames)包含(“迭代”)
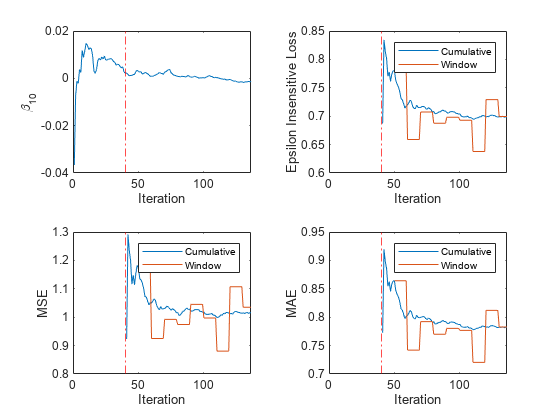
情节表明updateMetricsAndFit做以下事情:
适合 在所有增量学习迭代中。
仅在指标预热期之后计算性能指标。
计算每次迭代期间的累积度量。
在处理500个观察值后计算窗口度量。
