正规化判别分析分类
这个例子展示了如何通过试图删除预测,不伤模型的预测能力做出一个更强大和更简单的模型。当你在你的数据很多预测这一点尤其重要。线性判别分析使用两个正则化参数,γ和δ,以识别并移除多余的预测因子。该cvshrink方法有助于确定这些参数的适当的设置。
加载数据,并创建一个分类。
创建一个的线性判别分析分类卵巢癌数据。设置SaveMemory和FillCoeffs名称 - 值对的参数,以保持生成的模型相当小。为了计算方便,本例中使用的有关预测的三分之一训练分类随机子集。
加载卵巢癌RNG(1);%用于重现numPred =尺寸(OBS,2);观测值=观测值(:,randsample(numPred,小区(numPred / 3)));MDL = fitcdiscr(OBS,GRP,'SaveMemory','上','FillCoeffs',“关”);
交叉验证分类。
使用25级的伽玛和25级的三角洲寻找好的参数。这种搜索是耗时。组详细至1查看进度。
[ERR,γ,δ,numpred] = cvshrink(MDL,...'NumGamma'24,'NumDelta'24,“放牧”,1);
做建筑交叉验证模型。处理伽马步骤1出25.处理伽玛步骤2的出25.处理伽玛步骤3的出25.处理伽玛步骤4的出25.处理伽玛步骤5的出25.处理伽玛步骤6的出来25.处理伽玛步骤7出25.处理伽玛步骤8的出25.处理伽玛步骤9的出25.处理伽玛步骤10的出25处理伽马步骤11的出25处理伽马步骤12的出25处理伽马步骤13的出25.处理伽玛步骤的14个25处理伽马步骤的15个25处理伽马步骤的16个25处理伽马步骤17出来25.处理伽玛步骤18的出25处理伽马步骤19出来的25.处理伽玛步骤20出来25.处理伽玛步骤21出来25.处理伽玛步骤22的出25处理伽马步骤23出来25.处理伽玛步骤24出来25.处理伽玛步骤25的出25的构成。
检查正规化分类的质量。
暗算错误预测的数量。
图(ERR,numpred,数 'k'。)xlabel(“错误率”)ylabel(“预测数”)
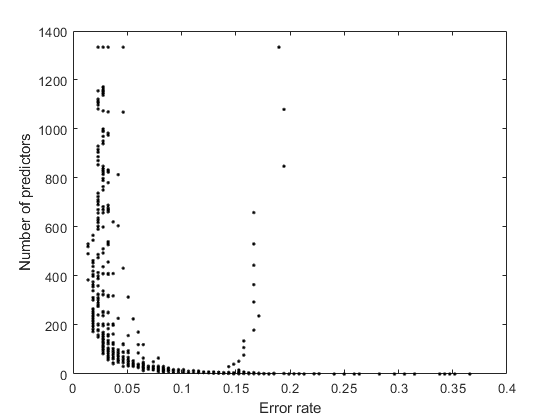
更仔细地检查图的左下部分。
轴([0 0.1 0 1000])
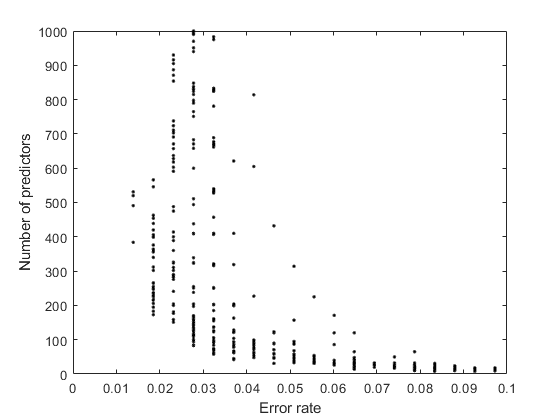
有较低的数字预测的和较低的误差之间存在明显的权衡。
选择模型的大小和精度之间的最佳平衡。
多对伽玛和三角洲值会产生大约相同的最小误差。显示这些对和值的指数。
首先,找到最小的误差值。
minerr =分钟(分钟(ERR))
minerr = 0.0139
查找的标呃产生最小误差。
[P,Q] =查找(ERR
从标线性指数转换。
IDX = sub2ind(大小(增量),P,Q);
显示伽玛和三角洲值。
[伽马(P)δ(IDX)]
ANS =4×20.7202 0.1145 0.7602 0.1131 0.8001 0.1128 0.8001 0.1410
这些点与在模型中非零系数的总预测的少29%。
numpred(IDX)/小区(numPred / 3)×100
ANS =4×139.8051 38.9805 36.8066 28.7856
为了进一步降低预测的数量,你必须接受更大的错误率。例如,选择伽玛和三角洲,给200个或更少的预测最低的误差率。
low200 =分钟(分钟(ERR(numpred <= 200)));lownum =分钟(分钟(numpred(ERR == low200)));[low200 lownum]
ANS =1×20.0185 173.0000
你需要173个预测达到0.0185的错误率,这是那些具有200个预测或更少的中最低的误差率。
显示伽玛和三角洲即达到预测的这个错误/数字。
[R,S] =查找((ERR == low200)&(numpred == lownum));[伽马(R);增量(R,S)]
ANS =2×10.6403 0.2399
设置正规化参数。
要设置与这些值的分类伽玛和三角洲,使用点记号。
Mdl.Gamma =伽马(R);Mdl.Delta = DELTA(R,S);
热图情节
为了比较cvshrink计算,在郭,黑斯蒂和Tibshirani[1],积热误差和预测的对数的映射伽玛和的索引三角洲参数。(该三角洲参数范围取决于的值伽玛参数。因此,要获得一个矩形图,用三角洲索引,而不是参数本身。)
%创建增量索引矩阵INDX = repmat(1:大小(增量,2),大小(增量,1),1);图副区(1,2,1)于imagesc(ERR)彩条的颜色表('喷射')标题(“分类错误”)xlabel(“三角洲指数”)ylabel(“伽马指数”)副区(1,2,2)于imagesc(numpred)彩条标题(“模型预测数”)xlabel(“三角洲指数”)ylabel(“伽马指数”)
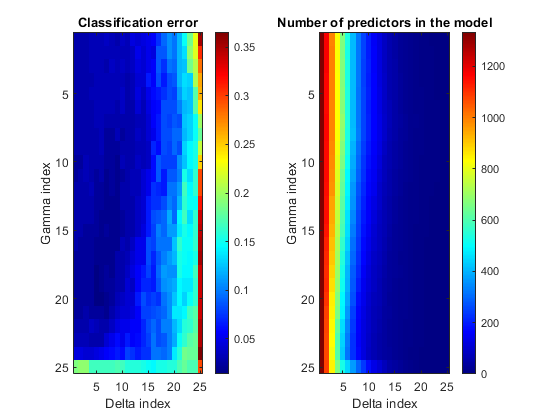
你看到的最好的分类错误时三角洲虽小,但最少的预测时,三角洲大。
参考
[1]过,Y.,T.黑斯蒂和R. Tibshirani。正规判别分析及其在芯片中的应用。生物统计学,卷。8,第1期,第86-100,2007年。
也可以看看
功能
对象
相关话题
您还可以选择从下面的列表中的网站:
