并行规范宽数据
这个例子展示了如何用比观察更多的预测因子来规范一个模型。广泛的数据是数据的预测因素多于观察结果。通常,对于广泛的数据,您希望识别重要的预测器。使用lassoglm作为探索或筛选工具,可以选择较小的变量,以优先考虑您的建模和研究。使用并行计算来加速交叉验证。
加载ovariancancer数据。该数据有216个观测数据和4000个预测数据奥林匹克广播服务公司工作空间变量。反应也是二进制的“癌症”或者“正常”,在grp工作空间变量。将响应转换为二进制以供中使用lassoglm.
负载ovariancancery = strcmp (grp,“癌症”);
设置使用并行计算的选项。准备并行计算使用parpool.
选择= statset (“UseParallel”,真的);Parpool()
使用“本地”配置文件启动并行池(Parpool)连接到并行池(工人数:6)。ANS = ProcessPool具有属性:Connected:True NumWorkers:6群集:本地连接文件:{} autoaddclientPath:true idledimeout:30分钟(剩余30分钟)spmded:true
匹配一组交叉验证的规范化模型。使用α参数,以支持保留组高度相关的预测,而不是消除所有,但一个成员的组。通常,使用相对较大的值α.
RNG('默认')%的再现性tic [b,s] = lassoglm(obs,y,'二重子',“NumLambda”, 100,...“α”, 0.9,“LambdaRatio”1的军医,“简历”10“选项”、选择);toc
经过时间是90.892114秒。
检查交叉验证的阴谋。
lassoPlot (B S“PlotType”,“简历”);传奇(“显示”)%显示传奇

检查跟踪情节。
lassoPlot (B S“PlotType”,“λ”,“XScale”,“日志”)

右边(绿色)的垂直虚线表示λ提供最小的交叉验证偏差。左边(蓝色)虚线具有最小偏差加上不超过一个标准差。这条蓝线有更少的预测因素:
[S.DF (S.Index1SE) S.DF (S.IndexMinDeviance)]
ans =1×250 89
你问lassoglm为了适应使用100个不同的λ值。它用了多少?
尺寸(b)
ans =1×24000 84
lassoglm在84个值之后停止,因为偏差太小了λ值。为了避免过度拟合,lassoglm当拟合模型的偏差相对于二元响应的偏差太小时停止,忽略预测变量。
你可以强迫lassoglm属性包含更多术语“λ”名称-值对的论点。例如,定义一组λ中值之外还包含三个小于中值的值S.Lambda.
minLambda = min (S.Lambda);explicitLambda = [minLambda *[。1.01 .001] S.Lambda];
指定“λ”,explicitLambda当你调用lassoglm函数。lassoglm当拟合模型的偏差太小时停止,即使您显式地提供了一组λ值。
为了节省时间,你可以使用:
更少的
λ,意味着更少的发作更少的交叉验证折叠
更大的值
LambdaRatio
使用串行计算和所有三种节省时间的方法:
tic [bquick,squick] = lassoglm(obs,y,'二重子',“NumLambda”25岁的...“LambdaRatio”1飞行,“简历”5);toc
运行时间是16.517331秒。
以图形方式将新结果与第一个结果进行比较。
lassoPlot (Bquick Squick,“PlotType”,“简历”);传奇(“显示”)%显示传奇

lassoPlot (Bquick Squick,“PlotType”,“λ”,“XScale”,“日志”)
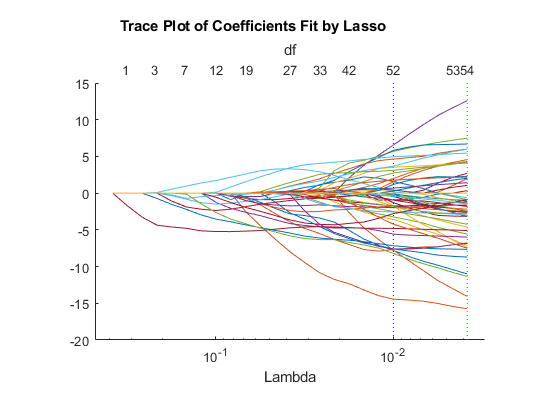
在最低加一个标准差的模型中,非零系数的数量约为50,与第一次计算相似。
你也可以从以下列表中选择一个网站:
