t-SNE
t-SNE是什么?
t-SNE (徐)是一种用于可视化高维数据的维度降低的维度降低的算法。这个名字代表T.- 分布的随机邻居嵌入。该想法是以尊重点之间的相似性的方式嵌入低维度的高维点。附近的高维空间点对应于附近的嵌入式低维点,高维空间中的远距点对应于遥远的嵌入式低维点。(一般来说,不可能匹配高维和低维空间之间的距离。)
这徐函数从高维数据创建一组低维点。通常,您可视化低维点,以在原始高维数据中看到自然集群。
该算法采用以下一般步骤将数据嵌入到低维中。
计算高维点之间的成对距离。
创建标准偏差σ.一世对于每个高尺寸点一世所以这样困惑每个点处于预定水平。对于困惑的定义,见计算距离,高斯方差和相似点.
计算相似度矩阵.这是X的联合概率分布,定义为等式1.
创建一个低维点的初始集合。
迭代更新低维点,以最小化高维空间中的高斯分布与aT.在低维空间分布。该优化过程是算法最耗时的部分。
查看van der Maaten和Hinton[1].
T-SNE算法
基本的t-SNE算法执行以下步骤。
准备数据
徐首先删除包含任何的输入数据x的每一行南价值观。然后,如果标准化名称-值对是真正的那徐X的中心是减去每一列的均值,X的比例是除以每一列的标准差。
原位作者van der毛根和宾馆[1]建议使用将原始数据X减少到低维版本主成分分析(PCA).您可以设置徐NumPCAComponents名称 - 值对与您喜欢的维度数量,也许50.要在此步骤中锻炼更多,请使用该数据进行预处理数据PCA.功能。
计算距离,高斯方差和相似点
在预处理之后,徐计算距离D.(X一世那Xj)在每一对点之间X一世和Xj在X中,您可以使用使用的各种距离指标距离名称值对。默认情况下,徐使用标准的欧几里得度规。徐在随后的计算中使用距离度量的平方。
对于每一行一世x,徐计算标准偏差σ.一世所以这样困惑行一世等于困惑名称值对。根据型号高斯分布,如下所定义的困惑。作为van der毛根和恒生[1]描述,“数据点的相似性Xj数据点X一世是条件概率,
, 那X一世会选择Xj作为其邻居,如果邻居以与高斯为中心的高斯概率密度成比例地挑选X一世.对于附近的数据点,
相对较高,而对于广泛分离的数据点,
几乎是无限的(对于高斯的差异的合理值,σ.一世)。“
定义条件概率j鉴于一世作为
然后定义联合概率P.IJ.通过对称有条件概率:
| (1) |
在哪里N是X的行数。
分布仍然没有其标准偏差σ.一世根据该方面定义困惑名称值对。让P.一世表示给定数据点上所有其他数据点的条件概率分布X一世.分布的困惑是
在哪里H(P.一世是的香农熵P.一世:
困惑测量点的有效数量一世.徐执行二进制搜索σ.一世为每个点达到固定的困惑一世.
初始化嵌入和发散
要将X中的点嵌入到低维空间中,徐执行优化。徐试图最小化X和学生点数的模型高斯分布之间的kullback-leibler分配T.在低维空间中的点Y分布。
最小化过程开始于初始点Y.徐默认情况下创建点作为随机高斯分布点。您还可以自己创建这些积分并在其中包含它们“则”名称-值对的徐.徐然后计算y中每对点之间的相似性。
概率模型问:IJ.点之间距离的分布y一世和yj是
使用此定义和X的距离模型等式1, Kullback-Leibler散度的联合分布P.和问:是
对于这种定义的后果,见有用的非线性畸变.
kullback-Leibler分歧的梯度下降
为了最小化Kullback-Leibler散度“准确”算法使用修改后的渐变性缩减过程。相对于发散的y点的梯度是
其中规范化项
修改后的渐变缩减算法使用一些调整参数来尝试达到良好的局部最小值。
T-SNE的BARNES-HUT变化
为了加快t-SNE算法的速度并减少它的内存使用,徐给出了一个近似的优化方案。Barnes-Hut算法将邻近点分组在一起,以降低t-SNE优化步骤的复杂度和内存占用。Barnes-Hut算法是一个近似优化器,而不是一个精确优化器。有一个非负的调谐参数θ这影响了速度和准确性之间的权衡。更大的值'theta'给出更快但不太准确的优化结果。该算法对'theta'范围内的值(0.2,0.8)。
Barnes-Hut算法对低维空间中的点进行分组,并基于这些分组进行近似梯度下降。这个最初用于天体物理学的想法是,附近点的梯度是相似的,因此计算可以简化。
去找范德马顿[2].
T-SNE的特征
不能使用嵌入对新数据进行分类
因为t-SNE通常能很好地分离数据簇,所以t-SNE似乎可以对新的数据点进行分类。然而,t-SNE不能对新点进行分类。t-SNE嵌入是一种依赖于数据的非线性映射。若要在低维空间中嵌入新点,则不能将之前的嵌入用作映射。相反,再次运行整个算法。
性能取决于数据大小和算法
T-SNE可以花费有很多时间来处理数据。如果你有N数据点in.D.您想要映射到的维度y维度,然后
精确的T-SNE订单D.*N2操作。
Barnes-Hut T-SNE订单D.*N日志(N)* exp(维度(y)))操作。
所以对于大数据集,在哪里N大于1000左右,嵌入维度的位置y是2或3,Barnes-Hut算法可以比精确算法更快。
有用的非线性畸变
T-SNE将高尺度距离扭曲到扭曲的低维模数。因为学生的尾巴T.在低维空间分布,徐与高维空间相比,常使靠近的点移动得更近,而使远的点移动得更远,如下图所示。图中显示了高斯分布和学生分布T.在密度为0.25和0.025的点处的分布。高斯密度涉及高维距离和T.密度涉及低维距离。这T.与高斯密度相比,密度对应于近距离更近的点,并且远远较小。
t = linspace(0.5);y1 = normpdf(t,0,1);Y2 = TPDF(T,1);情节(T,Y1,'K't y2,'r')举行在x1 = fzero(@(x)normpdf(x,0,1)-0.25,[0,2]);x2 = fzero(@(x)tpdf(x,1)-0.25,[0,2]);z1 = fzero(@(x)normpdf(x,0,1)-0.025,[0,5]);z2 = fzero(@(x)tpdf(x,1)-0.025,[0.5]);图([0,x1],[0.25,0.25],'k-。')情节([0,z2]、[0.025,0.025],'k-。')情节(x1, x1, [0, 0.25],“g -”(x2, x2), [0, 0.25],“g -”绘图([z1,z1],[0,0.025],“g -”,[z2,z2],[0,0.025],“g -”)文本(1.1,.25,'关闭点在低d'中更近)文本(2.4,.05,Far点在low-D中更远)传说(“高斯(0,1)”那'Student t (df = 1)')包含('X') ylabel (“密度”) 标题('高斯(0,1)和学生t(df = 1)'的密度)举行从
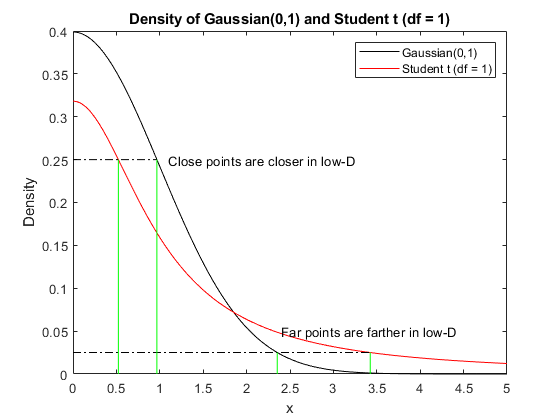
当它适用时,这种失真是有帮助的。在诸如高斯方差高的情况下,它不适用于高斯峰值并使分布变平。在这种情况下,徐可以将靠近的点移动到比原来空间更远的地方。为了实现有益的扭曲,
设置
'verbose'名称 - 值对2.调整
'困惑'名称 - 值对,因此报告的差异范围不远1,平均方差近1.
如果你能达到这个方差范围,那么图表就会应用,并且徐失真有用。
有效的调音方法徐,见Wattenberg,Viégas和约翰逊[4].
参考
[1] Van der Maaten,Laurens和Geoffrey Hinton。“使用数据可视化数据T.新力。”J.机器学习研究9,2008,第2579-2605页。
[2] van der Maaten,Laurens。Barnes-hut-sne.arXiv: 1301.3342 (cs。LG),2013年。
[3]雅各布,罗伯特A.“通过学习率适应提高融合率。”神经网络2、《中国科学院大学学报(自然科学版)》,1998。
[4] Wattenberg,Martin,FernandaViégas和伊恩约翰逊。“如何有效地使用T-SNE。”蒸馏,2016年。可以在如何有效使用t-SNE.
相关例子
更多关于
你也可以从以下列表中选择一个网站:
