基于卷积神经网络的文本数据分类
这个例子展示了如何使用卷积神经网络对文本数据进行分类。
要使用卷积对文本数据进行分类,必须将文本数据转换为图像。为此,请填充或截断观测值,使其具有恒定的长度s并将文档转换为长度为的单词向量序列C使用单词嵌入。然后您可以将文档表示为1-by-s-借-C图像(高度为1,宽度为1的图像s,C频道)。
要将CSV文件中的文本数据转换为图像,请创建tabularTextDatastore对象。转换从tabularTextDatastore对象到图像的深度学习通过调用变换具有自定义转换函数transformTextData函数(列在示例末尾)获取从数据存储和预训练单词嵌入中读取的数据,并将每个观察值转换为单词向量数组。
此示例使用不同宽度的一维卷积滤波器训练网络。每个滤波器的宽度对应于滤波器可以看到的字数(n-gram长度)。该网络具有卷积层的多个分支,因此可以使用不同的n-gram长度。
加载预训练词嵌入
加载预先训练的fastText单词嵌入。此功能需要文本分析工具箱™模型对于fastText English,160亿标记词嵌入万博1manbetx支持包。如果未安装此支持包,则该功能将提供下载链接。
emb=fastTextWordEmbedding;
加载数据
从中的数据创建表格文本数据存储factoryReports.csv. 从数据库中读取数据“说明”和“类别”仅列。
文件名火车=“factoryReports.csv”;文本名称=“说明”;标签名=“类别”;ttdsTrain=tablertextdatastore(filenameTrain,“SelectedVariableNames”,[textName labelName]);
预览数据存储。
ttdsTrain.ReadSize=8;预览(ttdsTrain)
ans=8×2表UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU{'项目偶尔会卡在扫描仪线轴中。}{'机械故障'}{'装配机活塞发出巨大的卡嗒卡嗒声和砰砰声。}{'机械故障'}{“启动设备时电源切断”。}{“电子故障”}{“装配机中的电容器爆炸”。}{“电子故障”}{“混合器跳闸了保险丝”。}{“电子故障”}{“施工剂中的爆裂管正在喷射冷却剂”。}{“泄漏”}{“混合器中的保险丝熔断”。}{“电子故障”}{‘东西继续从传送带上掉下来。}{‘机械故障}
创建一个自定义转换函数,将从数据存储读取的数据转换为包含预测器和响应的表transformTextData函数(在示例末尾列出)获取从tabularTextDatastore对象,并返回预测值和响应的表。预测值为1-x-序列长度-借-C由单词嵌入给出的单词向量数组教统局哪里C是嵌入维度。响应是中类的分类标签类名.
使用从培训数据中读取标签阅读标签函数,并查找唯一的类名。
labels=readLabels(ttdsTrain,labelName);classNames=unique(labels);numObservations=numel(labels);
使用transformTextData函数并指定序列长度为14。
sequenceLength = 14;tdsTrain = transform(ttdsTrain, @(data) transformTextData(data,sequenceLength,emb,classNames))
tdsTrain = TransformedDatastore属性:UnderlyingDatastore:TabularTextDatastore] 万博1manbetxSupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq" "png" "jpg" "jpeg" "tif" "tiff" "wav" "flac" "ogg" "mp4" "m4a"] Transforms:{@(数据)transformTextData(data,sequenceLength,emb,classNames)} IncludeInfo: 0
预览转换后的数据存储。预测值为1-x-s-借-C数组,在哪里s是序列的长度和长度C是特征的数量(嵌入维度)。响应是分类标签。
预览(TDS)
ans=8×2表预测器响应_________________ __________________ {1×14×300 single}机械故障{1×14×300 single}机械故障{1×14×300 single}电子故障{1×14×300 single}电子故障{1×14×300 single}电子故障{1×14×300 single}泄漏{1×14×300 single}电子故障{1×14×300 single}机械故障
定义网络架构
定义分类任务的网络架构。
以下步骤描述了网络体系结构。
指定1-x的输入大小-s-借-C哪里s是序列的长度和长度C是特征数(嵌入维度)。
对于长度为n-gram的2、3、4和5,创建包含卷积层、批处理正常化层、ReLU层、dropout层和max pooling层的层块。
对于每个块,指定大小为1 × -的200个卷积滤波器N以及大小为1 × -的区域池s哪里N是n克长度。
将输入层连接到每个块,并使用深度连接层连接块的输出。
要对输出进行分类,请包括具有输出大小的完全连接层K、softmax层和分类层,其中K是班级的数量。
首先,在层数组中,指定输入层、Unigram的第一个块、深度连接层、完全连接层、softmax层和分类层。
numFeatures=emb.Dimension;inputSize=[1 sequenceLength numFeatures];NumFilter=200;NgramLength=[2 3 4 5];numBlocks=numel(NgramLength);NumClass=numel(类名);
创建包含输入层的图层图。将“规格化”选项设置为“没有”以及要添加的图层名称“输入”.
图层=imageInputLayer(inputSize,“正常化”,“没有”,“姓名”,“输入”);lgraph=层图(层);
对于每一个n-gram长度,创建一个卷积、批量标准化、ReLU、dropout和max pooling层块。将每个块连接到输入层。
对于j=1:numBlocks N=ngramlength(j);block=[卷积2dlayer([1 N],numFilters,“姓名”,“conv”+N,,“填充”,“相同”)批处理规范化层(“姓名”,“bn”+N) 雷卢耶(“姓名”,“relu”+N) dropoutLayer(0.2,“姓名”,“下降”+N) MaxPoolig2dLayer([1 sequenceLength],“姓名”,“最大值”+N) ];lgraph=addLayers(lgraph,block);lgraph=connectLayers(lgraph,“输入”,“conv”+ N);结束
在绘图中查看网络体系结构。
图形绘图(lgraph)标题(“网络架构”)
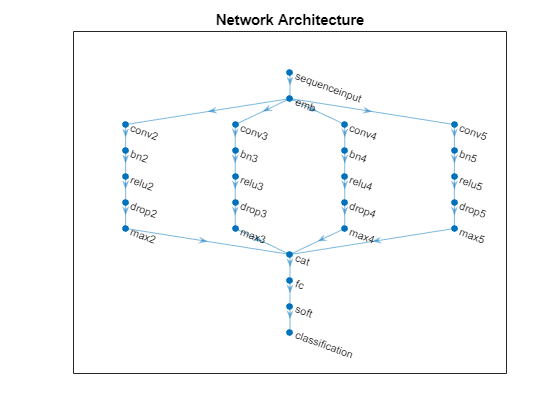
添加深度连接层、完全连接层、softmax层和分类层。
层=[depthConcatenationLayer(numBlocks,“姓名”,“深度”) fullyConnectedLayer (numClasses“姓名”,“fc”)软MaxLayer(“姓名”,“软的”) classificationLayer (“姓名”,“分类”)]; lgraph=添加层(lgraph,层);图形绘图(lgraph)标题(“网络架构”)
将最大池层连接到深度连接层,并在绘图中查看最终的网络体系结构。
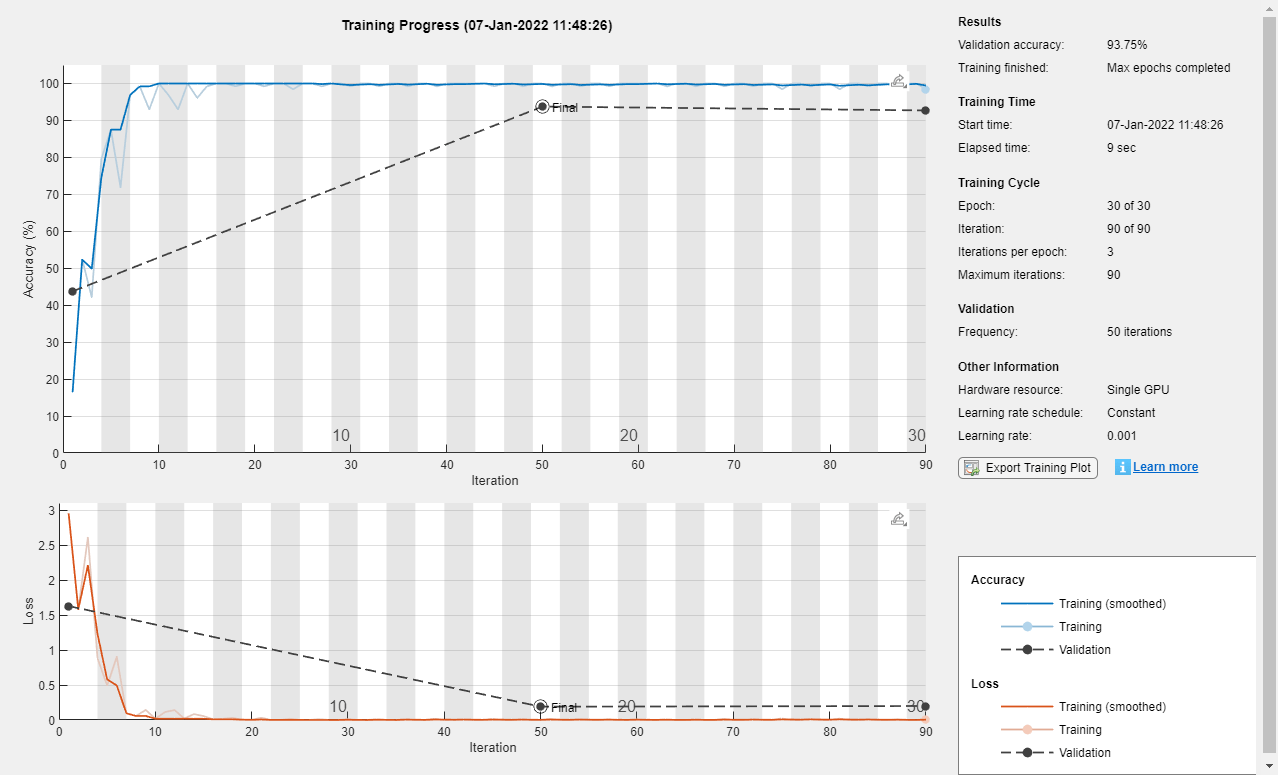
对于j = 1:numBlocks N = ngramlength (j);lgraph = connectLayers (lgraph,“最大值”+N,,“深度/深度”+j) );结束图形绘图(lgraph)标题(“网络架构”)
列车网络
指定培训选项:
列车的最小批量为128。
不要洗牌数据,因为数据存储不可洗牌。
显示训练进度图并抑制详细输出。
miniBatchSize=128;numIterationsPerEpoch=floor(婚礼服务/miniBatchSize);options=trainingOptions(“亚当”,...“MiniBatchSize”,小批量,...“洗牌”,“从来没有”,...“情节”,“培训进度”,...“冗长”、假);
训练网络使用列车网络功能。
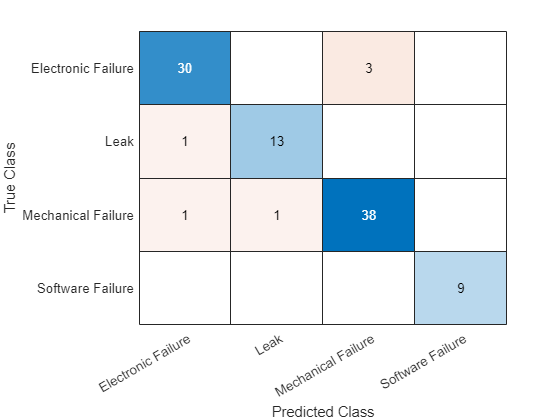
net=列车网络(TDSTREANT、LGRAPHE、选项);

使用新数据进行预测
对三个新报告的事件类型进行分类。创建包含新报告的字符串数组。
reportsNew = [“冷却液在分拣机下方聚集。”“分类器在启动时烧断保险丝。”“从组装器里传出很响的咔哒声。”];
使用预处理步骤作为训练文档对文本数据进行预处理。
XNew=预处理文本(reportsNew、sequenceLength、emb);
用训练好的LSTM网络对新的序列进行分类。
labelsNew=分类(净,XNew)
新标签=3×1范畴泄漏电子故障机械故障
阅读标签功能
这个阅读标签函数创建tabularTextDatastore对象ttds并从标签名专栏。
函数labels=readLabels(ttds,labelName)ttdsNew=copy(ttds);ttdsNew.SelectedVariableNames=labelName;tbl=readall(ttdsNew);labels=tbl.(labelName);结束
转换文本数据函数
这个transformTextData函数获取从数据库中读取的数据tabularTextDatastore对象,并返回预测值和响应的表。预测值为1-x-序列长度-借-C由单词嵌入给出的单词向量数组教统局哪里C是嵌入维度。响应是中类的分类标签类名.
函数dataTransformed=transformTextData(数据、序列长度、emb、类名)%预处理文档。textData=数据{,1};%预处理文本dataTransformed = preprocessText (textData、sequenceLength emb);%阅读标签。标签=数据{:,2};响应=分类(标签,类名);%将数据转换为表。dataTransformed.Responses=响应;结束
预处理文本函数
这个预处理文本数据函数获取文本数据、序列长度和单词嵌入,并执行以下步骤:
标记文本。
将文本转换为小写。
使用嵌入将文档转换为指定长度的字向量序列。
重塑输入到网络中的字向量序列。
函数tbl=预处理文本(文本数据,序列长度,emb)文档=标记化文档(文本数据);文档=较低(文档);%将文档转换为嵌入尺寸按序列长度按1的图像。预测值=文件序列(emb、文件、,“长度”, sequenceLength);%重塑图像,使其尺寸为1×1序列长度嵌入尺寸。预测值=cellfun(@(X)排列(X,[3 2 1]),预测值,“UniformOutput”、假);台=表;资源描述。预测=预测;结束
另见
fastTextWordEmbedding|wordcloud|wordEmbedding|layerGraph(深度学习工具箱)|convolution2dLayer(深度学习工具箱)|批处理规范化层(深度学习工具箱)|trainingOptions(深度学习工具箱)|列车网络(深度学习工具箱)|DOC2序列|tokenizedDocument
相关的话题
您还可以从以下列表中选择网站:
