主要内容
可视化LDA主题相关性
这个示例展示了如何在Latent Dirichlet Allocation (LDA)主题模型中分析主题之间的相关性。
潜在Dirichlet分配(LDA)模型是一种主题模型,它发现文档集合中的底层主题,并推断主题中的单词概率。每个主题的单词概率向量描述了主题的特征。使用每个主题的单词概率,您可以识别主题之间的相关性。
负载LDA模型
加载LDA模型factoryReportsLDAModel它使用详细描述不同故障事件的工厂报告数据集进行培训。有关如何使LDA模型适合文本数据集合的示例,请参见使用主题模型分析文本数据.
负载factoryReportsLDAModelmdl
MDL = ldaModel与属性:NumTopics:7 WordConcentration:1 TopicConcentration:0.5755 CorpusTopicProbabilities:[0.1587 0.1573 0.1551 0.1534 0.1340 ...] DocumentTopicProbabilities:[480x7双] TopicWordProbabilities:[158x7双]词汇:[ “项目”, “偶尔”“GET“......”主题订单:'初始合身概率'fitinfo:[1x1 struct]
使用词汇云将主题形象化。
numTopics = mdl.NumTopics;图t = tiledlayout(“流”);标题(t)“LDA的话题”)为i = 1:numTopics nexttile wordcloud(mdl,i);标题(“话题 ”+ i)结束

可视化主题相关性
方法计算主题之间的相关性corrcoef函数,以LDA模型主题词概率作为输入。
相关= corrcoef (mdl.TopicWordProbabilities);
查看热贴图中的相关性,并将其顶部三个单词标记每个主题。为了防止热图突出显示主题之间的智能相关性,并且从相关性中减去身份矩阵。
对于每个话题,找出前三个词。
numTopics = mdl.NumTopics;为i = 1:numTopics top = topkwords(mdl,3,i);topWords (i) =加入(顶部。词,“,”);结束
用的热图函数。
figure heatmap(correlation - eye(numTopics)),...XDisplayLabels = topWords,...YDisplayLabels = topWords)标题(“LDA主题相关性”)Xlabel(“主题”)ylabel(“主题”)
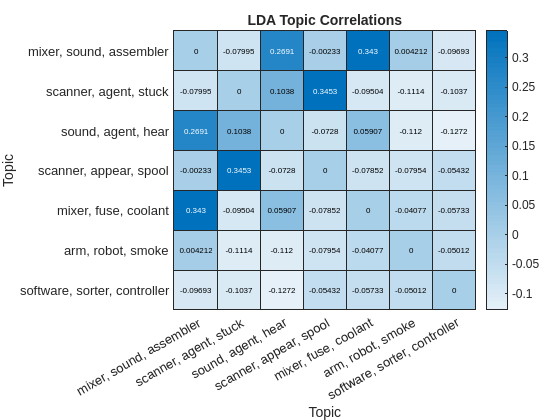
对于每个主题,找出相关性最强的主题,并将相关系数对应的对显示在表格中。
[topcorrelations,topcorreledtopics] = max(相关 - 眼睛(numtopics));TBL =表;tbl.topicIndex =(1:numtopics)';tbl.topic = topwords';tbl.topcorrelatedtopicIndex = topcorrelatedtopics';tbl.topcorreelatedtopic =顶字(TopcorrelateTopics)';TBL.CorrelationCoeffITE = TOPCORRELATIONS'
台=7×5表TopicIndex主题TopcorreelatedTopicIndex Topcorlaindtopic相关性CuerytationChoy ________________________________________________________________________________________maz________________ ________________________ ______________________________________________________________________________ _________________________听到“1”搅拌机,声音,汇编器“0.26909 4”扫描仪,出现,阀芯“2”扫描仪,代理,卡住“0.34526 5”搅拌机,保险丝,冷却液“1”搅拌机,声音,装配器“0.34304 6”手臂,机器人,烟雾“1”搅拌机,声音,汇编器“0.0042125 7”软件,分拣机,控制器“7”软件,分拣机,控制器“0
另请参阅
令人生畏的鳕文|fitlda|ldaModel|wordcloud
相关话题
你也可以从以下列表中选择一个网站:
