基于SSD深度学习的目标检测
这个例子展示了如何训练一个单镜头检测器(SSD)。
概述
深度学习是一种强大的机器学习技术,可以自动学习检测任务所需的图像特征。有几种使用深度学习的对象检测技术,如Faster R-CNN、You Only Look Once (YOLO v2)和SSD。这个例子训练SSD车辆检测器使用trainSSDObjectDetector函数。有关更多信息,请参见目标检测.
下载Pretrained探测器
下载一个预先训练过的检测器,以避免等待训练完成。如果你想训练探测器,设置doTraining变量为true。
doTraining = false;如果~ doTraining & & ~存在(“ssdResNet50VehicleExample_20a.mat”,“文件”) disp ('下载预训练检测器(44 MB)…');pretrainedURL =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/vision/data/ssdResNet50VehicleExample_20a.mat”; 韦伯萨夫(“ssdResNet50VehicleExample_20a.mat”,训练前;结束
下载预训练检测器(44mb)…
加载数据集
本例使用一个包含295张图像的小型车辆数据集。这些图像中有许多来自加州理工学院汽车1999年和2001年的数据集,可以在加州理工学院计算视觉中心获得网站,由Pietro Perona创作并获得许可使用。每个图像包含一个或两个已标记的车辆实例。一个小的数据集对于探索SSD训练过程是有用的,但在实践中,需要更多的标记图像来训练一个鲁棒检测器。
解压缩vehicleDatasetImages.zipdata =负载(“vehicleDatasetGroundTruth.mat”);vehicleDataset = data.vehicleDataset;
训练数据存储在一个表中。第一列包含图像文件的路径。其余的列包含车辆的ROI标签。显示数据的前几行。
vehicleDataset (1:4,:)
ans =4×2表该文件名文件名名文件名名为车辆名名名名名为车辆名名名名为车辆名名名为UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUleimages/image_00004.jpg'}{[124 112 38 36]}
将数据集分割为用于训练检测器的训练集和用于评估检测器的测试集。选择60%的数据进行训练。剩下的用于评估。
rng (0);shuffledIndices = randperm(高度(vehicleDataset));idx = floor(0.6 * length(shuffledIndices));trainingData = vehicleDataset (shuffledIndices (1: idx):);testData = vehicleDataset (shuffledIndices (idx + 1:结束):);
使用imageDatastore和Boxlabeldata商店在培训和评估过程中加载图像和标签数据。
imdsTrain=图像数据存储(训练数据{:,“imageFilename”});bldsTrain = boxLabelDatastore (trainingData (:,“汽车”));imdsTest = imageDatastore (testData {:,“imageFilename”});bldsTest = boxLabelDatastore (testData (:,“汽车”));
组合图像和框标签数据存储。
trainingData =结合(imdsTrain bldsTrain);testData = combine(imdsTest, bldsTest);
显示其中一个训练图像和框标签。
data=read(trainingData);I=data{1};bbox=data{2};annotatedImage=insertShape(I,“矩形”, bbox);annotatedImage = imresize (annotatedImage 2);图imshow (annotatedImage)

创建SSD对象检测网络
SSD对象检测网络可以认为有两个子网络。首先是特征提取网络,然后是检测网络。
特征提取网络通常是预先训练的CNN(见预先训练的深度神经网络(深度学习工具箱)更多的细节)。本例使用ResNet-50进行特征提取。根据应用需求,还可以使用其他预先训练过的网络,如MobileNet v2或ResNet-18。与特征提取网络相比,检测子网络是一个较小的CNN,由几个卷积层和针对SSD的层组成。
使用ssdLayers功能,自动将预先训练好的ResNet-50网络修改为SSD对象检测网络。ssdLayers要求您指定几个参数化SSD网络的输入,包括网络输入大小和类数。在选择网络输入大小时,考虑训练图像的大小,以及在选定大小上处理数据所产生的计算成本。可行时,选择一个接近训练图像大小的网络输入大小。然而,为了降低运行该示例的计算成本,将网络输入大小选择为[300 3]。在训练中,,trainSSDObjectDetector根据网络输入大小自动调整训练图像的大小。
inputSize = [300 300 3];
定义要检测的对象类的数量。
numClasses =宽度(vehicleDataset) 1;
创建SSD对象检测网络
lgraph = ssdLayers(inputSize, numClasses,“resnet50”);
您可以使用analyzeNetwork或维eepNetworkDesigner来自深度学习工具箱™。注意,您还可以逐层创建自定义SSD网络。有关更多信息,请参见创建SSD对象检测网络.
数据扩充
数据扩充用于通过在训练期间随机变换原始数据来提高网络精度。通过使用数据扩充,您可以向训练数据添加更多种类,而无需实际增加标记训练样本的数量。使用变换通过。来增加训练数据
水平随机翻转图像和关联的框标签。
随机缩放图像,相关的盒子标签。
抖动图像颜色。
请注意,数据扩充不应用于测试数据。理想情况下,测试数据应该是原始数据的代表,并且保持不变,以便进行无偏评估。
augmentedTrainingData=转换(trainingData,@augmentData);
通过多次阅读相同的图像来可视化增强训练数据。
augmentedData =细胞(4,1);为k = 1:4 data = read(augmentedTrainingData);augmentedData {k} = insertShape(数据{1},“矩形”、数据{2});重置(augmentedTrainingData);结束图蒙太奇(augmentedData,“BorderSize”,10)

训练数据预处理
对增强后的训练数据进行预处理,为训练做准备。
preprocessedTrainingData =变换(augmentedTrainingData @(数据)preprocessData(数据、inputSize));
读取预处理的训练数据。
data =阅读(preprocessedTrainingData);
显示图像和边框。
我={1}数据;bbox ={2}数据;annotatedImage = insertShape(我“矩形”, bbox);annotatedImage = imresize (annotatedImage 2);图imshow (annotatedImage)

训练SSD对象检测器
使用trainingOptions指定网络培训选项。设置“CheckpointPath”到一个临时地点。这样可以在培训过程中保存部分经过培训的探测器。如果培训被中断,例如断电或系统故障,您可以从保存的检查点恢复培训。
选择= trainingOptions (“个”,...“MiniBatchSize”, 16岁,....“InitialLearnRate”,1e-1,...“LearnRateSchedule”,“分段”,...“LearnRateDropPeriod”30岁的...“LearnRateDropFactor”, 0.8,...“MaxEpochs”, 300,...“VerboseFrequency”, 50,...“CheckpointPath”tempdir,...“洗牌”,“every-epoch”);
使用trainSSDObjectDetector功能训练SSD对象检测器doTraining为true。否则,加载预训练的网络。
如果doTraining%训练SSD探测器。[detector, info] = trainSSDObjectDetector(preprocessedTrainingData,lgraph,options); / /设置检测器其他的%负载预训练检测器为例。pretrained =负载(“ssdResNet50VehicleExample_20a.mat”); 检测器=预训练检测器;结束
此示例在NVIDIA上得到验证™ Titan X GPU,12 GB内存。如果您的GPU内存较少,可能会耗尽内存。如果发生这种情况,请降低'MiniBatchSize的使用trainingOptions函数。使用这个设置培训这个网络大约花了2个小时。训练时间取决于你使用的硬件。
作为一个快速测试,在一个测试图像上运行检测器。
data =阅读(testData);我={1 1}数据;我= imresize(我inputSize (1:2));[bboxes,分数]=检测(探测器,我,“门槛”, 0.4);
显示结果。
I=插入对象注释(I,“矩形”bboxes,分数);图imshow(我)

使用测试集评估检测器
评估训练的目标检测器在一组大的图像,以衡量性能。计算机视觉工具箱™提供对象检测器评估功能,以测量常见的指标,如平均精度(evaluateDetectionPrecision)并记录平均未命中率(evaluateDetectionMissRate).对于本例,使用平均精度度量来评估性能。平均精度提供了一个单一的数字,该数字包含了探测器进行正确分类的能力(精度)和检测器找到所有相关对象的能力(回忆).
对测试数据应用与训练数据相同的预处理转换。注意,数据扩充并不应用于测试数据。测试数据应能代表原始数据,且不作任何修改,以便进行公正的评估。
preprocessedTestData=转换(testData,@(data)preprocessData(data,inputSize));
在所有测试图像上运行检测器。
detectionResults = detect(检测器,preprocestestdata,“门槛”, 0.4);
评估对象探测器使用平均精度度量。
[ap,召回率,精密度]=评估检测精密度(检测结果,预处理检测数据);
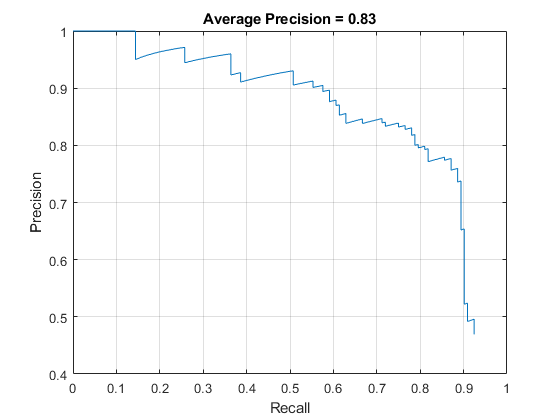
精度/召回率(PR)曲线强调了检测器在不同召回率水平下的精度。理想情况下,在所有召回率水平下,精度应为1。使用更多数据有助于提高平均精度,但可能需要更多的训练时间绘制PR曲线。
图表(召回率、精度)xlabel(“召回”) ylabel (“精确性”网格)在标题(sprintf ('平均精度= %.2f'据美联社)),
代码生成
一旦检测器被训练和评估,您就可以为ssdObjectDetector使用GPU编码器™. 有关详细信息,请参阅基于单镜头多盒检测器的目标检测代码生成的例子。
万博1manbetx辅助功能
函数B = augmentData (A)%应用随机水平翻转和随机X/Y缩放。盒子,%如果重叠超过0.25,则将剪裁边界外的缩放。此外,抖动图像颜色。B =细胞(大小(A));我= {1};深圳=大小(I);如果numel(sz)==3 && sz(3) ==3 I = jitterColorHSV(I,...“对比”,0.2,...“颜色”0,...“饱和”,0.1,...'亮度', 0.2);结束%随机翻转和缩放图像。tform=随机仿射2d(“外部选择”符合事实的“规模”1.1 [1]);tform溃败= affineOutputView(深圳,“BoundsStyle”,“中心输出”);B {1} = imwarp (tform,我“OutputView”,溃败);如有需要,对盒子进行消毒。A{2} = helperSanitizeBoxes(A{2}, sz);对方框应用相同的转换。[B{2},索引]=bboxwarp(A{2},tform,rout,“重叠阈值”, 0.25);B{3} ={3}(指标);%仅当通过扭曲移除所有框时,才返回原始数据。如果isempty(indices) B = A;结束结束函数数据=预处理数据(数据,targetSize)%调整图像和包围框的大小为targetSize。sz=大小(数据{1}[12]);比例=目标尺寸(1:2)。/sz;data{1}=imresize(data{1},targetSize(1:2));如有需要,对盒子进行消毒。数据{2}= helperSanitizeBoxes(数据{2},sz);%调整框的大小。数据{2}=bboxresize(数据{2},比例);结束
参考文献
[1] Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng Yang Fu, Alexander C. Berg。“SSD:单次发射多盒探测器。”第十四届欧洲计算机视觉大会,ECCV 2016。施普林格1 - 2016。
另请参阅
应用程序
- 深层网络设计师(深度学习工具箱)
功能
结合|估计锚箱|evaluateDetectionPrecision|读|变换|analyzeNetwork(深度学习工具箱)
对象
相关的话题
- 用于目标检测的锚盒
- 根据训练数据估计锚盒
- 使用深度网络设计师进行迁移学习(深度学习工具箱)
- 使用深度学习开始对象检测
你也可以从以下列表中选择一个网站:
