validatemodel
质量信用计分卡模型进行验证
语法
描述
例子
信用计分卡模型进行验证
创建一个creditscorecard对象使用CreditCardData.mat文件加载数据(使用一个数据集从Refaat 2011)。
负载CreditCardDatasc = creditscorecard(数据,“IDVar”,“CustID”)
sc = creditscorecard属性:GoodLabel: 0 ResponseVar:“地位”WeightsVar:“VarNames: {CustID的‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance UtilRate的“地位”}NumericPredictors: {‘CustAge’‘TmAtAddress’‘CustIncome’‘TmWBank’‘AMBalance’‘UtilRate} CategoricalPredictors: {“ResStatus”“EmpStatus”“OtherCC”} BinMissingData: 0 IDVar:“CustID”PredictorVars: {‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance’‘UtilRate}数据:[1200 x11表)
使用默认选项执行自动装箱。默认情况下,autobinning使用单调算法。
sc = autobinning (sc);
合适的模型。
sc = fitmodel (sc);
1。添加CustIncome、偏差= 1490.8527 Chi2Stat = 32.588614, PValue = 1.1387992 e-08 2。添加TmWBank、偏差= 1467.1415 Chi2Stat = 23.711203, PValue = 1.1192909 e-06 3。添加AMBalance、偏差= 1455.5715 Chi2Stat = 11.569967, PValue = 0.00067025601 - 4。添加EmpStatus、偏差= 1447.3451 Chi2Stat = 8.2264038, PValue = 0.0041285257 5。添加CustAge、偏差= 1441.994 Chi2Stat = 5.3511754, PValue = 0.020708306 6。添加ResStatus、偏差= 1437.8756 Chi2Stat = 4.118404, PValue = 0.042419078 7。添加OtherCC、偏差= 1433.707 Chi2Stat = 4.1686018, PValue = 0.041179769广义线性回归模型:分对数(状态)~ 1 + CustAge + ResStatus + EmpStatus + CustIncome + TmWBank + OtherCC + AMBalance =二项分布估计系数:估计SE tStat PValue说______ __________(拦截)0.70239 0.064001 10.975 5.0538即使CustAge EmpStatus ResStatus 0.014687 0.60833 0.24932 2.44 1.377 0.65272 2.1097 0.034888 0.88565 0.293 3.0227 0.0025055 CustIncome TmWBank 0.0013179 0.70164 0.21844 3.2121 1.1074 0.23271 4.7589 1.9464 e-06 OtherCC AMBalance 0.039696 1.0883 0.52912 2.0569 1.045 0.32214 3.2439 0.0011792 1200观察,1192错误自由度色散:1 x ^ 2-statistic与常数模型:89.7,p = 1.4 e-16
们点格式。
sc = formatpoints (sc,“PointsOddsAndPDO”,500,2,50);
得分数据。
成绩=分数(sc);
验证信用计分卡模型通过生成帽,中华民国,KS的情节。
(统计、T) = validatemodel (sc,“阴谋”,{“帽子”,“中华民国”,“KS”});
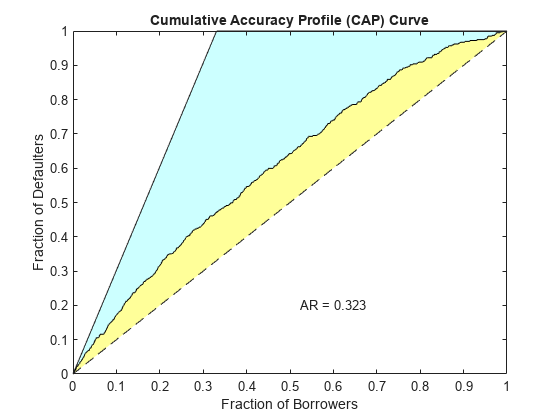
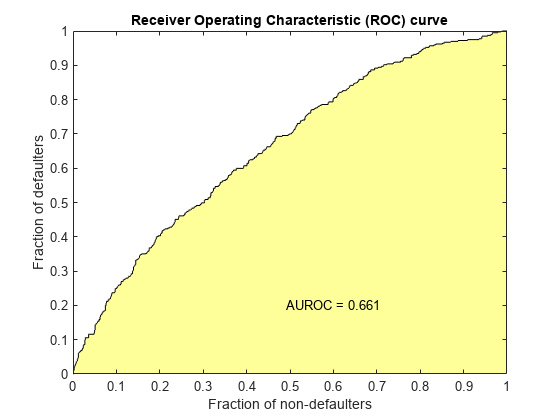
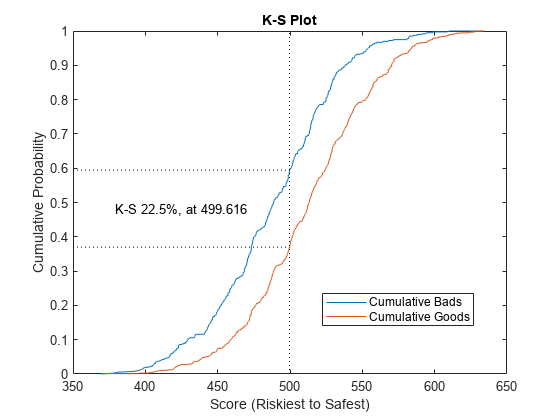
disp(统计)
测量值________________________ _________ 0.32258{的精度比}{ROC曲线下面积的}0.66129 {“KS统计”}0.2246 499.62 {“k值”}
disp (T (1:15)):
分数ProbDefault TrueBads FalseBads TrueGoods FalseGoods敏感性FalseAlarm PctObs ______⒈替__________ ________ ___________ __________ __________ 369.54 - 0.75313 0 0 0.0012453 0.00083333 378.19 0.73016 1 1 1 802 397 802 396 0.0025189 0.0012453 0.0016667 380.28 0.72444 - 2 1 802 395 3 1 802 394 0.0075567 0.0050378 0.0012453 0.0025 391.49 0.69234 0.0012453 0.0033333 395.57 0.68017 - 4 1 802 393 0.010076 0.0012453 0.0041667 396.14 0.67846 - 4 2 5 801 393 0.010076 0.0024907 0.005 396.45 0.67752 801 392 0.012594 0.0024907 0.0058333 398.61 0.67094 6 2 801 391 0.015113 0.0024907 0.0066667 398.68 0.67072 801 390 0.017632 0.0024907 0.0075 401.33 0.66255 389 801 0.020151 0.0024907 0.0083333 402.66 0.65842 389 800 0.020151 0.003736 0.0091667 404.25 0.65346 9 3 800 388 0.02267 0.003736 0.01 404.73 0.65193 9 4 799 388 0.02267 0.0049813 0.010833 405.53 0.64941 11 4 799 386 0.027708 0.0049813 0.0125 405.7 0.64887 11 5 798 386 0.027708 0.0062267 0.013333
信用评分卡模型权重进行验证
使用CreditCardData.mat文件加载数据(dataWeights),其中包含一个列(RowWeights)的权重(使用数据集从Refaat 2011)。
负载CreditCardData
创建一个creditscorecard使用可选的对象名称-值对的理由“WeightsVar”。
sc = creditscorecard (dataWeights,“IDVar”,“CustID”,“WeightsVar”,“RowWeights”)
sc = creditscorecard属性:GoodLabel: 0 ResponseVar:“地位”WeightsVar:“RowWeights”VarNames: {CustID的‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance’‘UtilRate RowWeights的“地位”}NumericPredictors: {‘CustAge’‘TmAtAddress’‘CustIncome’‘TmWBank’‘AMBalance’‘UtilRate} CategoricalPredictors: {“ResStatus”“EmpStatus”“OtherCC”} BinMissingData: 0 IDVar:“CustID”PredictorVars: {‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance’‘UtilRate}数据:[1200 x12表)
执行自动装箱。
sc = autobinning (sc)
sc = creditscorecard属性:GoodLabel: 0 ResponseVar:“地位”WeightsVar:“RowWeights”VarNames: {CustID的‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance’‘UtilRate RowWeights的“地位”}NumericPredictors: {‘CustAge’‘TmAtAddress’‘CustIncome’‘TmWBank’‘AMBalance’‘UtilRate} CategoricalPredictors: {“ResStatus”“EmpStatus”“OtherCC”} BinMissingData: 0 IDVar:“CustID”PredictorVars: {‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance’‘UtilRate}数据:[1200 x12表)
合适的模型。
sc = fitmodel (sc);
1。添加CustIncome、偏差= 764.3187 Chi2Stat = 15.81927, PValue = 6.968927 e-05 2。添加TmWBank、偏差= 751.0215 Chi2Stat = 13.29726, PValue = 0.0002657942 3。添加AMBalance、偏差= 743.7581 Chi2Stat = 7.263384, PValue = 0.007037455广义线性回归模型:分对数(地位)~ 1 + CustIncome + TmWBank + AMBalance =二项分布估计系数:估计SE tStat PValue说______ __________(拦截)0.70642 0.088702 7.964 1.6653 e15汽油CustIncome 1.0268 0.25758 3.9862 6.7132 e-05 TmWBank AMBalance 0.0004543 1.0973 0.31294 3.5063 1.0039 0.37576 2.6717 0.0075464 1200观察,1196错误自由度色散:1 x ^ 2-statistic与常数模型:36.4,p = 6.22 e-08
们点格式。
sc = formatpoints (sc,“PointsOddsAndPDO”,500,2,50);
得分数据。
成绩=分数(sc);
验证信用计分卡模型通过生成帽,中华民国,KS的情节。当可选名称-值对的论点“WeightsVar”用于指定观察(样本)重量,T表使用统计数据、金额和累计金额加权计数。
(统计、T) = validatemodel (sc,“阴谋”,{“帽子”,“中华民国”,“KS”});



统计数据
统计=4×2表测量值________________________ _________ 0.28972{的精度比}{ROC曲线下面积的}0.64486 {“KS统计”}0.23215 505.41 {“k值”}
T (1:10,:)
ans =10×9表分数ProbDefault TrueBads FalseBads TrueGoods FalseGoods敏感性FalseAlarm PctObs ______⒈替__________ ________ ___________ __________ _____ 0 0 401.34 0.66253 1.0788 411.95 201.95 0.0053135 0.0017542 407.59 0.64289 4.8363 1.2768 410.67 198.19 0.023821 0.0030995 0.0099405 413.79 0.62292 6.9469 4.6942 407.25 196.08 0.034216 0.011395 0.018929 420.04 0.60236 18.459 9.3899 402.56 184.57 0.090918 0.022794 0.045285 437.27 0.544 18.459 10.514 401.43 184.57 0.090918 0.025523 0.047113 442.83 0.52481 18.973 12.794 399.15 184.06 0.093448 0.031057 0.051655 446.19 0.51319 22.396 14.15 397.8 180.64 0.11031 0.034349 0.059426 449.08 0.50317 24.325 14.405 397.54 178.71 0.11981 0.034968 0.062978 449.73 0.50095 28.246 18.049 393.9 174.78 0.13912 0.043813 0.075279 452.44 0.49153 31.511 23.565 388.38 171.52 0.1552 0.057204 0.089557
信用评分卡模型进行验证当使用“BinMissingData”选项
这个例子描述的任务时丢失的数据点“BinMissingData”选项设置为真正的验证数据,相应的计算模型。
预测有缺失数据训练集的一个显式的本
<失踪>在最后的计分卡对应点。计算这些点的证据的效力(悲哀)值<失踪>本和物流模型系数。为了得分,这些点被分配到缺失值超出范围的值,最后得分是用于计算模型验证数据validatemodel。训练集的预测没有缺失的数据没有
<失踪>本,因此可以从训练数据估计没有悲哀。默认情况下,将点失踪,超出范围值南,这导致的南运行时分数。没有明确的预测<失踪>本,使用名称-值参数“失踪”在formatpoints指出应该如何治疗得分缺失数据的目的。最后的得分是用于计算模型验证数据validatemodel。
创建一个creditscorecard对象使用CreditCardData.mat文件加载dataMissing用缺失值。
负载CreditCardData.mat头(dataMissing, 5)
CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate ____ ____地位………………_____ _____ _____ ________ ________ 53 62 <定义>未知50000 55是的1055.9 - 0.22 0 2 61 22业主雇佣52000 25是的1161.6 - 0.24 0 3 47 30租户使用37000 61没有877.23 - 0.29 0 4南75业主雇佣了53000 20是的157.37 - 0.08 0 5 68 56家老板雇用了53000名14是的561.84 - 0.11 0
使用creditscorecard名称-值的参数“BinMissingData”设置为真正的本失踪的数字或分类数据在一个单独的垃圾箱。应用自动装箱。
sc = creditscorecard (dataMissing,“IDVar”,“CustID”,“BinMissingData”,真正的);sc = autobinning (sc);disp (sc)
creditscorecard属性:GoodLabel: 0 ResponseVar:“地位”WeightsVar:“VarNames: {CustID的‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance UtilRate的“地位”}NumericPredictors: {‘CustAge’‘TmAtAddress’‘CustIncome’‘TmWBank’‘AMBalance’‘UtilRate} CategoricalPredictors: {“ResStatus”“EmpStatus”“OtherCC”} BinMissingData: 1 IDVar:“CustID”PredictorVars: {‘CustAge’‘TmAtAddress’‘ResStatus’‘EmpStatus’‘CustIncome’‘TmWBank’‘OtherCC’‘AMBalance’‘UtilRate}数据:[1200 x11表)
设置一个最小值为零CustAge和CustIncome。,任何负面的年龄或收入信息无效或超出范围”。为得分和违约概率计算,超出范围的值给出相同的点作为缺失值。
sc = modifybins (sc,“CustAge”,“MinValue”,0);sc = modifybins (sc,“CustIncome”,“MinValue”,0);
显示本信息为数值型数据“CustAge”包括缺失的数据在一个单独的本标签<失踪>。
bi = bininfo (sc,“CustAge”);disp (bi)
本好与坏的几率,悲哀InfoValue _________________出生______月______ __________{[0,33)}69年52 1.3269 -0.42156 0.018993{[33岁,37)}63年45 1.4 -0.36795 0.012839{[37、40)}72年47 1.5319 -0.2779 0.0079824{'[40岁,46)}172 89 1.9326 -0.04556 0.0004549{'[46岁,48)}59 25 2.36 0.15424 0.0016199{[48,51)}99年41 2.4146 0.17713 0.0035449{'[51岁,58)}157 62 2.5323 0.22469 0.0088407{的[58岁的Inf]} 93年25 3.72 0.60931 0.032198{' <失踪>}19 11 1.7273 -0.15787 0.00063885{“总数”}803 397 0.087112 2.0227南
显示本信息为分类数据“ResStatus”包括缺失的数据在一个单独的本标签<失踪>。
bi = bininfo (sc,“ResStatus”);disp (bi)
本好与坏的几率,悲哀出生______ _____ __________ InfoValue * * *{“租户”}296 161 1.8385 -0.095463 0.0035249{‘业主’}352 171 2.0585 0.017549 0.00013382{‘其他’}128年52 2.4615 0.19637 0.0055808{' <失踪>}27 13 2.0769 0.026469 2.3248 e-05{“总数”}803 397 0.0092627 2.0227南
为“CustAge”和“ResStatus”预测,有缺失的数据(南年代和<定义>)在训练数据和装箱过程估计一个悲哀的价值-0.15787和0.026469分别对缺失的数据在这些预测,如上所示。
为EmpStatus和CustIncome没有明确本缺失值,因为这些预测的训练数据没有缺失值。
bi = bininfo (sc,“EmpStatus”);disp (bi)
本好与坏的几率,悲哀InfoValue _______出生______月______ _____{‘未知’}396 239 1.6569 -0.19947 0.021715{“雇佣”}407 158 2.5759 0.2418 0.026323{“总数”}803 397 0.048038 2.0227南
bi = bininfo (sc,“CustIncome”);disp (bi)
本好与坏的几率,悲哀InfoValue _________________出生_____ _____{[0,29000)的}53 58 0.91379 -0.79457 0.06364{[29000、33000)}74年49 1.5102 -0.29217 0.0091366{[33000、35000)的36}68 1.8889 -0.06843 0.00041042{[35000、40000)的}193 98 1.9694 -0.026696 0.00017359{[40000、42000)的}68 34 2 -0.011271 - 1.0819 e-05{[42000、47000)的}164 66 2.4848 0.20579 0.0078175{”(47000年,正)}183年56 3.2679 0.47972 0.041657{“总数”}803 397 0.12285 2.0227南
使用fitmodel适合使用逻辑回归模型的重量(悲哀)数据证据。fitmodel内部所有的预测变量转换成有祸了值,使用自动装箱的箱子里发现的过程。fitmodel然后适合使用逐步逻辑回归模型方法(默认情况下)。对于有缺失数据的预测,有一个显式的<失踪>本,对应的悲哀值计算的数据。当使用fitmodel,相应的悲哀值<失踪>本应用在执行悲哀的转换。
(sc, mdl) = fitmodel (sc);
1。添加CustIncome、偏差= 1490.8527 Chi2Stat = 32.588614, PValue = 1.1387992 e-08 2。添加TmWBank、偏差= 1467.1415 Chi2Stat = 23.711203, PValue = 1.1192909 e-06 3。添加AMBalance、偏差= 1455.5715 Chi2Stat = 11.569967, PValue = 0.00067025601 - 4。添加EmpStatus、偏差= 1447.3451 Chi2Stat = 8.2264038, PValue = 0.0041285257 5。添加CustAge、偏差= 1442.8477 Chi2Stat = 4.4974731, PValue = 0.033944979 6。添加ResStatus、偏差= 1438.9783 Chi2Stat = 3.86941, PValue = 0.049173805 7。添加OtherCC、偏差= 1434.9751 Chi2Stat = 4.0031966, PValue = 0.045414057广义线性回归模型:分对数(状态)~ 1 + CustAge + ResStatus + EmpStatus + CustIncome + TmWBank + OtherCC + AMBalance =二项分布估计系数:估计SE tStat PValue说______ __________(拦截)0.70229 0.063959 10.98 4.7498即使CustAge EmpStatus ResStatus 0.025513 0.57421 0.25708 2.2335 1.3629 0.66952 2.0356 0.04179 0.88373 0.2929 3.0172 0.002551 CustIncome TmWBank 0.00065929 0.73535 0.2159 3.406 1.1065 0.23267 4.7556 1.9783 e-06 OtherCC AMBalance 0.043841 1.0648 0.52826 2.0156 1.0446 0.32197 3.2443 0.0011775 1200观察,1192错误自由度色散:1 x ^ 2-statistic与常数模型:88.5,p = 2.55 e-16
量表的计分卡点”点,几率,并指出双概率(PDO)”使用方法“PointsOddsAndPDO”的观点formatpoints。假设你想要一个500分的几率2(两倍是好的比坏的),双几率每50分(这550点4)的几率。
显示预测的计分卡显示缩放点保留在拟合模型。
sc = formatpoints (sc,“PointsOddsAndPDO”,(500 2));PointsInfo = displaypoints (sc)
PointsInfo =38×3表预测本点______ _________________ * * * {‘CustAge}{54.062的[0,33)}{‘CustAge}{56.282“[33岁,37)”}{‘CustAge}{[37、40)的60.012}{‘CustAge}{69.636“[40岁,46)”}{‘CustAge}{[46岁,48)的77.912}{‘CustAge}{[48, 51)的}78.86 {‘CustAge}{[51岁,58)的80.83}{‘CustAge}{的[58岁的Inf]} 96.76 {‘CustAge}{' <失踪>}64.984 {‘ResStatus}{“租户”}62.138 {‘ResStatus}{‘业主’}73.248 {‘ResStatus}{‘其他’}90.828 {‘ResStatus}{' <失踪>}74.125 {‘EmpStatus}{‘未知’}58.807 {‘EmpStatus}{“雇佣”}86.937 {‘EmpStatus}{' <失踪>}南⋮
注意点<失踪>本为CustAge和ResStatus明确显示(如64.9836和74.1250分别)。这些点从悲哀值计算<失踪>本和物流模型系数。
对预测没有缺失数据训练集,没有明确<失踪>垃圾箱。默认情况下,设置为点南对缺失的数据,它们导致的南运行时分数。没有明确的预测<失踪>本,使用名称-值参数“失踪”在formatpoints指出应该如何治疗得分缺失数据的目的。
出于演示的目的,用几行从原始数据作为测试数据,并介绍一些缺失的数据。也介绍一些无效或超出范围值。对于数值型数据,值低于最低(或以上最大)允许被认为是无效的,如一个负值的年龄(召回“MinValue”之前设置为0CustAge和CustIncome)。分类数据,无效值类别没有明确列入计分卡,例如,住宅状态未映射到计分卡的类别,如“房子”,或“abc123”等无意义的字符串。
这是一个非常小的验证数据集,仅用于说明行失踪,超出范围的得分值,与模型验证和它的关系。
tdata = dataMissing (11:18 mdl.PredictorNames);%只保留预测模型中保留tdata。状态= dataMissing.status (11:18);%副本响应变量值,需要验证的目的%设置一些缺失值tdata.CustAge(1) =南;tdata.ResStatus (2) =“<定义>”;tdata.EmpStatus (3) =“<定义>”;tdata.CustIncome(4) =南;%设置一些无效值tdata.CustAge (5) = -100;tdata.ResStatus (6) =“房子”;tdata.EmpStatus (7) =“自由职业者”;tdata.CustIncome (8) = 1;disp (tdata)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance地位……南……___________ _____ ____ ____ ____租户未知34000 44是的119.8 - 1 48 <定义>未知44000 14是的403.62 0 65房主<定义> 48000年6没有其它未知南35 111.88 0 44 436.41 0 -100其他雇用了46000名16岁是的162.21 0 33家雇佣了36000 36是的845.02 0 39租户自由职业者34000 40是的756.26 - 1 24业主雇佣1 19是的449.61 0
新的数据,看看分被分配为失踪CustAge和ResStatus,因为我们有一个明确的本点<失踪>。然而,对于EmpStatus和CustIncome的分数函数设置点南。
验证结果是不可靠的,分数南值(见验证表ValTable下图),但目前还不清楚这些影响南验证统计值(ValStats)。这是一个非常小的验证数据集,但是南分数仍可能影响验证结果在更大的数据集。
(分数,分)=分数(sc tdata);disp(分数)
551.7922 - 487.9588 481.2231 - 520.8353南南南南
disp(分)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance ____ ____替_____ _____ 64.984 62.138 58.807 67.893 61.858 75.622 89.922 78.86 74.125 58.807 82.439 - 61.061 75.622 - 89.922 96.969 - 51.132 96.76 - 73.248南南61.858 50.914 89.922 50.914 89.922 69.636 90.828 58.807 64.984 90.828 86.937 82.439 61.061 75.622 89.922 56.282 74.125 86.937 70.107 - 61.858 75.622 - 63.028 67.893 - 61.858 60.012 - 62.138南南61.061 75.622 89.922 75.622 63.028 54.062 73.248 86.937
[ValStats, ValTable] = validatemodel (sc tdata);disp (ValStats)
测量值________________________ _________ 0.16667{的精度比}{ROC曲线下面积的}0.58333 {“KS统计”}0.5 481.22 {“k值”}
disp (ValTable)
分数ProbDefault TrueBads FalseBads TrueGoods FalseGoods敏感性FalseAlarm PctObs ______⒈替__________ ________ ___________ __________ ______南南5 0 1 2 0 0 0.16667 0.125南南2 4 2 0 0.33333 0.25南南1 2 4 1 0.5 0.33333 0.375南南1 3 3 1 0.5 0.5 0.5 481.22 0.39345 - 2 3 3 0 1 0.5 0.625 487.96 0.3714 2 4 2 0 1 0.66667 0.75 520.84 0.2725 - 2 5 1 0 1 0.83333 0.875 551.79 0.19605 2 6 0 0 1 1 1
使用名称-值参数“失踪”在formatpoints选择如何分配点缺失值没有一个明确的预测<失踪>垃圾箱。在这个例子中,使用“MinPoints”选择“失踪”论点。最低分EmpStatus在上面显示的记分卡58.8072和CustIncome最小点29.3753。
不再受到验证结果南现在有一个分数值,因为所有行。
sc = formatpoints (sc,“失踪”,“MinPoints”);(分数,分)=分数(sc tdata);disp(分数)
481.2231 520.8353 517.7532 451.3405 551.7922 487.9588 449.3577 470.2267
disp(分)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance ____ ____替_____ _____ 64.984 62.138 58.807 67.893 61.858 75.622 89.922 78.86 74.125 58.807 82.439 61.061 75.622 89.922 96.76 73.248 58.807 96.969 51.132 50.914 89.922 69.636 90.828 58.807 29.375 61.858 50.914 89.922 64.984 90.828 86.937 82.439 61.061 75.622 89.922 56.282 74.125 86.937 70.107 61.858 75.622 63.028 60.012 62.138 58.807 67.893 61.858 75.622 63.028 54.062 73.248 86.937 29.375 61.061 75.622 89.922
[ValStats, ValTable] = validatemodel (sc tdata);disp (ValStats)
测量值________________________ _________ 0.66667{的精度比}{ROC曲线下面积的}0.83333 {“KS统计”}0.66667 481.22 {“k值”}
disp (ValTable)
分数ProbDefault TrueBads FalseBads TrueGoods FalseGoods敏感性FalseAlarm PctObs ______⒈替__________ ________ ___________ __________ ______ 449.36 0.5 0.50223 1 0 6 1 0 1 1 5 1 0.5 0.16667 0.25 0.125 451.34 0.49535 470.23 0.43036 1 2 4 1 0.5 0.33333 0.375 481.22 0.39345 - 2 2 4 0 1 0.33333 0.5 487.96 0.3714 2 3 3 0 1 0.5 0.625 517.75 0.28105 - 2 4 2 0 1 0.66667 0.75 520.84 0.2725 2 5 1 0 1 0.83333 0.875 551.79 0.19605 - 2 6 0 0 1 1 1
输入参数
输出参数
更多关于
引用
[1]“巴塞尔银行监管委员会:内部评级系统”的研究验证。2005年2月14号工作报告,。
[2]Refaat, M。信用风险记分卡:使用情景应用程序开发和实现。lulu.com, 2011。
p[3]吕弗勒,g和波什的说法,N。信用风险建模使用Excel VBA。威利金融,2007。
版本历史
介绍了R2015a