Unconstrained Nonlinear Optimization Algorithms
Unconstrained Optimization Definition
Unconstrained minimization is the problem of finding a vectorX
术语
Fm在unctrust-region算法
trust-Region Methods for Nonlinear Minimization
many of the methods used in Optimization Toolbox™ solvers are based ontrust regions,a simple yet powerful concept in optimization.
to understand the trust-region approach to optimization, consider the unconstrained minimization problem, minimizeF((X),,,,where the function takes vector arguments and returns scalars. Suppose you are at a pointX在n-space and you want to improve, i.e., move to a point with a lower function value. The basic idea is to approximateFwith a simpler function问,,,,which reasonably reflects the behavior of functionF在附近naround the pointX。this neighborhood is the trust region. A trial steps是Computed by minimizing (or approximately minimizing) overn。这是信任区的子问题,
(1)
当前点已更新为X+s如果F((X+s)<F((X); otherwise, the current point remains unchanged andn,信任区域是缩小的,并且重复试验步骤计算。
定义特定信任区域的关键问题以最大程度地减少F((X)are how to choose and compute the approximation问((defined at the current pointX),,,,how to choose and modify the trust regionn,,,,and how accurately to solve the trust-region subproblem. This section focuses on the unconstrained problem. Later sections discuss additional complications due to the presence of constraints on the variables.
在标准信任区域([48]),,,,the quadratic approximation问是defined by the first two terms of the Taylor approximation toF在X; the neighborhoodn通常是球形或椭圆形的形状。数学上通常陈述信任区子问题
(2)
whereG是the gradient ofF在the current pointX,,,,H是the Hessian matrix (the symmetric matrix of second derivatives),d是对角线缩放矩阵,δ是正标量表,''。'是2个norm。存在良好的算法用于解决Equation 2((see[48]); such algorithms typically involve the computation of all eigenvalues ofHand a Newton process applied to thesecular equation
这种算法为Equation 2。然而,they require time proportional to several factorizations ofH。这refore, for large-scale problems a different approach is needed. Several approximation and heuristic strategies, based onEquation 2,在文献中提出了[42]and[50])。随后在Op的近似方法timization Toolbox solvers is to restrict the trust-region subproblem to a two-dimensional subspaces(([39]and[42])。Once the subspaces已经计算出来解决的工作Equation 2是trivial even if full eigenvalue/eigenvector information is needed (since in the subspace, the problem is only two-dimensional). The dominant work has now shifted to the determination of the subspace.
这two-dimensional subspaces是determined with the aid of a下面描述的预处理共轭梯度过程。求解器定义s随着线性空间跨越s1ands2,,,,wheres1是在这个方向上of the gradientG,,,,ands2是either an approximate牛顿方向,即
(3)
or a direction ofnegative curvature,
(4)
这philosophy behind this choice ofs是to force global convergence (via the steepest descent direction or negative curvature direction) and achieve fast local convergence (via the Newton step, when it exists).
A sketch of unconstrained minimization using trust-region ideas is now easy to give:
制定二维信任区子问题。
解决Equation 2to determine the trial steps。
一世FF((X+s)<F((X), 然后X=X+s。
Adjust Δ.
这se four steps are repeated until convergence. The trust-region dimension Δ is adjusted according to standard rules. In particular, it is decreased if the trial step is not accepted, i.e.,F((X+s)≥F((X)。see[46]and[49]讨论这一方面。
优化工具箱solvers treat a few important special cases ofF特殊功能:非线性最小二乘s,,,,问uadratic functions, and linear least-squares. However, the underlying algorithmic ideas are the same as for the general case. These special cases are discussed in later sections.
Preconditioned Conjugate Gradient Method
A popular way to solve large, symmetric, positive definite systems of linear equations生命值= -G 是预处理共轭梯度(PCG)的方法。这种迭代方法需要计算形式的矩阵矢量产物的能力s manbetx 845H·V。wherev是an arbitrary vector. The symmetric positive definite matrixm是a预处理H。that is,m=C2 ,,,,whereC–1HC–1 是a well-conditioned matrix or a matrix with clustered eigenvalues.
一世na minimization context, you can assume that the Hessian matrixH是对称的。然而,H保证是正定的吗neighborhood of a strong minimizer. Algorithm PCG exits when it encounters a direction of negative (or zero) curvature, that is,dt高清≤ 0 。这PCG output directionp是either a direction of negative curvature or an approximate solution to the Newton system生命值= -G 。一世neither case,phelps to define the two-dimensional subspace used in the trust-region approach discussed intrust-Region Methods for Nonlinear Minimization。
trust-Region Methods for Nonlinear Minimization
many of the methods used in Optimization Toolbox™ solvers are based ontrust regions,a simple yet powerful concept in optimization.
to understand the trust-region approach to optimization, consider the unconstrained minimization problem, minimizeF 当前点已更新为 定义特定信任区域的关键问题以最大程度地减少 在标准信任区域( whereG
这种算法为 这two-dimensional subspaces or a direction ofnegative curvature, 这philosophy behind this choice ofs A sketch of unconstrained minimization using trust-region ideas is now easy to give: 制定二维信任区子问题。 解决 一世F Adjust Δ. 这se four steps are repeated until convergence. The trust-region dimension Δ is adjusted according to standard rules. In particular, it is decreased if the trial step is not accepted, i.e.,F 优化工具箱solvers treat a few important special cases ofF
(1)
(2)
(3)
(4)
Preconditioned Conjugate Gradient Method
A popular way to solve large, symmetric, positive definite systems of linear equations生命值
一世na minimization context, you can assume that the Hessian matrixH
Fm在unc问uasi-newton算法
不受约束优化的基础知识
Although a wide spectrum of methods exists for unconstrained optimization, methods can be broadly categorized in terms of the derivative information that is, or is not, used. Search methods that use only function evaluations (e.g., the simplex search of Nelder and Mead[30])are most suitable for problems that are not smooth or have a number of discontinuities. Gradient methods are generally more efficient when the function to be minimized is continuous in its first derivative. Higher order methods, such as Newton's method, are only really suitable when the second-order information is readily and easily calculated, because calculation of second-order information, using numerical differentiation, is computationally expensive.
Gradient methods use information about the slope of the function to dictate a direction of search where the minimum is thought to lie. The simplest of these is the method of steepest descent in which a search is performed in a direction,- ∇F((X),,,,where∇F((X)是目标函数的梯度。当要最小化的功能具有较长狭窄的山谷时,此方法非常低效,例如Rosenbrock's function
(5)
这m在imum of this function is atX= [1,1],,,,whereF((X)=0。该函数的轮廓图显示在下图,以及最小值的解决方案路径,从[-1.9,2]开始的最陡峭下降实现。1000次迭代后终止优化,与最小值距离仍然相当远。黑色区域是该方法不断从山谷的一侧曲折的地方。请注意,朝向地块的中心,当点恰好降落在山谷中心时,将采取许多更大的步骤。
Figure 5-1, Steepest Descent Method on Rosenbrock's Function
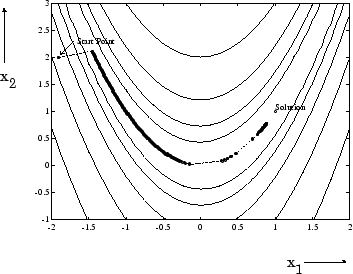
this function, also known as the banana function, is notorious in unconstrained examples because of the way the curvature bends around the origin. Rosenbrock's function is used throughout this section to illustrate the use of a variety of optimization techniques. The contours have been plotted in exponential increments because of the steepness of the slope surrounding the U-shaped valley.
For a more complete description of this figure, including scripts that generate the iterative points, seeBanana Function Minimization。
Although a wide spectrum of methods exists for unconstrained optimization, methods can be broadly categorized in terms of the derivative information that is, or is not, used. Search methods that use only function evaluations (e.g., the simplex search of Nelder and Mead[30])are most suitable for problems that are not smooth or have a number of discontinuities. Gradient methods are generally more efficient when the function to be minimized is continuous in its first derivative. Higher order methods, such as Newton's method, are only really suitable when the second-order information is readily and easily calculated, because calculation of second-order information, using numerical differentiation, is computationally expensive.
Gradient methods use information about the slope of the function to dictate a direction of search where the minimum is thought to lie. The simplest of these is the method of steepest descent in which a search is performed in a direction,- ∇
| (5) |
这m在imum of this function is atX Figure 5-1, Steepest Descent Method on Rosenbrock's Function this function, also known as the banana function, is notorious in unconstrained examples because of the way the curvature bends around the origin. Rosenbrock's function is used throughout this section to illustrate the use of a variety of optimization techniques. The contours have been plotted in exponential increments because of the steepness of the slope surrounding the U-shaped valley. For a more complete description of this figure, including scripts that generate the iterative points, seeBanana Function Minimization。
Quasi-Newton Methods
在使用梯度信息的方法中,最受欢迎的是准Newton方法。这些方法在每次迭代中构建曲率信息,以制定形式的二次模型问题 where the Hessian matrix,H 这optimal solution point,X 牛顿型方法(与准牛顿方法相反)计算 A large number of Hessian updating methods have been developed. However, the formula of Broyden[3] BFG给出的公式是 where
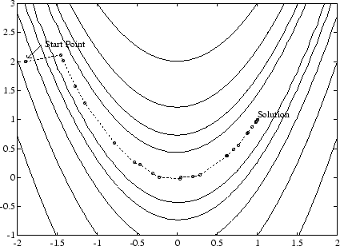
As a starting point,H 这Gradient information is either supplied through analytically calculated gradients, or derived by partial derivatives using a numerical differentiation method via finite differences. This involves perturbing each of the design variables,X At each major iteration,k 准Newton方法由解决方案路径上说明 Figure 5-2, BFGS Method on Rosenbrock's Function For a more complete description of this figure, including scripts that generate the iterative points, seeBanana Function Minimization。
(6)
(7)
(8)
((9)
(10)
行搜索
Line search是a search method that is used as part of a larger optimization algorithm. At each step of the main algorithm, the line-search method searches along the line containing the current point,Xk ,,,,parallel to thesearch direction,这是由主要算法确定的矢量。也就是说,该方法找到了下一个迭代Xk+1of the form
(11)
whereXk denotes the current iterate,dk 是the search direction, andα*是a scalar step length parameter.
线搜索方法尝试降低沿线的目标函数Xk +α*dkby repeatedly minimizing polynomial interpolation models of the objective function. The line search procedure has two main steps:
这括号在G阶段确定线上的点范围
to be searched. The括号
这sectioningstep divides the bracket into subintervals, on which the minimum of the objective function is approximated by polynomial interpolation.
这resulting step length α satisfies the Wolfe conditions:
(12)
(13)
whereC1andC2are constants with 0 <C1<C2<1。
第一个条件(等式12)requires thatαk等式13)ensures that the step length is not too small. Points that satisfy both conditions (等式12and等式13)are calledacceptable points。
这line search method is an implementation of the algorithm described in Section 2-6 of[13]。see also[31]为了more information about line search.
Line search是a search method that is used as part of a larger optimization algorithm. At each step of the main algorithm, the line-search method searches along the line containing the current point,X
| (11) |
whereX
线搜索方法尝试降低沿线的目标函数
这
括号在G 阶段确定线上的点范围 to be searched. The括号 Corresponds to an interval specifying the range of values ofα。 这
sectioningstep divides the bracket into subintervals, on which the minimum of the objective function is approximated by polynomial interpolation.
这resulting step length α satisfies the Wolfe conditions:
| (12) |
| (13) |
whereC 第一个条件( 这line search method is an implementation of the algorithm described in Section 2-6 of[13]
Hessian Update
many of the optimization functions determine the direction of search by updating the Hessian matrix at each iteration, using the BFGS method (Equation 9)。功能Fm在unc还提供了使用DFP方法的选项HessUpdateto'dfp'选择DFP方法)。黑森,
| (14) |
You always achieve the condition that
是positive by performing a sufficiently accurate line search. This is because the search direction,d
LBFGS Hessian Approximation
对于大问题,BFGS Hessian近似方法可以相对较慢,并使用大量内存。为了解决这些问题,请通过设置LBFGS Hessian近似 As described in Nocedal and Wright[31],,,,the Low-memory BFGS Hessian approximation is similar to the BFGS approximation described inQuasi-Newton Methods,但在以前的迭代中使用有限的内存。Hessian更新公式在
where
BFGS过程的另一个描述是 whereɑk
wheres
For the LBFGS algorithm, the algorithm keeps a fixed, finite numberm'lbfgs'。this causesFm在uncto use the Low-memory BFGS Hessian approximation, described next. For the benefit of using LBFGS in a large problem, see解决nonlinear Problem with Many Variables。
((15)
也可以看看
Related Topics
Related Topics
You can also select a web site from the following list:
Americas
- América Latina((Español)
- Canada((English)
- United States((English)
Europe
- Belgium((English)
- denmark((English)
- deutschland((deutsch)
- España((Español)
- 芬兰
((English) - France(Français)
- 一世reland((English)
- 一世talia(意大利语)
- Luxembourg((English)
- netherlands((English)
- norway((English)
- Österreich
((deutsch) - 葡萄牙
((English) - sweden((English)
- switzerland
- United Kingdom((English)
Asia Pacific
- Australia((English)
- 印度
((English) - new Zealand((English)
- 中国
- 日本((日本語)
- 한국((한국어)