选择分类器选项
选择分类器类型
您可以使用分类学习者自动选择不同的训练分类模型在你的数据。使用自动化培训快速试模型类型的选择,然后探索有前途的交互模型。首先,先试着这些选项:

| 开始分类器的选择 | 描述 |
|---|---|
| 所有Quick-To-Train | 先尝试此选项。应用程序将培训所有可用的模型类型适合你的数据集通常快。 |
| 所有的线性 | 尝试此选项如果你期望中的类之间的线性边界数据。此选项只适合线性支持向量机,高效的线性支持向量机,高效的逻辑回归、线性判别模型。选择也适合二进制类的二进制GLM logistic回归模型数据。 |
| 所有 | 使用这个选项来训练所有可用的nonoptimizable模型类型。火车每一类型无论任何事先训练模型。可以耗时。 |
看到自动分类器训练。
如果你想探索分类器一次,或者你已经知道分类器类型你想要的,你可以选择单独的模型或一组相同类型的训练。看到所有可用的分类器的选择,在分类学习者选项卡中,单击箭头模型部分扩大分类器的列表。nonoptimizable模型选择的模型画廊是预设的起点与不同的设置,适合各种不同的分类问题。使用optimizable自动模型选择和优化模型hyperparameters,明白了Hyperparameter优化分类学习者应用。
为帮助你选择最好的分类器类型问题,看到的表显示典型特征不同的监督学习算法和MATLAB®每一个函数的二进制或多类数据。使用表格作为指南你最后选择的算法。决定你想要的权衡在速度、灵活性和可解释性。最好的分类器类型取决于你的数据。
提示
为了避免过度拟合,寻找一个模型较低的灵活性,提供足够的精度。例如,寻找简单的模型,如决策树和判别,快速和容易理解。如果模型不够准确预测响应,选择其他分类器更高的灵活性,如集合体。控制的灵活性,看到每个分类器类型的详细信息。
特征分类器类型
| 分类器 | 可解释性 | 函数 |
|---|---|---|
| 决策树 |
容易 | fitctree |
| 判别分析 |
容易 | fitcdiscr |
| 逻辑回归分类器 |
容易 | fitglm(二进制GLM),fitclinear,fitcecoc(多级) |
| 朴素贝叶斯分类器 |
容易 | fitcnb |
| 简单的线性支持向量机 所有其他内核类型 |
fitcsvm,fitcecoc(多级) |
|
| 有效地训练线性分类器 |
容易 | fitclinear,fitcecoc(多级) |
| 最近邻分类器 |
硬 | fitcknn |
| 内核近似分类器 |
硬 | fitckernel,fitcecoc(多级) |
| 集成分类器 |
硬 | fitcensemble |
| 神经网络分类器 |
硬 | fitcnet |
读的描述每个分类器在分类学习者,切换到细节视图。

提示
在你选择了一个分类器类型(例如,决策树),尝试使用每一个分类器训练。nonoptimizable选项模型画廊是起点不同的设置。试着他们所有人都能看到哪个选项产生最好的模型数据。
工作流程说明,请参阅训练分类模型的分类学习者应用。
分类预测的支持万博1manbetx
在分类学习者,模型画廊显示可用的分类器类型支持您所选择的数据。万博1manbetx
| 分类器 | 所有的预测数字 | 所有预测分类 | 一些直言,一些数字 |
|---|---|---|---|
| 决策树 | 是的 | 是的 | 是的 |
| 判别分析 | 是的 | 没有 | 没有 |
| 逻辑回归 | 是的 | 是的 | 是的 |
| 朴素贝叶斯 | 是的 | 是的 | 是的 |
| 支持向量机 | 是的 | 是的 | 是的 |
| 有效地训练线性 | 是的 | 是的 | 是的 |
| 最近的邻居 | 欧氏距离只有 | 汉明距离只有 | 没有 |
| 内核近似 | 是的 | 是的 | 是的 |
| 乐团 | 是的 | 是的,除了子空间判别 | 是的,除了任何子空间 |
| 神经网络 | 是的 | 是的 | 是的 |
决策树
决策树很容易解释,快速拟合和预测,对内存使用和低,但他们可以预测精度较低。试着简单的树木生长,防止过度拟合。控制的深度最大数量的分裂设置。
提示
模型的灵活性增加了最大数量的分裂设置。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 粗树 |
容易 | 低 一些树叶做粗类之间的区别(分裂的最大数量是4)。 |
| 中树 |
容易 | 媒介 中等数量的叶子细类之间的区别(分裂的最大数量是20)。 |
| 好树 |
容易 | 高 许多树叶让许多细类之间的区别(分裂的最大数量是100)。 |
提示
在模型画廊,点击所有的树尝试每个nonoptimizable决策树的选择。训练他们所有人都能看到设置产生最好的与你的数据模型。选择最好的模型模型窗格。努力改善你的模型,特征选择,然后试着改变一些高级选项。
你训练分类树来预测响应数据。预测反应,遵循决策树从根节点到叶节点(开始)。叶节点包含响应。统计和机器学习工具箱™树是二进制。每一步的预测包括检查一个预测(变量)的值。例如,下面是一个简单的分类树:
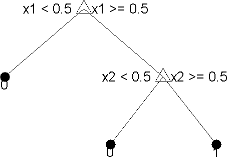
这棵树预测分类基于两个预测因子,x1和x2。预测,从顶部开始节点。在每一个决定,检查预测因子的值来决定哪个部门遵循。当树枝到达一个叶子节点,数据分为类型0或1。
你可以想象你的决策树模型导出模型的应用程序,然后输入:
视图(trainedModel.ClassificationTree,“模式”,“图”)
fisheriris数据。

提示
例如,看到的火车使用分类学习者应用决策树。
树模型Hyperparameter选项
分类树的分类学习者使用fitctree函数。你可以设置这些选项:
最大数量的分裂
指定的最大数量分裂或分支点来控制你的树的深度。当你种植一个决策树,考虑它的简单性和预测能力。改变分裂的数量,单击按钮或输入一个正整数价值最大数量的分裂盒子。
好树和许多树叶在训练数据通常是高度准确的。然而,树可能不会对一个独立的测试集显示类似的准确性。绿叶树往往训练过度,及其验证准确性往往远低于其培训(或resubstitution)的准确性。
相比之下,一个粗树不达到训练精度高。但粗树可以更强劲,其训练精度的方法测试集的代表。同时,粗树很容易解释。
划分的标准
为决定何时将指定分割标准衡量节点。试试这三个设置是否改善与您的数据模型。
分割标准选项
基尼的多样性指数,两个规则,或最大限度减少异常(也称为交叉熵)。分类树试图优化纯节点只包含一个类。基尼的多样性指数(默认)和异常杂质标准衡量节点。两个规则是一个不同的测量来决定如何分割一个节点,在增加节点纯度最大化两个规则表达式。
这些分割标准的详细信息,请参阅
ClassificationTree更多关于。代理决定分裂——只对缺失的数据。
为决定将指定代理使用。如果你有数据缺失值,使用代理分裂来提高预测的准确性。
当您设置代理决定分裂来
在,分类树发现最多10个代理在每个分支节点分裂。改变数量,单击按钮或输入一个正整数价值每个节点最大代理人盒子。当您设置代理决定分裂来
找到所有分类树,找到所有代理在每个分支节点分裂。的找到所有设置可以使用相当多的时间和内存。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。
判别分析
判别分析是一种流行的第一次尝试,因为它是快速分类算法,准确和容易理解。判别分析对大数据集。
判别分析假定不同的类生成数据根据不同的高斯分布。训练一个分类器,拟合函数估计为每个类高斯分布的参数。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 线性判别 |
容易 | 低 创建了类之间的线性边界。 |
| 二次判别 |
容易 | 低 创建了类之间的非线性边界(椭圆,抛物线和双曲线)。 |
判别模型Hyperparameter选项
判别分析分类学习者使用fitcdiscr函数。对于线性和二次判别,可以改变的协方差结构选择。如果你有预测方差为零或者任何你的预测协方差矩阵的奇异,培训可以使用默认的失败,完整的协方差结构。如果训练失败,选择对角协方差结构。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。
逻辑回归分类器
逻辑回归是一个流行的分类算法来试一试,因为它是容易解释。这些分类器模型类概率的函数的线性组合预测。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 漠视二进制逻辑回归 R2023a:逻辑回归之前 |
容易 | 低 你不能改变任何参数控制模型的灵活性。 |
| 高效的逻辑回归 |
容易 | 媒介 你可以改变hyperparameter设置的能手,λ,和β宽容。 |
在分类学习者使用二进制GLM逻辑回归fitglm函数。高效的逻辑回归使用fitclinear二进制类数据的函数fitcecoc多类数据。fitclinear和fitcecoc使用技术,减少培训成本的计算时间准确性。当训练数据和预测或许多观察,考虑使用高效的逻辑回归。
逻辑回归Hyperparameter选项
你不能设置任何二进制GLM hyperparameter选项分类器。对于有效的逻辑回归,您可以设置这些选项:
解算器
确定目标函数最小化的方法。的汽车设置使用高炉煤气解算器。如果有100多个预测模型,汽车设置使用SGD解算器。请注意,双解算器设置有效的逻辑回归分类器不可用。关于解决的更多信息,请参阅解算器。
正则化强度(λ)
指定正则化强度参数。的汽车设置集λ= 1 / n,其中n是观察在训练样本的数量(或数量的观察,如果你使用交叉验证)。正则化力量的更多信息,请参阅λ。
β宽容
指定线性系数的相对公差和偏差,从而影响优化终止时。默认值是0.0001。β宽容的更多信息,请参阅BetaTolerance。
朴素贝叶斯分类器
Naive Bayes分类器易于理解和有用的多类分类。朴素贝叶斯算法利用贝叶斯定理,使预测的假设是条件独立的,考虑到类。使用这些分类器如果这种独立性假设是有效的预测数据。然而,该算法仍然似乎工作得很好时,独立性假设是无效的。
对于内核朴素贝叶斯分类器,可以控制内核类型更平稳内核类型设置和控制内核平滑密度与支持万博1manbetx万博1manbetx设置。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 高斯朴素贝叶斯 |
容易 | 低 你不能改变任何参数控制模型的灵活性。 |
| 内核朴素贝叶斯 |
容易 | 媒介 您可以更改设置内核类型和万博1manbetx控制如何分类器模型预测分布。 |
朴素贝叶斯分类学习者使用fitcnb函数。
朴素贝叶斯模型Hyperparameter选项
对于内核朴素贝叶斯分类器,您可以设置这些选项:
内核类型——指定内核流畅的类型。尝试设置这些选项,看看他们改善与您的数据模型。
内核类型选项
高斯,盒子,Epanechnikov,或三角形。万博1manbetx——指定内核平滑密度的支持。万博1manbetx尝试设置这些选项,看看他们改善与您的数据模型。
万博1manbetx支持选项
无限(所有真实值)或积极的(所有积极的实际值)。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。
下一步训练模型,明白了训练分类模型的分类学习者应用。
万博1manbetx支持向量机
在分类学习者,你可以训练支持向量机当你的数据有两个或更多的类。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 线性支持向量机 |
容易 | 低 使一个简单的线性类之间的分离。 |
| 二次支持向量机 |
硬 | 媒介 |
| 立方支持向量机 |
硬 | 媒介 |
| 细高斯支持向量机 |
硬 | 高,随内核规模设置。 使精确详细的类之间的区别,内核将规模 倍根号(P) / 4。 |
| 介质高斯支持向量机 |
硬 | 媒介 中等的区别,内核将规模 sqrt (P)。 |
| 高斯粗糙支持向量机 |
硬 | 低 使粗类之间的区别,内核将规模 sqrt (P) * 4,P是预测的数量。 |
提示
尝试每个nonoptimizable训练支持向量机的选项万博1manbetx模型画廊。训练他们所有人都能看到设置产生最好的与你的数据模型。选择最好的模型模型窗格。努力改善你的模型,特征选择,然后试着改变一些高级选项。
SVM分类数据通过寻找最好的超平面分离数据点的类与其他类。最好的超平面的支持向量机方法的两个类之间的最大利润。利润率意味着最大宽度的板平行超平面,没有内部数据点。
的万博1manbetx支持向量是最接近的数据点分离超平面;这些点是在板的边界。下图说明了这些定义,+表示类型的数据点1,-表示数据点1型。

支持向量机也可以使用软边缘,这意味着一个超平面,将很多,但并非所有的数据点。
例如,看到的使用分类学习万博1manbetx者应用训练支持向量机。
支持向量机模型Hyperparameter选项
如果你有两个类,分类学习者使用fitcsvm函数来训练分类器。如果你有超过两个类,应用程序使用fitcecoc函数来减少多类分类问题的一组二进制分类子问题,与一个SVM学习者对于每个子问题。检查代码的二进制和多级分类器类型,你可以从你的训练分类器在应用程序生成代码。
你可以设置这些选项的应用:
核函数
指定核函数计算分类器。
线性内核,简单的解释
高斯径向基函数(RBF)的内核
二次
立方
箱约束水平
指定箱约束保持拉格朗日乘数法允许的值在一个盒子里,一个有界区域。
来优化您的支持向量机分类器,尝试增加箱约束水平。单击按钮或输入一个积极的标量值箱约束水平盒子。增加箱约束水平可以减少支持向量的个数,还可以增加训练时间。万博1manbetx
箱约束参数是soft-margin点球被称为C的原始方程,是一个坚硬的“盒子”在双重约束方程。
内核扩展模式
如果需要手动指定内核扩展。
当您设置内核扩展模式来
汽车,那么,该软件使用启发式程序选择刻度值。启发式程序使用二次抽样。因此,为了繁殖的结果,设置一个随机数种子使用rng前训练分类器。当您设置内核扩展模式来
手册,您可以指定一个值。单击按钮或输入一个积极的标量值手动内核规模盒子。软件划分预测矩阵的所有元素的价值内核。然后,软件应用适当的内核规范计算格拉姆矩阵。提示
与内核模式的灵活性降低规模设置。
多类方法
只有数据3或更多的类。这种方法减少了多类分类问题的一组二进制分类子问题,每个子问题与一个SVM学习者。
One-vs-One火车一个学习者对于每一对类。它学会区分从另一个类。One-vs-All火车一个学习者对于每个类。学会区分一个类和其他所有人。标准化数据
指定每个坐标是否规模距离。如果预测有广泛不同的尺度,规范可以改善健康。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。
有效地训练线性分类器
有效地训练线性分类器使用技术,减少培训成本的计算时间准确性。可用的有效训练模型逻辑回归和支持向量机(SVM)。万博1manbetx当训练数据和预测或许多观察,考虑使用有效地训练线性分类器的漠视而不是现有的二进制逻辑回归或线性SVM预设模型。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 高效的逻辑回归 |
容易 | 媒介 你可以改变hyperparameter设置的能手,λ,和β宽容。 |
| 有效的线性支持向量机 |
容易 | 媒介 你可以改变hyperparameter设置的能手,λ,和β宽容。 |
Hyperparameter选择有效地训练线性分类器
有效地训练线性分类器使用fitclinear二进制类数据的功能,fitcecoc函数多类数据。你可以设置以下选项:
解算器
确定目标函数最小化的方法。的汽车设置使用高炉煤气解算器。如果有100多个预测模型,汽车设置使用SGD为有效解决逻辑回归,双为有效解决线性支持向量机。请注意,双解算器设置有效的逻辑回归分类器不可用。关于解决的更多信息,请参阅解算器。
正则化强度(λ)
指定正则化强度参数。的汽车设置集λ= 1 / n,其中n是观察在训练样本的数量(或数量的观察,如果你使用交叉验证)。正则化力量的更多信息,请参阅λ。
β宽容
指定线性系数的相对公差和偏差,从而影响优化终止时。默认值是0.0001。β宽容的更多信息,请参阅BetaTolerance。
最近邻分类器
最近邻分类器通常具有良好的预测精度在低维空间中,但可能不会在高维度。他们有很高的内存使用,不容易解释。
提示
模型的灵活性降低数量的邻居设置。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 好资讯 |
硬 | 详细类之间的区别。邻居的数量设置为1。 |
| 媒介资讯 |
硬 | 中类之间的区别。邻居的数量设置为10。 |
| 粗糙的资讯 |
硬 | 粗类之间的区别。邻居的数量设置为100。 |
| 余弦资讯 |
硬 | 中类之间的区别,使用余弦距离度量。邻居的数量设置为10。 |
| 立方资讯 |
硬 | 中类之间的区别,使用一个立方的距离度量。邻居的数量设置为10。 |
| 加权资讯 |
硬 | 中类之间的区别,使用距离重量。邻居的数量设置为10。 |
提示
试着训练的每个nonoptimizable最近邻的选择模型画廊。训练他们所有人都能看到设置产生最好的与你的数据模型。选择最好的模型模型窗格。努力改善你的模型,特征选择,然后(可选)尝试改变一些高级选项。
是什么k最近的邻居分类?分类查询点根据距离点(或邻居)在一个训练数据集可以是一个简单而有效的方法分类的新观点。您可以使用各种指标来确定距离。给定一组X的n分和一个距离函数,k最近的邻居(kNN)搜索可以找到k最近的点X查询点或点集。kNN-based机器学习算法被广泛用作基准规则。

例如,看到的使用分类学习者应用最近邻分类器训练。
然而,模型Hyperparameter选项
最近邻分类器在分类学习者使用fitcknn函数。你可以设置这些选项:
数量的邻居
指定的数量最近的邻居找到对每个点进行分类预测。指定一个细(低)或粗分类器(大量)通过改变邻居的数量。例如,一个好的资讯使用一个邻居,和粗资讯使用100。很多邻居都可以耗费时间来适应。
距离度量
您可以使用各种指标来确定点的距离。定义,请参阅
ClassificationKNN。距离重量
指定的距离加权函数。你可以选择
平等的(没有重量),逆(重量是1 /距离),或方逆(重量是1 /距离2)。标准化数据
指定每个坐标是否规模距离。如果预测有广泛不同的尺度,规范可以改善健康。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。
内核近似分类器
在分类学习者,你可以使用内核近似分类器来执行非线性分类与许多观测的数据。大内存数据,内核分类器训练和预测的速度比与高斯核支持向量机分类器。
高斯核分类模型预测在低维空间映射到一个高维空间,然后符合线性模型在高维空间转换后的预测因子。选择合适的一个线性模型和支持向量机拟合逻辑回归线性模型的扩展空间。
提示
在模型画廊,点击所有的内核![]() 尝试每一个预设内核近似选项,看看设置产生最好的与你的数据模型。选择最好的模型模型面板,试图改善这种模式通过使用特征选择和改变一些高级选项。
尝试每一个预设内核近似选项,看看设置产生最好的与你的数据模型。选择最好的模型模型面板,试图改善这种模式通过使用特征选择和改变一些高级选项。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 支持向量机内核 |
硬 | 中期随着增加内核规模设置减少 |
| 逻辑回归的内核 |
硬 | 中期随着增加内核规模设置减少 |
例如,看到的火车内核使用分类学习者应用近似分类器。
内核模式Hyperparameter选项
如果你有两个类,分类学习者使用fitckernel内核函数来训练分类器。如果你有超过两个类,应用程序使用fitcecoc函数来减少多类分类问题的一组二进制分类子问题,与一个内核学习者对于每个子问题。
你可以设置这些选项:
学习者——指定线性分类模型类型的扩展空间,
支持向量机或逻辑回归。内核支持向量机分类器使用一个铰链损失函数模型拟合,而逻辑回归内核分类器使用异常(物流)的损失。数量扩张的维度——指定扩展空间的维数。
当您设置这个选项
汽车,软件集的维数2 . ^装天花板(最低(log2 (p) + 5、15)),在那里p预测的数量。当您设置这个选项
手册,您可以指定一个值通过单击按钮或进入盒子里积极的标量值。
正则化强度(λ)——指定脊(L2)正规化惩罚项。当您使用一个支持向量机学习,约束C和正则化项的力量λ是相关的C= 1 / (λn),在那里n是观测的数量。
当您设置这个选项
汽车,软件设置正则化力量1 /n,在那里n是观测的数量。当您设置这个选项
手册,您可以指定一个值通过单击按钮或进入盒子里积极的标量值。
内核规模——指定内核扩展。软件使用这个值来获得一个随机随机功能扩张的基础。更多细节,请参阅随机特性扩张。
当您设置这个选项
汽车,软件使用启发式程序选择刻度值。启发式程序使用二次抽样。因此,为了繁殖的结果,设置一个随机数种子使用rng前训练分类器。当您设置这个选项
手册,您可以指定一个值通过单击按钮或进入盒子里积极的标量值。
多类方法——指定的方法减少了多类问题的一组二进制子问题,每个子问题与一个内核学习者。这个值只适用于数据超过两类。
One-vs-One火车一个学习者对于每一对类。这种方法学会区分从另一个类。One-vs-All火车一个学习者对于每个类。这种方法学会区分一个类和所有其他人。
迭代限制——指定训练迭代的最大数量。
集成分类器
系综分类器融合结果从许多薄弱的学习者为一个高质量的整体模型。品质取决于算法的选择。
提示
模型的灵活性增加了许多学习者设置。
都系综分类器往往是缓慢的适应,因为他们通常需要许多学习者。
| 分类器类型 | 可解释性 | 整体方法 | 模型的灵活性 |
|---|---|---|---|
| 提高了树 |
硬 | 演算法,决策树学习者 |
中等到高-增加许多学习者或最大数量的分裂设置。 提示 比袋装了树木通常可以做得更好,但可能需要参数调优和更多的学习者 |
| 袋装的树木 |
硬 | 随机森林袋,决策树学习者 |
高,随许多学习者设置。 提示 先试试这个分类器。 |
| 子空间判别 |
硬 | 子空间,判别学习者 |
中期增加而许多学习者设置。 对许多预测 |
| 子空间资讯 |
硬 | 子空间,最近的邻居学习者 |
中期增加而许多学习者设置。 对许多预测 |
| RUSBoost树 |
硬 | RUSBoost,决策树学习者 |
中期增加而许多学习者或最大数量的分裂设置。 有利于倾斜数据(更多的观察1类) |
| GentleBoost或LogitBoost——而不是可用的模型类型画廊。 如果你有2类数据,手动选择。 |
硬 | GentleBoost或LogitBoost,决策树学习者选择 提高了树和改变GentleBoost方法。 |
中期增加而许多学习者或最大数量的分裂设置。 仅供二元分类 |
使用Breiman袋装树随机森林的算法。供参考,看Breiman, l .随机森林。机器学习45岁5-32,2001页。
提示
首先尝试袋装树。提高树木通常可以做得更好,但可能需要搜索许多参数值,这是耗时。
试着训练的每个nonoptimizable系综分类器的选项模型画廊。训练他们所有人都能看到设置产生最好的与你的数据模型。选择最好的模型模型窗格。努力改善你的模型,特征选择,主成分分析,然后(可选)尝试改变一些高级选项。
促进整体的方法,你可以得到细节与更深的树木或大量的浅树。与单一的树分类器,深树会导致过度拟合。你需要实验选择最佳树树的深度合奏,为了权衡数据符合树的复杂性。使用许多学习者和最大数量的分裂设置。
例如,看到的使用分类学习者应用合奏训练分类器。
整体模型Hyperparameter选项
系综分类器在分类学习者使用fitcensemble函数。你可以设置这些选项:
帮忙选择整体方法和学习者类型,看到合奏表。首先尝试预设。
最大数量的分裂
对于提高整体方法,指定的最大数量分裂或分支点来控制你的树学习者的深度。许多分支往往overfit,可以更加健壮和简单的树,很容易解释。实验选择最佳树树的深度。
许多学习者
试着改变学习者的数量是否可以改善模型。许多学习者能生产高精度,但可以耗费时间来适应。从几十个学生,然后检查性能。一个具有良好的预测能力可以需要几百学习者。
学习速率
指定收缩的学习速率。如果你将学习速率设置为小于1,乐团需要更多的迭代学习但往往达到更好的精度。0.1是一个受欢迎的选择。
子空间维数
对于子空间集合体,指定数量的预测样本在每个学习者。预测的应用程序选择一个随机子集为每一个学习者。选择的子集不同的学习者都是独立的。
样本数量的预测
指定数量的预测随机选择树中的每个分裂学习者。
当您设置这个选项
选择所有,软件使用所有可用的预测因子。当您设置这个选项
限量,您可以指定一个值通过单击按钮或输入一个正整数价值在盒子里。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。
神经网络分类器
神经网络模型通常具有良好的预测精度,可用于多类分类;然而,他们并不容易解释。
模型的灵活性增加的规模和数量完全连接层的神经网络。
提示
在模型画廊,点击所有的神经网络![]() 尝试每一个预设神经网络选项,看看设置产生最好的模型数据。选择最好的模型模型面板,试图改善这种模式通过使用特征选择和改变一些高级选项。
尝试每一个预设神经网络选项,看看设置产生最好的模型数据。选择最好的模型模型面板,试图改善这种模式通过使用特征选择和改变一些高级选项。
| 分类器类型 | 可解释性 | 模型的灵活性 |
|---|---|---|
| 狭窄的神经网络 |
硬 | 中期的增加第一层的大小设置 |
| 中神经网络 |
硬 | 中期的增加第一层的大小设置 |
| 广泛的神经网络 |
硬 | 中期的增加第一层的大小设置 |
| 双层神经网络 |
硬 | 高收入的增加第一层的大小和第二层的大小设置 |
| Trilayered神经网络 |
硬 | 高收入的增加第一层的大小,第二层的大小,第三层的大小设置 |
每一个模型是一个前馈,完全连接神经网络分类。第一个完全连接层的神经网络已连接网络输入(预测数据),并且每个后续层从上一层连接。每个完全连接层乘以权重矩阵的输入向量,然后添加一个偏见。一个激活函数遵循每个完全连接层。最后完全连接层和后续softmax激活函数生成网络的输出,即分数(后验概率)和预测分类标签。有关更多信息,请参见神经网络结构。
例如,看到的使用分类学习者应用训练神经网络分类器。
神经网络模型Hyperparameter选项
神经网络分类器在分类学习者使用fitcnet函数。你可以设置这些选项:
完全连接层——指定的数量完全连接层神经网络,不包括最终的完全连接层进行分类。您最多可以选择3个完全连接层。
第一层的大小,第二层的大小,第三层的大小——指定每个完全连接层的大小,除最后一个完全连接层。如果您选择创建一个与多个完全连接神经网络层,考虑减少大小指定层。
激活——指定所有完全连接层的激活函数,除最后一个完全连接层。最后一个完全连接层的激活函数总是softmax。选择下面的激活函数:
线性整流函数(Rectified Linear Unit),双曲正切,没有一个,乙状结肠。迭代限制——指定训练迭代的最大数量。
正则化强度(λ)——指定脊(L2)正规化惩罚项。
标准化数据——指定是否标准化数值预测。如果预测有广泛不同的尺度,规范可以改善健康。标准化的数据是高度推荐。
或者,您可以让应用程序选择这些模型自动选择使用hyperparameter优化。看到Hyperparameter优化分类学习者应用。