fsulaplacian
Rank features for unsupervised learning using Laplacian scores
Description
idx= fsulaplacian(X)Xusing theLaplacian scores. The function returnsidx, which contains the indices of features ordered by feature importance. You can useidxto select important features for unsupervised learning.
idx= fsulaplacian(X,Name,Value)'NumNeighbors',10创建一个similarity graphusing 10 nearest neighbors.
Examples
Rank Features by Importance
Load the sample data.
loadionosphere
Rank the features based on importance.
[idx,scores] = fsulaplacian(X);
Create a bar plot of the feature importance scores.
bar(scores(idx)) xlabel('Feature rank') ylabel('Feature importance score')
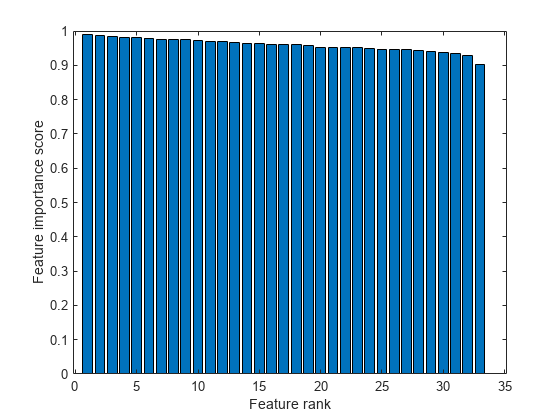
Select the top five most important features. Find the columns of these features inX.
idx(1:5)
ans =1×515 13 17 21 19
The 15th column ofXis the most important feature.
Rank Features Using Specified Similarity Matrix
Compute a similarity matrix from Fisher's iris data set and rank the features using the similarity matrix.
Load Fisher's iris data set.
loadfisheriris
Find the distance between each pair of observations inmeasby using thepdistandsquareformfunctions with the default Euclidean distance metric.
D = pdist(meas); Z = squareform(D);
Construct the similarity matrix and confirm that it is symmetric.
S = exp(-Z.^2); issymmetric(S)
ans =logical1
Rank the features.
idx = fsulaplacian(meas,'Similarity',S)
idx =1×43 4 1 2
Ranking using the similarity matrixSis the same as ranking by specifying'NumNeighbors'assize(meas,1).
idx2 = fsulaplacian(meas,'NumNeighbors',size(meas,1))
idx2 =1×43 4 1 2
Input Arguments
输出参数
More About
Algorithms
References
[1] He, X., D. Cai, and P. Niyogi. "Laplacian Score for Feature Selection."NIPS Proceedings.2005.
Version History
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(德语)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(德语)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)