kmeans
k-均值聚类
语法
描述
例子
列车ak-均值聚类算法
使用群集数据k-表示聚类,然后绘制聚类区域。
载入费雪的虹膜数据集。使用花瓣的长度和宽度作为预测因素。
负载鱼腥草X =量(:,3:4);图;情节(X (: 1) X (:, 2),“k*”,“MarkerSize”,5);头衔“费舍尔的虹膜数据”;xlabel‘花瓣长度(厘米)’;ylabel“花瓣宽度(cm)”;
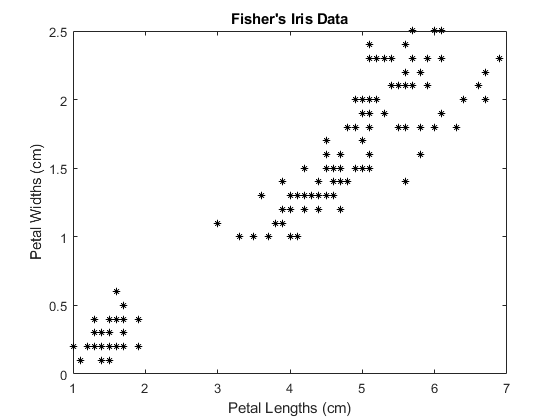
较大的簇似乎被分成一个低方差区域和一个高方差区域。这可能表明较大的簇是两个重叠的簇。
集群的数据。指定k= 3集群。
rng(1);%的再现性[idx,C]=kmeans(X,3);
idx是与中的观测值相对应的预测聚类指数向量X.C是一个包含最终质心位置的3 × 2矩阵。
使用kmeans计算从每个质心到网格上各点的距离。要做到这一点,通过质心(C),并在网格上指向kmeans,并实现算法的一次迭代。
x1 = min (X(: 1)): 0.01:马克斯(X (: 1));x2 = min (X(:, 2)): 0.01:马克斯(X (:, 2));[x1G, x2G] = meshgrid (x1, x2);XGrid = [x1G (:), x2G (:));在plot上定义一个精细的网格idx2Region = kmeans (XGrid 3“MaxIter”,1,“开始”C);
警告:未能在1次迭代中收敛。
%将栅格中的每个节点指定给最近的质心
kmeans显示一条警告,指出算法没有收敛,这是您应该预料到的,因为软件只实现了一次迭代。
绘制集群区域。
图:gscatter(XGrid(:,1),XGrid(:,2),idx2区域,...[0, 0.75, 0.75, 0.75, 0, 0.75, 0.75, 0.75, 0],“. .”); 持有在;情节(X (: 1) X (:, 2),“k*”,“MarkerSize”,5);头衔“费舍尔的虹膜数据”;xlabel‘花瓣长度(厘米)’;ylabel“花瓣宽度(cm)”;传奇(“地区1”,《区域2》,区域3的,“数据”,“位置”,“东南”); 持有从;
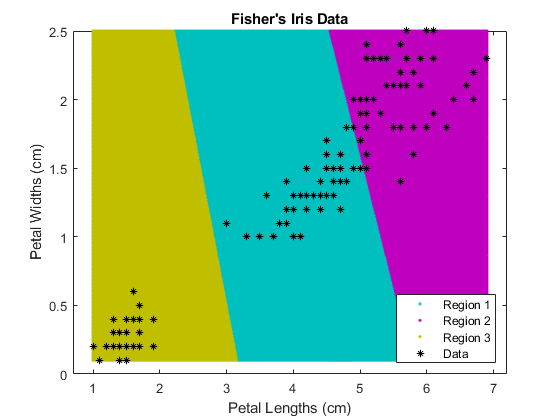
将数据划分为两个集群
随机生成样本数据。
rng违约;%的再现性X=[randn(100,2)*0.75+一(100,2);randn(100,2)*0.5-一(100,2)];图;图(X(:,1),X(:,2),“。”);标题随机生成的数据的;
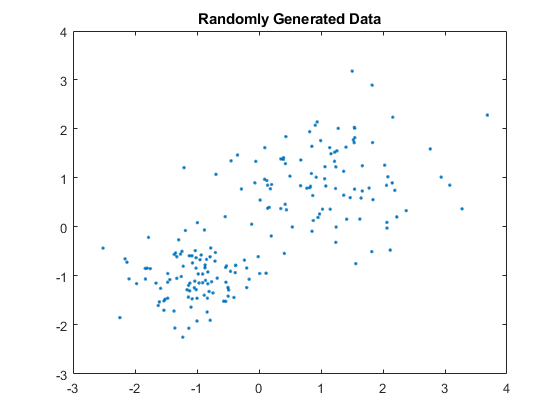
数据中似乎有两个集群。
将数据划分为两个集群,并在五个初始化中选择最佳的安排。显示最终输出。
选择= statset (“显示”,“决赛”);[idx,C]=kmeans(X,2,“距离”,“城市街区”,...“复制品”5,“选项”,opts);
重复1,3次迭代,总距离之和= 201.533。重复2,5次迭代,总距离之和= 201.533。重复3,3次迭代,总距离之和= 201.533。重复4,3次迭代,总距离之和= 201.533。重复5次,2次迭代,总距离之和= 201.533。距离的最佳总和= 201.533
默认情况下,软件将单独初始化复制k——+ +。
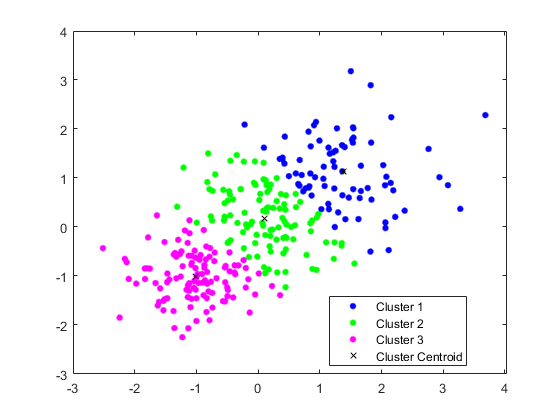
画出星团和星团中心。
图;情节(X (idx = = 1,1) X (idx = = 1、2),“r”。,“MarkerSize”等一下在情节(X (idx = = 2, 1), X (idx = = 2, 2),“b”。,“MarkerSize”图(C(:,1),C(:,2),“kx”,...“MarkerSize”,15,“线宽”3)传说(“集群1”,“集群2”,“重心”,...“位置”,“西北”)标题“群集分配和质心”持有从

您可以通过传递来确定集群的分离程度idx来轮廓.
使用并行计算的集群数据
聚集大型数据集可能需要时间,特别是在使用在线更新(默认设置)的情况下。如果您有一个并行计算工具箱™许可,并且设置了并行计算的选项,那么kmeans并行运行每个群集任务(或复制)。如果复制>1,则并行计算减少了收敛时间。
从高斯混合模型中随机生成一个大数据集。
μ= bsxfun (@times(20、30),(1:20)');%高斯混合均值rn30=随机数(30,30);西格玛=rn30'*rn30;%对称正定协方差Mdl = gmdistribution(μ、σ);%定义高斯混合分布rng(1);%的再现性X =随机(Mdl, 10000);
Mdl是一个30维的gmdistribution模型包含20个组件。X一个10000 × 30的数据矩阵是从哪里产生的Mdl.
指定并行计算的选项。
流= RandStream (“mlfg6331_64”);%随机数流选择= statset (“UseParallel”,1,“使用子流”,1,...“溪流”、流);
输入参数“mlfg6331_64”的兰德斯特朗指定使用乘法滞后的斐波那契生成算法。选项是一个结构数组,其字段指定用于控制估计的选项。
使用以下方法聚类数据k——集群。指定有k=数据中的20个群集,并增加迭代次数。通常,目标函数包含局部最小值。指定10个副本以帮助找到较低的局部最小值。
抽搐;启动秒表计时器[idx,C,sumd,D]=kmeans(X,20,“选项”选项,“MaxIter”, 10000,...“显示”,“决赛”,“复制品”10);
使用“local”配置文件启动并行池(parpool)…连接到6个工人。复制5,72次迭代,总距离之和= 7.73161e+06。重复1,64次迭代,总距离之和= 7.72988e+06。重复3,68次,总距离之和= 7.72576e+06。重复4,84次,总距离之和= 7.72696e+06。重复6,82次迭代,总距离之和= 7.73006e+06。重复7,40次迭代,总距离之和= 7.73451e+06。重复2,194次迭代,总距离之和= 7.72953e+06。重复9,105次迭代,总距离之和= 7.72064e+06。 Replicate 10, 125 iterations, total sum of distances = 7.72816e+06. Replicate 8, 70 iterations, total sum of distances = 7.73188e+06. Best total sum of distances = 7.72064e+06
toc终止秒表计时器
运行时间为61.915955秒。
命令窗口表示有6个工作人员可用。在您的系统中,工作人员的数量可能会有所不同。命令窗口显示每个复制的迭代次数和终端目标函数值。输出参数包含复制9的结果,因为它的距离总和最低。
将新数据分配给现有集群并生成C/ c++代码
kmeans执行k-表示聚类将数据划分为k集群。当您有一个新的数据集要集群时,您可以使用kmeans这个kmeans函数支持C/ c+万博1manbetx+代码生成,因此您可以生成接受训练数据并返回集群结果的代码,然后将代码部署到设备上。在这个工作流中,您必须通过训练数据,这些数据可能相当大。为了节省设备上的内存,您可以使用分离训练和预测kmeans和pdist2,分别。
使用kmeans在MATLAB®中创建集群并使用pdist2在生成的代码中将新数据分配给现有集群。对于代码生成,定义一个入口点函数,该函数接受集群质心位置和新的数据集,并返回最近的集群的索引。然后,生成入口点函数的代码。
生成C/C++代码需要MATLAB®编码器™.
执行k-均值聚类
使用三个分布生成一个训练数据集。
rng (“默认”)%的再现性X = [randn(100 2) * 0.75 +(100 2)的;randn(100 2) * 0.5的(100 2);randn (100 2) * 0.75);
将训练数据分成三个聚类kmeans.
[idx,C]=kmeans(X,3);
画出星团和星团中心。
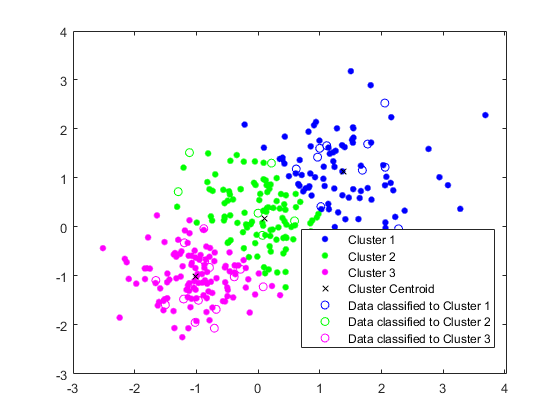
图gscatter (X (: 1), (:, 2), idx,“bgm”)持有在情节(C (: 1), C (:, 2),“kx”)传奇(“集群1”,“集群2”,“第三组”,聚类质心的)
将新数据分配给现有集群
生成一个测试数据集。
Xtest = [randn(10, 2) * 0.75 +的(10,2);randn(10, 2) * 0.5的(10,2);randn (10, 2) * 0.75);
使用现有的集群对测试数据集进行分类。使用。找到每个测试数据点最近的质心pdist2.
[~, idx_test] = pdist2 (C Xtest“欧几里得”,“最小的”1);
绘制测试数据并使用标记测试数据idx_test通过使用gscatter.
gscatter (Xtest (: 1) Xtest (:, 2), idx_test,“bgm”,“哦”)传奇(“集群1”,“集群2”,“第三组”,聚类质心的,...“分类到群集1的数据”,“分类到群集2的数据”,...“分类到群集3的数据”)
生成代码
生成为现有集群分配新数据的C代码。请注意,生成C/C++代码需要MATLAB®编码器™.
定义一个入口点函数名为findNearestCentroid它接受质心位置和新数据,然后通过使用pdist2.
添加%#编码基因编译器指令(或pragma)到函数签名后的入口点函数,以指示您打算为MATLAB算法生成代码。添加此指令将指示MATLAB代码分析器帮助您诊断和修复在代码生成期间可能导致错误的违规。
类型findNearestCentroid%显示findNearestCentroid.m的内容
函数idx = findNearestCentroid(C,X) %#codegen [~,idx] = pdist2(C,X,'欧几里得','最小',1);找到最近的质心
注:如果你点击这个页面右上角的按钮,并在MATLAB®中打开这个示例,那么MATLAB®将打开示例文件夹。这个文件夹包括入口点函数文件。
使用以下命令生成代码codegen(MATLAB编码器)因为C和C++是静态类型的语言,所以必须在编译时确定入口点函数中所有变量的属性。findNearestCentroid,传递一个MATLAB表达式,该表达式表示具有特定数据类型和数组大小的值集,使用arg游戏选择。有关详细信息,请参见指定用于代码生成的可变大小参数.
codegenfindNearestCentroidarg游戏{C,Xtest}
代码生成成功。
codegen生成MEX函数findNearestCentroid_mex与平台相关的扩展。
验证生成的代码。
myIndx=findNearestCentroid(C,Xtest);myIndex_-mex=findNearestCentroid_-mex(C,Xtest);verifyMEX=isequal(idx_测试,myIndx,myIndex_-mex)
verifyMEX =逻辑1
isequal返回逻辑1 (真正的),这意味着所有的输入都是相等的。比较确认pdist2功能findNearestCentroid函数,而MEX函数返回相同的索引。
您还可以使用GPU编码器™生成优化的CUDA®代码。
cfg = coder.gpuConfig (墨西哥人的);codegen配置cfgfindNearestCentroidarg游戏{C,Xtest}
有关代码生成的更多信息,请参见通用代码生成工作流。有关GPU编码器的更多信息,请参阅开始与GPU编码器(GPU编码器)和万博1manbetx支持函数(GPU编码器).
输入参数
输出参数
更多关于
算法
kmeans使用两阶段迭代算法最小化点到质心的距离之和,在所有情况下求和k集群。第一阶段使用批量更新,其中每次迭代包括一次将点重新分配到最近的簇质心,然后重新计算簇质心。此阶段偶尔不会收敛到局部最小值的解决方案。也就是说,将任何单个点移动到不同簇会增加距离的总和这更可能适用于小数据集。批处理阶段很快,但可能仅近似于作为第二阶段起点的解决方案。
第二阶段使用在线更新,如果这样做可以减少距离的总和,那么将单独重新分配点,并且在每次重新分配后重新计算聚类质心。在此阶段的每个迭代包含一次遍历所有点。这个相位收敛到一个局部最小值,尽管可能有其他具有更小的总距离和的局部最小值。一般来说,寻找全局最小值是通过穷尽地选择起始点来解决的,但是使用几个随机起始点的重复通常会得到一个全局最小值的解。
如果启用
UseParallel选择权选择权和复制> 1,然后每个工蜂并行选择种子和集群。
工具书类
亚瑟,大卫和塞吉·瓦西里维茨基。" K-means++:小心播种的好处"SODA ' 07:第十八届ACM-SIAM年度离散算法研讨会论文集.2007年,页1027 - 1035。
[2] Lloyd, Stuart P. < PCM中的最小二乘量化>IEEE信息理论汇刊1982年第28卷,第129-137页。
[3] 塞伯,G.A.F。多变量观测.John Wiley & Sons, Inc., 1984。
[4] 斯帕特,H。聚类剖析与分析:理论,FORTRAN程序,实例.J.戈德施密特(J. Goldschmidt)翻译。纽约:霍尔斯特德出版社,1985年。
扩展能力
另请参阅
您还可以从以下列表中选择网站:
