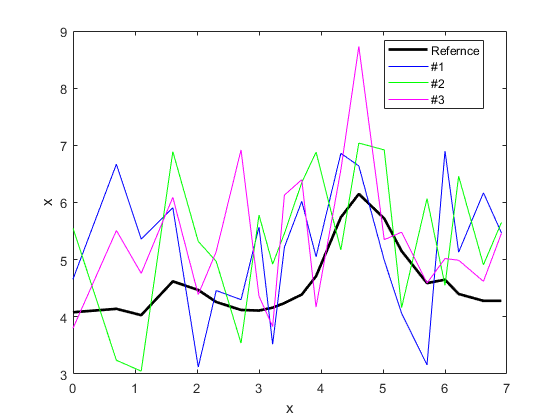
x = [0, 0.7, 1.1, 1.61, 2.02, 2.31, 2.71,, 3.22, 3.41,…
3.69,3.92,4.32,4.61,5.02,5.3,5.71,6,6.22,…
y_ref = (4.08, 4.14, 4.03, 4.62, 4.47, 4.26, 4.12, 4.11,…
4.16,4.24,4.39,4.71,5.74,6.15,5.72,5.15,…
4.59,4.65,4.4,4.28,4.28);
y_raw1 = (4.66, 6.67, 5.36, 5.91, 3.12, 4.46, 4.3, 5.57,…
3.52,5.22,6.02,5.05,6.86,6.64,4.99,4.06,…
3.16,6.9,5.13,6.17,5.47);
y_raw2 = (5.55, 3.24, 3.05, 6.89, 5.32, 4.97, 3.54, 5.78,…
4.92,5.46,6.35,6.88,5.17,7.04,6.92,4.16,…
6.07,4.55,6.46,4.91,5.65);
y_raw3 = (3.8, 5.51, 4.76, 6.09, 4.39, 5.14, 6.92, 4.36,…
3.83,6.13,6.4,4.17,6.57,8.73,5.35,5.48,…
4.59,5.02,4.99,4.62,5.46);
情节(x, y_ref,“k”,“线宽”2,“DisplayName的”,“参考”)
情节(x, y_raw1,“b”,“DisplayName的”,“# 1”)
情节(x, y_raw2,‘g’,“DisplayName的”,“2号”)
情节(x, y_raw3,“米”,“DisplayName的”,“# 3”)
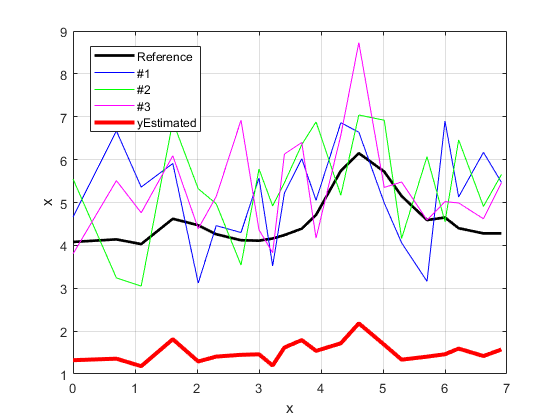
scaleFactors = [y_raw1;y_raw2;y_raw3]。“\ y_ref (:)
yEstimated = scaleFactors (1) * y_raw1 + scaleFactors (2) * y_raw2 + scaleFactors (3) * y_raw3;
情节(x, yEstimated,的r -,“线宽”3,“DisplayName的”,“yEstimated”);
tPredictions =表(y_raw1 (:), y_raw2 (:), y_raw3 (:))