textrankScores
描述
例子
文件的重要性
创建一个标记化文档数组。
STR = [敏捷的棕色狐狸跳过了懒惰的狗。“敏捷的棕色狐狸跳过了懒惰的狗。”懒狗坐在那里什么也不做“其他动物坐在那里看着”];documents = tokenizedDocument(str)
9个token:敏捷的棕色狐狸跳过了懒惰的狗9个token:敏捷的棕色狐狸跳过了懒惰的狗8个token:懒惰的狗坐在那里什么也没做6个token:其他动物坐在那里看着
计算TextRank分数。
分数= textrankScores(文档);
在柱状图中可视化分数。
图表栏(scores)“文档”) ylabel (“分数”)标题(“TextRank分数”)
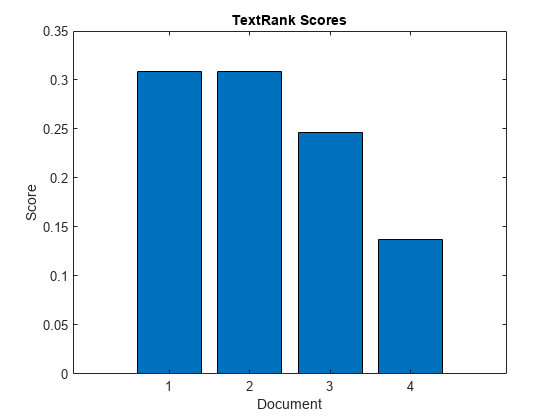
使用词汇袋模型的分数
中的文本数据创建单词袋模型sonnets.csv.
文件名=“sonnets.csv”;TBL =可读(文件名,“TextType”,“字符串”);textData = tbl.十四行诗;documents = tokenizedDocument(textData);bag = bagOfWords(文档)
词汇:["来自" "最美丽的" "生物" "我们" "渴望" "增加" "那" "因此" "美" "玫瑰" "可能" "永远" "死亡" "但是" "作为" " "成熟" "应该" "由" "时间"…NumWords: 3527 NumDocuments: 154
计算TextRank分数。
分数= textrankScores(包);
在柱状图中可视化分数。
图表栏(scores)“文档”) ylabel (“分数”)标题(“TextRank分数”)
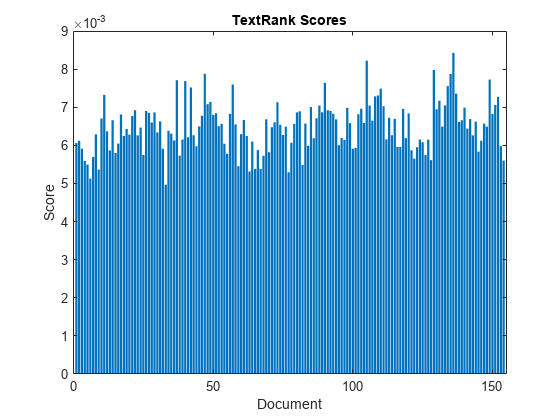
输入参数
输出参数
参考文献
Mihalcea, Rada和Paul Tarau。“Textrank:为文本带来秩序。”在2004年自然语言处理经验方法会议论文集,第404-411页。2004.
版本历史
R2020a中引入
您也可以从以下列表中选择一个网站: