転移学習 (迁移学习)とは、あるタスク向けに学習したモデルを、類似したタスクを実行するモデルの開始点として使用するディープラーニングの手法です。転移学習によるネットワークの更新と再学習は通常、ゼロからネットワークを学習させるよりもはるかに高速で簡単です。この手法は、物体検出や画像認識、音声認識などのアプリケーションで一般的に使用されています
転移学習が広く利用されている理由は次のとおりです。
- 大規模なデータセットで既に学習済みの一般的なモデルを再利用することで、ラベル付けされたデータが少なくてもモデルの学習を行うことができる。
- 学習時間を短縮し、コンピューティング リソースを削減できる。転移学習では、重みをゼロから学習させる必要はありません。事前学習済みのモデルは、以前の学習に基づき、既に重みの学習を行っているためです。
- ディープラーニングの研究コミュニティによって開発されたモデルアーキテクチャを活用できる (谷歌网や ResNetなどの広く利用されているアーキテクチャを含む)。
転移学習向け事前学習済みモデル
転移学習の中心となるのは、事前学習済みのディープラーニングモデルです。このモデルは、ディープラーニングの研究者によって構築されており、学習には、数千または数百万のサンプル画像が使用されています。
利用可能な事前学習済みモデルは多数ありますが、各モデルに次の考慮すべきメリットとデメリットがあります。
- サイズ: そのモデルにメモリはどのくらい必要か?モデルのサイズの重要性は、展開先や用途によって異なります。組み込みハードウェアとデスクトップのどちらで実行するのでしょうか?ネットワークのサイズは,低メモリシステムに展開する場合に特に重要です。
- 精度: 再学習前のモデル性能はどの程度か?通常ImageNet(100年万枚の画像と1000個のクラスの画像を含む一般的なデータセット)で良好な性能をもつモデルは,同じような新しいタスクでも良好に機能する可能性が高くなります。ただし,ImageNetの精度スコアが低くても,必ずしもすべてのタスクでモデルの性能が低いとは限りません。
- 予測速度:新しい入力に対するモデルの予測速度はどのくらいか吗?予測速度は、ハードウェアやバッチサイズなど、その他のディープラーニングによって異なりますが、速度は選択したモデルのアーキテクチャやモデルのサイズによっても異なります。
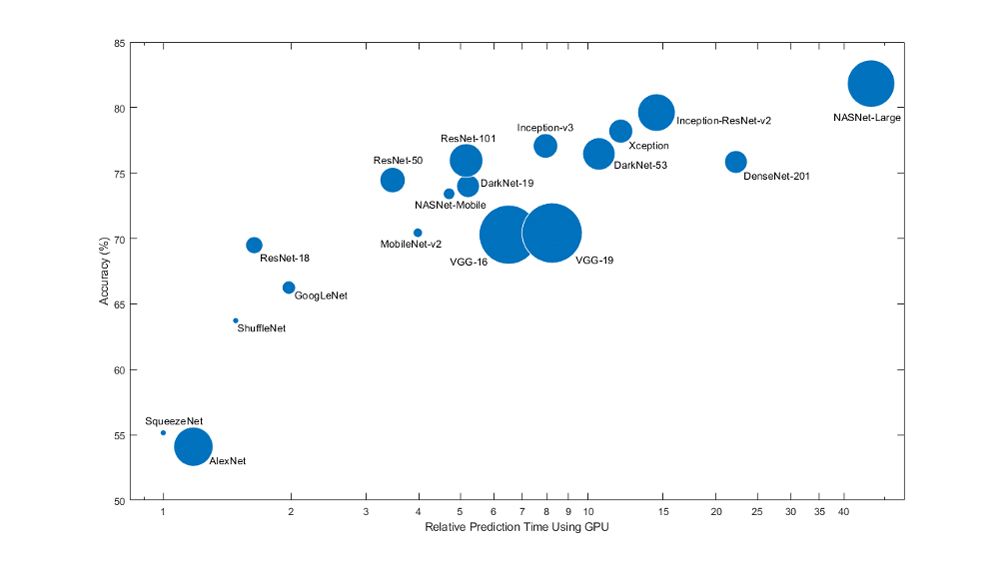
よく利用される事前学習済みネットワークのモデルのサイズや速度,精度の比較。
MATLABおよび 深度学习工具箱を使用すると、最新の研究で得られた事前学習済みのネットワークに 1.行のコードでアクセスできます。このツールボックスには、転移学習プロジェクトに適したネットワークを選択するためのガイダンスも用意されています。
転移学習アプリケーションに最適なモデルを見つけるには吗?
多くの転移学習モデルの中から選択するため、関連するトレードオフと特定のプロジェクトの全体的な目的に留意することが重要です。たとえば、比較的精度の低いネットワークの方が、新しいディープラーニング タスクに最適である場合があります。さまざまなモデルを試して、お使いのアプリケーションに最適なモデルを見つけることをお勧めします。
入門向けのシンプルなモデル。シンプルなモデル (例: AlexNet、GoogLeNet、VGG-16、VGG-19)は、迅速に反復処理を行い、さまざまなデータ前処理のステップや学習オプションを使用して試すことができます。適切に機能する設定が分かったら、さらに精度が高いネットワークで試し、結果が改善されるかどうかを確認します。
軽量で計算効率に優れたモデル。展開環境でモデルサイズに制限がある場合には、挤压网や MobileNet-v2、ShuffleNetがお勧めです。
ディープ ネットワーク デザイナーを使用すると、プロジェクト向けに事前学習済みのさまざまなモデルを迅速に評価できるだけでなく、さまざまなモデルアーキテクチャ間のトレードオフに対する理解を深めることができます。
転移学習ワークフロー
転移学習のアーキテクチャやアプリケーションにはさまざまな種類がありますが、ほとんどの転移学習ワークフローは共通の手順に沿って行われています。
- 事前学習済みモデルを選択する。初めは、比較的シンプルなモデルを選ぶことをお勧めします。この例では、水壶を使用しています。水壶は、1,000 個のオブジェクトカテゴリを分類するように学習されている 22層の深さの一般的なネットワークです。

- 最終層を置き換える。新しい画像とクラスのセットを分類するようにネットワークの再学習を行うには、水壶モデルの最終層を置き換えます。最終的な全結合層は、新しいクラスの数と同じ数のノードを含むように修正され、新しい分類層が追加されます。これにより、ソフトマックス層によって計算された確率 (尤度) に基づき、出力が生成されます。
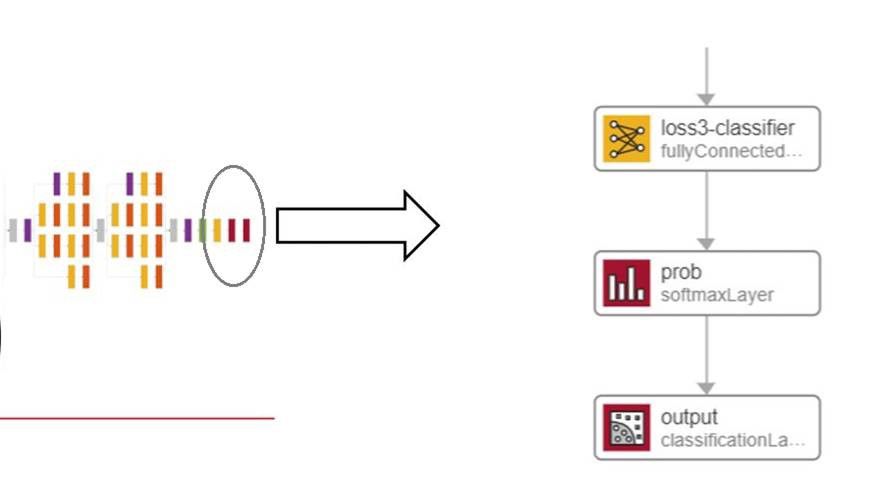
- 層を修正すると、最終的な全結合層でネットワークが学習するクラスの新しい数が指定され、分類層で利用可能な新しい出力カテゴリの出力が決まります。たとえば、水壶は元々 1,000 のカテゴリで学習されていましたが、最終層を置き換えることで、関心のあるオブジェクトの 5.つ (または他の任意の数) のカテゴリのみを分類するように再学習させることができます。
- 重みを凍結する (任意)。ネットワークの初期の層の重みを凍結するには、その層の学習率をゼロに設定します。学習中は、凍結された層のパラメーターは更新されないため、ネットワークの学習を大幅に高速化できます。新しいデータセットが小さい場合は、重みを凍結することで、新しいデータセットに対するネットワークの過適合を防ぐこともできます。
- モデルの再学習を行う。再学習では,新しい画像やカテゴリに関連する特徴を学習して識別するようにネットワークを更新します。通常,再学習で必要なデータは,ゼロからモデルを学習させる場合よりも少なくて済みます。
- ネットワーク精度を予測および評価する。モデルの再学習が完了したら、新しい画像を分類し、ネットワークの性能を評価できるようになります。
ゼロから学習するか,転移学習を使用するか吗?
ディープラーニングでは、ゼロからモデルを学習する方法と、転移学習の 2.つの手法が一般的に使用されています。
既存のモデルを使用できない特殊なタスクには、ゼロからモデルを開発し学習を行う方法が適しています。この手法のデメリットは、正確な結果を得るために通常、膨大なデータが必要になるということです。たとえば、テキスト解析を行っている場合に、テキスト解析に事前学習済みのモデルは利用できないが、利用できるデータサンプルが多数あるというときは、ゼロからモデルを開発することが最善の手法であると言えます。
転移学習は、物体認識などのタスクに有益であり、さまざまな事前学習済みモデルが広く利用されています。たとえば、花の画像を分類する必要があり、利用できる花の画像の数が限られている場合は、阿列克斯内特ネットワークから重みと層を転移し、最終分類層を置き換えて、お手持ちの画像でモデルの再学習を行います。
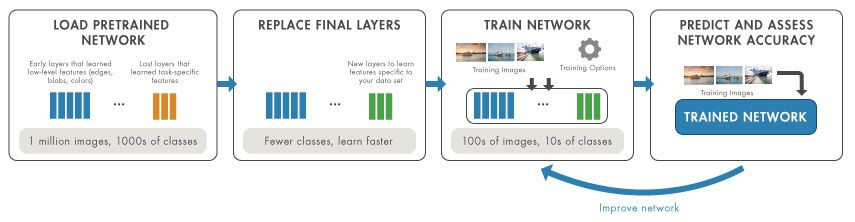
転移学習ワークフロー:ネットワークの読み込み,層の置き換え,ネットワークの学習,精度の評価。
このようなケースでは、転移学習を使用することで、モデルの学習時間を短縮しながら精度を高めることができます。

ゼロからの学習と転移学習のネットワーク性能 (精度) の比較。
転移学習への対話型アプローチ
ディープネットワークデザイナーを使用すると,転移学習ワークフロー全体 (事前学習済みモデルのインポート、最終層の変更、新しいデータを使用したネットワークの再学習など) を対話的に完了できます。コードの記述はほとんど、または一切必要ありません。


